[Kaggle 데이터분석] 월드컵 경기 데이터의 다양한 속성 분석해보기! 실습!
지금까지 학습한 Pandas와 Numpy 등의 내용을 바탕으로
월드컵 경기 데이터의 다양한 속성들을 확인해보고 그래프로 시각화해보자

1. 데이터 분석이란?
데이터 분석은 주어진 자료를 가공하여 원하는 정보와 결론을 얻어내는 일련의 처리 과정을 의미하며, 데이터 분석은 대개 아래의 단계로 이루어진다.

1) 주제 선정
어떤 데이터를 선정할 지, 데이터에서 어떤 가설을 세우고 분석을 시작할 지, 어떤 결론을 원하는 지 등 데이터 분석의 목적을 세운다.
2) 데이터 구조 파악
데이터를 분석하기 위해서, 데이터가 저장된 형태와 자료형, 변수 이름 등을 미리 파악해야 한다. 또는 데이터 프레임에 통계량 함수를 적용하여, 데이터의 분포도나 성향 등을 파악할 수 있다.
3) 데이터 전처리
데이터를 분석하기 전, 필요한 변수만을 추출하거나 기존의 변수로 새로운 변수를 계산하여 만들기도 한다. 데이터의 결측값(Null)과 이상값이 있다면, 이 단계에서 올바르게 제거 혹은 수정해야 데이터 분석 결과를 올바르게 확인할 수 있다.
4) 데이터 분석
주제 선정 단계에서 세운 가설을 numpy, pandas 등으로 데이터를 연산, 가공하여 가설을 입증하거나 원하는 정보를 얻어내는 것을 "구현" 하는 단계라고 한다. 얻어낸 정보를 효과적으로 보여주기 위해 시각화를 하기도 한다.
2. 월드컵 데이터 설명
1) DataSet (WorldCups.csv)
실습에서 주어지는 월드컵 데이터 셋인 'WorldCups.csv'의 칼럼은 아래와 같다.
(출처 : https://www.kaggle.com/abecklas/fifa-world-cup)

2) DataSet (WorldCupMatches.csv)
실습에서 주어지는 월드컵 데이터 셋 'WorldCupMatches.csv"의 칼럼은 아래와 같다.
(출처 : https://www.kaggle.com/abecklas/fifa-world-cup)

3. 역대 월드컵의 관중 수 출력하기
Q1) 'WorldCups.csv' 파일을 pandas의 DataFrame으로 만들어보세요
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# csv 파일 불러와서 DataFrame으로 만들기 (디렉토리는 가상)
world_cups = pd.read_csv("WorldCups.csv")
print(world_cups)
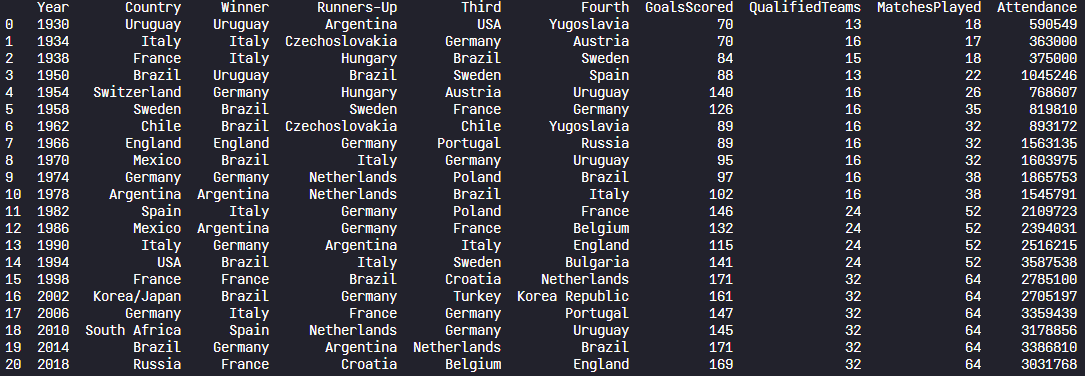
위의 출력된 사진과 같이 월드컵이 개최된 연도/국가를 포함하여 여러 칼럼들에 대한 정보들이 있는 것을 확인할 수 있다.
Q2) 만든 데이터 프레임의 칼럼 중 'Year'와 'Attendance' 칼럼만 추출하여 출력해보세요
→ Year : 개최연도, Attendance : 총 관중 수
→ 역대 월드컵의 관중 수 제대로 출력되었는지 확인
# Year와 Attendance 컬럼만 추출
world_cups = world_cups[['Year', 'Attendance']]
print(world_cups)

Q3) 지금까지 world_cups을 이용하여 확인한 역대 월드컵의 평균 관중 수를 그래프로 출력해보세요
# 역대 월드컵의 평균 관중 수 - 그래프로 출력
plt.plot(world_cups['Year'], world_cups['Attendance'], marker='o', color='black')

Line 그래프의 x축은 world_cups 데이터프레임 내 'Year' 컬럼, y축은 'Attendance'로 설정하고
marker는 'o'으로 색상은 검은색으로 지정하여 그래프 출력
4. 역대 월드컵의 경기당 득점 수
역대 월드컵 중 가장 공격적인 축구가 펼쳐진 대회가 언제인지 알기 위해 월드컵 경기당 득점 수를 계산하려고 한다. 주어진 데이터를 통해 월드컵 대회들의 연도, 경기 수, 득점 수, 경기당 득점수 출력해보자
Q1) WorldCups.csv 파일을 pandas의 DataFrame으로 만들고, 그 중 Year, GoalsScored, MatchesPlayed 칼럼만 추출해보세요. (GoalsScored : 총 득점 수, MatchesPlayed : 총 경기 수)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
world_cups = pd.read_csv("WorldCups.csv")
world_cups = world_cups[['Year', 'GoalsScored', 'MatchesPlayed']]
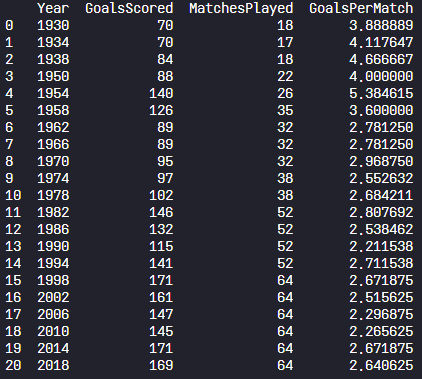
print(world_cups)

Q2) 데이터 프레임에 경기당 득점 수를 의미하는 새로운 칼럼 'GoalsPerMatch'를 추가하시오
→ GoalsPerMatch = GoalsScored / MatchesPlayed
world_cups['GoalsPerMatch'] = world_cups['GoalsScored'] / world_cups['MatchesPlayed']
Q3) world_cups를 이용하여 역대 월드컵의 경기 수와 득점 수를 그래프로 출력하시오
# 첫번째 그래프 출력
fig, axes = plt.subplots(2, 1, figsize=(4,8))
axes[0].bar(x=world_cups['Year'], height=word_cups['GoalsScored'], color='grey', label='goals')
axes[0].plot(world_cups['Year'], world_cups['MatchesPlayed'], marker='o', color='blue', label='matches')
axes[0].legend(loc='upper left')
# 두번째 그래프 출력
axes[1].grid(True)
axes[1].plot(world_cups['Year'], world_cups['GoalsPerMatch'], marker='o', color='red', label='goals_per_matches')
axes[1].legend(loc='lower left')
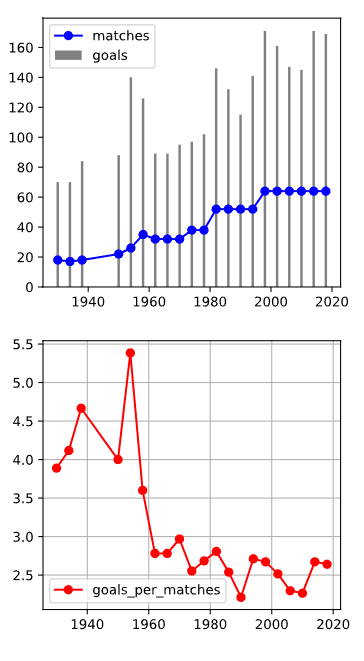
- axes[0].bar(x=world_cups['Year'], height=world_cups['GoalsScored'], color='grey', label='goals')
: matplotlib의 bar() 함수를 통해 위의 그래프 영역에 총 득점 수(GoalsScored)를 나타내는 막대 그래프 출력
- axes[0].plot(world_cups['Year'], world_cups['MatchesPlayed'], marker='o', color='blue', label='matches')
: 위의 그래프 영역에 plot() 함수를 통해 총 경기 수(MatchesPlayed)를 파란색으로 시각화
- axes[1].plot(world_cups['Year'], world_cups['GoalsPerMatch'], marker='o', color='red', label='goals_per_matches')
: 아래 그래프 영역에서는 plot() 함수를 통해 경기당 골 수(GoalsPerMatch)를 빨간색으로 표현
5. 월드컵 매치 데이터 전처리
저장된 데이터 중 이상값, 결측값, 변경되어야 하는 값이 있을 경우 정제하는 과정이 필요하다.
→ 이를 '데이터 전처리' 과정이라고 한다.
WorldCupMatches.csv 파일에는 일부 이상값이 있기 때문에 전처리를 해보도록 하자
Q1) 데이터 전처리를 위해 데이터프레임의 일부 값을 replace() 함수를 사용해서 교체하시오
# WorldCupMatches.csv 파일 불러오기
world_cups_matches = pd.read_csv("WorldCupMatches.csv")
# 일부값을 replace 함수로 교체
world_cups_matches = world_cups_matches.replace('Germany FR', 'Germany')
world_cups_matches = world_cups_matches.replace('Soviet Union', 'Russia')
- Germany FR은 통일 이전의 서독을 나타내는 단어로 'Germany'로 통일
- Soviet Union → Russia로 구소련을 러시아로 교체
Q2) 데이터 프레임에 중복된 데이터가 얼마나 있는지 확인하고 제거하시오
# duplicated() 함수로 중복된 데이터 확인
dupli = world_cup_matches.duplicated()
print(len(dupli[dupli==True])) # 16
# 중복된 데이터가 16개로 확인되어 모두 제거
world_cups_matches = world_cups_matches.drop_duplicates()
# 중복값 확인 및 처리
- 중복 여부 확인 : DataFrame.duplicated()
→ True : 중복 / False : 중복 X
- 중복값 처리 : DataFrame.drop_duplicates()
→ unique한 1개의 key만 남기고 나머지 중복값들은 제거
6. 국가별 득점 수 구하기
1) 가장 많은 골을 넣은 국가는 어디?
역대 월드컵 경기를 통틀어 가장 많은 골을 넣은 국가가 어디였는지 출력해보자
'WorldCupMatches.csv' 파일에 역대 월드컵 경기의 기록이 담겨있고, 각 국가들이 기록한 득점 수를 내림차순으로 정렬한 결과를 출력하는 것이 목표! 아래의 순서대로 수행해보자
Q1) 전처리를 거친 데이터프레임에서 '홈 팀 득점'은 home 데이터 프레임과, '어웨이 팀 득점'은 away로 만들어보자
Q2) concat 메소드를 이용하여 home, away 데이터프레임을 하나로 합치고, 'goal_per_country'라는 새로운 데이터프레임에 저장 (결측값 제거를 위해 fillna() 함수 적용)
Q3) 'goal_per_country' 데이터프레임에 새로운 컬럼인 "Goals"을 만들자
→ Goals = Home 팀의 득점 + Away 팀의 득점
Q4) 'goal_per_country'에서 'Goals' 컬럼만 추출하고, 내림차순으로 정렬하시오
Q5) 지정된 값의 dtype을 정수형으로 바꾸어서 값을 확인하자
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import preprocess
# 이전까지 전처리한 내용이 반영된 데이터
world_cups_matches = preprocess.world_cups_matches
# Q1) home, away 각각 그룹으로 묶고 저장
home = world_cups_matches.groupby(['Home Team Name'])['Home Team Goals'].sum()
away = world_cups_matches.groupby(['Away Team Name'])['Away Team Goals'].sum()
# Q2) home, away 데이터프레임을 하나로 합치고 새로운 데이터프레임(goal_per_country)으로 저장
goal_per_country = pd.concat([home, away], axis=1, sort=True).fillna(0)
# Q3) 'goal_per_country' 데이터프레임에 새로운 컬럼(Goals) 생성
goal_per_country["Goals"] = goal_per_country["Home Team Goals"] + goal_per_country["Away Team Goals"]\
# Q4) 'goal_per_country'에서 Goals 컬럼만 추출하고 내림차순 정렬
goal_per_country = goal_per_country["Goals"].sort_values(ascending = False)
# Q5) 데이터타입을 정수형으로 변경
goal_per_country = goal_per_country.astype(int)
print(goal_per_country)

- home = world_cups_matches.groupby(['Home Team Name'])['Home Team Goals'].sum()
away = world_cups_matches.groupby(['Away Team Name'])['Away Team Goals'].sum()
: 'Home Team Name'으로 그룹을 묶고, 'Home Team Goals' 칼럼을 추출하여 'home'에 저장 (away도 동일)
- goal_per_country = pd.concat([home, away], axis=1, sort=True).fillna(0)
: concat 메소드를 이용하여 home, away 데이터프레임 합치기
→ fillna() 함수를 통해 결측값 제거
- goal_per_country["Goals"] = goal_per_country["Home Team Goals"] + goal_per_country["Away Team Goals"]
: 새로운 컬럼(Goals)을 만들고 Home과 Away Team의 Goals을 덧셈으로 연산한 값 입력
- goal_per_country = goal_per_country["Goals"].sort_values(ascending = False)
: 'goal_per_country'에서 Goals 컬럼만 추출하고 내림차순으로 정렬
→ 이때, goal_per_country는 Series 데이터
2) 월드컵 국가별 득점 상위 Top10 그래프 출력
1)번에서 작성한 코드를 바탕으로 월드컵 국가별 득점 수에 대해 상위 10개의 국가를 출력해보자
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import preprocess
# 위에 전처리한 데이터를 'goal_per_country'에 저장
goal_per_country = preprocess.goal_per_country
# 국가별 득점 수 데이터프레임의 상위 10개만 추출
goal_per_country = goal_per_country[:10]
# x, y값 저장
x = goal_per_country.index
y = goal_per_country.values
# 그래프 그리기
fig, ax = plt.subplots()
ax.bar(x, y, width = 0.5)
# x축 항목 이름 지정 + 30도 회전
plt.xticks(x, rotation=30)
plt.tight_layout()

- plt.xticks(x, rotation=30)
: x축에 들어가는 index 항목인 국가명이 서로 겹칠 수 있기 때문에, rotation 옵션 적용
- plt.tight_layout()
: tight_layout() 함수를 사용하면, 글자가 넘쳐서 잘리는 현상을 방지할 수 있다.
# Tip!
- matplotlib의 pyplot 객체뿐 아니라, Series 데이터에서도 직접 plot 함수를 호출할 수 있다.
즉, 아래와 같이 코드를 작성할 수 있다.
→ goal_per_country[:10].plot(x=goal_per_country.index, y=goal_per_country.values, kind="bar", figsize=(12, 12), fontsize=14)
7. 2014 월드컵 다득점 국가 순위
1) 월드컵에 참가한 국가별 기록한 득점 수 출력
2014년 브라질 월드컵에서 각 국가가 기록한 득점 수를 내림차순으로 정렬하여 출력해보자 (아래 순서대로)
Q1) 주어진 데이터프레임에서 마스킹 연산을 이용하여 Year가 2014인 것들을 추출
Q2) 2014년 월드컵 경기 데이터 중, 홈 팀의 골 수와 원정 팀의 골 수를 각각 계산
→ 주어진 데이터로 인해 홈/원정팀을 각각 구한 뒤에 합쳐야 함
Q3) 홈 팀의 득점 수와 원정 팀의 득점 수를 하나의 데이터로 합치기
Q4) 홈/원정 팀 골 수를 합한 새로운 컬럼(=goals)을 만들고, 기존의 컬럼은 drop() 함수로 삭제
Q5) 저장된 값을 정수로 변환
Q6) 데이터프레임을 내림차순으로 정렬하고, 올바른 값이 출력되는지 확인
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import preprocess
# 이전까지 전처리 작업된 데이터 불러오기
world_cups_matches = preprocess.world_cups_matches
# Q1) 데이터프레임에서 Year가 2014인 것들만 추출
world_cups_matches = world_cups_matches[world_cups_matches['Year']==2014]
# Q2) Home팀의 골 수와 Away팀의 골 수 각각 계산
home_team_goal = world_cups_matches.groupby(['Home Team Name'])['Home Team Goals'].sum()
away_team_goal = world_cups_matches.groupby(['Away Team Name'])['Away Team Goals'].sum()
# Q3) Home, Away팀의 득점 수를 하나의 데이터로 합치기(concat) + 결측값 처리(fillna)
team_goal_2014 = pd.concat([home_team_goal, away_team_goal], axis=1).fillna(0)
# Q4) 새로운 컬럼(goals)를 만들고 기존 컬럼은 삭제(drop)
team_goal_2014['goals'] = team_goal_2014['Home Team Goals'] + team_goal_2014['Away Team Goals']
team_goal_2014 = team_goal_2014.drop(['Home Team Goals', 'Away Team Goals'], axis=1)
# Q5) 저장된 값을 정수로 반환
team_goal_2014.astype('int')
# Q6) 데이터프레임을 내림차순 정렬하고 올바른 값 출력 확인
team_goal_2014 = team_goal_2014['goals'].sort_values(ascending=False)
print(team_goal_2014)
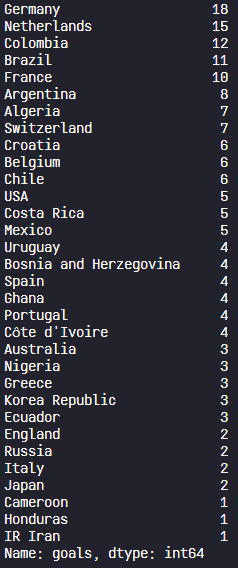
- home_team_goal = world_cups_matches.groupby(['Home Team Name'])['Home Team Goals'].sum()
: 'Home Team Name'을 그룹으로 묶어서 'Home Team Goals'의 합계를 구하고 'home_team_goal' 변수에 저장
→ Away Team도 동일 원리
- team_goal_2014 = pd.concat([home_team_goal, away_team_goal], axis=1).fillna(0)
: 홈/원정팀의 득점 수를 하나의 데이터로 합치는 코드
→ 이 때, 결측값을 없애기 위해 fillna() 함수 적용. 결측값이 있다면 0골이므로 '0'으로 대체
- team_goal_2014 = team_goal_2014.drop(['Home Team Goals', 'Away Team Goals'], axis=1)
: 기존 컬럼(Home, Away Team Goal)은 drop() 함수를 이용해서 제거
- team_goal_2014 = team_goal_2014['goals'].sort_values(ascending=False)
: 데이터프레임을 내림차순으로 정렬
2) 2014 월드컵 국가별 득점수 그래프 출력
'WorldCupMatches.csv'에 역대 월드컵 경기에 대한 데이터가 담겨있고, 이를 변수 'world_cups_matches'에 데이트프레임 형식으로 저장된 상태이다. 변수 'world_cups_matches'를 이용하여 국가별 득점 수를 그래프로 그려보자
이전까지 전처리 및 출력한 2014년 월드컵에 참여한 국가별 득점 수가 담겨진 'team_goal_2014' 활용
import matplotlib.pyplot as plt
import preprocess
# 이전까지 전처리한 '2014 월드컵 국가별 득점 수' 데이터 사용
team_goal_2014 = preprocess.team_goal_2014
# 1) plot 함수로 그래프 출력
team_goal_2014.plot(
x=team_goal_2014.index,
y=team_goal_2014.values,
kind="bar",
figsize=(12, 12),
fontsize=14
)
# 2) pyplot 개체로 그래프 출력
fig, ax = plt.subplots()
ax.bar(team_goal_2014.index, team_goal_2014.values)
plt.xticks(rotation = 90)
plt.tight_layout()

1번, 2번 코드를 통해 이전까지의 실습으로 처리한 'team_goal_2014' 데이터에서 국가명을 x축, 득점 수를 y축으로 하여 각각 plot함수와 pyplot 객체로 그래프를 그린 것이다.
- 1번 코드는 plot 함수로 막대(bar) 그래프 출력
- 2번 코드는 matplotlib의 pyplot 객체로 그래프를 그린 코드
8. 월드컵 4강 이상 성적 집계하기
주어진 'WorldCups.csv' 파일에는 역대 월드컵 대회의 기록이 담겨져 있고, 각 변수별 의미와 예시는 아래와 같다. 이를 통해 각 국가들의 4강 이상 월드컵 성적을 집계하여 그래프로 시각화해보자.
아래의 순서대로 수행! (ex, 각 국가들을 우승 횟수, 준우승 횟수, 3위 횟수, 4위 횟수 순서대로 내림차순 정렬)
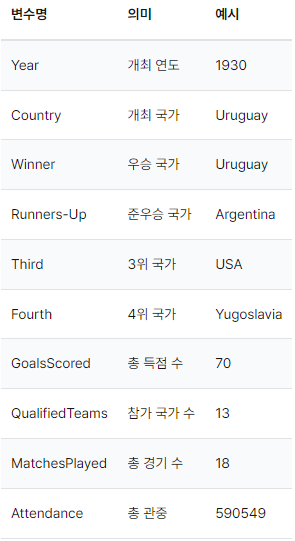
step1) DataFrame(WorldCups.csv) 불러오기 및 형태 확인
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# WorldCups.csv 파일 불러오기 (데이터프레임 형태 확인)
world_cups = pd.read_csv("WorldCups.csv")
print(world_cups)

위 실행결과와 같이 연도별 월드컵에 1~4위를 한 국가와 각 데이터들이 담겨져있다.
→ 데이터프레임을 'world_cups'에 저장
step2) 1~4위 국가 추출 후 변수 할당
데이터프레임(WorldCups.csv)에서 역대 대회 1~4위 국가를 추출하여 각각 변수 winner, runners_up, third, fourth에 저장
winner = world_cups["Winner"]
runners_up = world_cups["Runners-Up"
third = world_cups["Third"]
fourth = world_cups["Fourth"]
print(winner)

DataFrame에서 역대 대회 1위부터 4위를 한 국가들을 추출하여 각각 변수에 저장 그 중 'winner' Series 데이터를 확인해보면, 위 사진과 같이 DataFrame에서 역대 우승(1위)를 한 국가들의 정보가 담겨져있다. 2~4위에 해당하는 변수도 동일하게 적용
step3) 각 Series 데이터에 저장된 값의 수 count (value_counts)
1~4위에 해당하는 Series 데이터에 저장된 값의 수를 세고 저장한다. (value_counts 함수 사용)
winner_count = pd.Series(winner.value_counts())
runners_up_count = pd.Series(runners_up.value_counts())
third_count = pd.Series(third.value_counts())
fourth_count = pd.Series(fourth.value_counts())
print(winner_count)
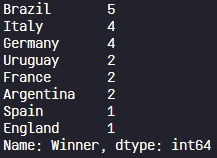
value_counts() 함수를 이용하여 각 Series 데이터에 저장된 값의 수를 세고 저장한다.
이 과정을 거치면 국가별 1~4위의 횟수가 각각 저장된 데이터가 생성되고, 그 중 'winner_count' 데이터를 확인해보면 위 사진에서 볼 수 있듯이 각 국가별 우승(1위)한 횟수를 확인할 수 있다. 국가별 2~4위를 했던 횟수도 동일하게 적용
step4) Series 데이터들을 하나의 데이터 프레임으로 합치기
step3단계에서 수행한 1~4위 횟수 데이터를 하나의 데이터 프레임(ranks)으로 합치기
ranks = pd.DataFrame({
"Winner" : winner_count,
"Runners_up" : runners_up_count,
"Third" : third_count,
"Fourth" : fourth_count
})
print(ranks)

step3에서 생성한 Series 데이터들을 모아서 하나의 DataFrame으로 합친다. 'ranks'를 출력해보면 각 국가별 1~4위를 한 횟수를 확인할 수 있고, NaN값은 step5에서 처리
step5) 결측값 처리 및 정수형으로 변환
생성한 데이터프레임 내 결측값을 처리하고 정수형으로 설정
ranks = ranks.fillna(0).astype('int64')
print(ranks)
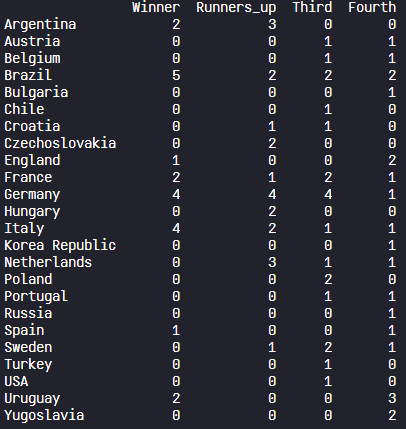
ranks에 있는 NaN값의 의미는 해당 국가에서 해당 순위를 기록한 적이 없다는 것으로 '0'으로 대체할 수 있다. 그리고 dtype은 int64 (정수형, 64비트)
step6) 데이터 내림차순 정렬
각 국가들을 1~4위 횟수의 순서대로 내림차순 정렬하여 출력하기 (보고 싶은 방법대로)
ranks = ranks.sort_values(['Winner', 'Runners_up', 'Third', 'Fourth'], ascending=False)
print(ranks)

각 국가들의 1~4위 횟수가 높은 순서대로 내림차순으로 정렬시킨다.
위의 사진에서 봤을 때도 잘 반영된 것을 확인할 수 있다.
step7) 그래프 시각화(4강 이상의 성적을 낸 국가들)
지금까지 확인했던 월드컵 4강 이상의 성적을 낸 국가들에 대한 데이터를 바탕으로 아래 막대(bar) 그래프로 출력해보자
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import preprocess
# 이전까지 전처리한 데이터 불러오기
ranks = preprocess.ranks
# x축에 그려질 막대그래프들의 위치
x = np.array(list(range(0, len(ranks))))
# 그래프 그리기
fig, ax = plt.subplots()
# x 위치에항목 이름으로 ranks.index(국가명)을 붙인다
plt.xticks(x, ranks.index, rotation=90)
plt.tight_layout()
# 4개의 막대그래프를 차례대로 그린다. (1 ~ 4위 국가)
ax.bar(x - 0.3, ranks['Winner'], color = 'gold', width = 0.2, label = 'Winner')
ax.bar(x - 0.1, ranks['Runners_Up'], color = 'silver', width = 0.2, label = 'Runners_Up')
ax.bar(x + 0.1, ranks['Third'], color = 'brown', width = 0.2, label = 'Third')
ax.bar(x + 0.3, ranks['Fourth'], color = 'black', width = 0.2, label = 'Fourth')
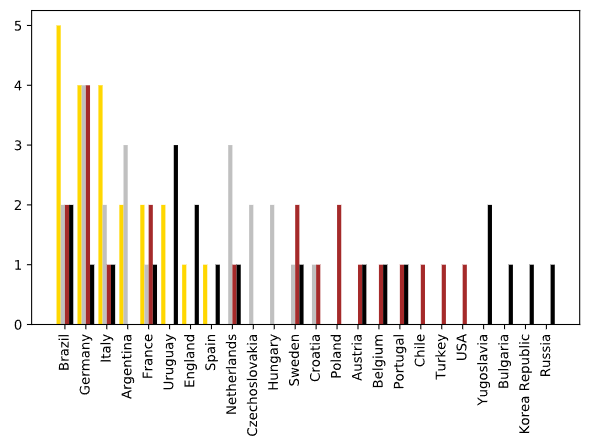
위의 코드는 matplotlib으로 그래프를 정교하게 그렸으며, 아래와 같이 직접 plot 함수를 호출한 코드이다.
ranks.plot(y=["Winner", "Runners_Up", "Third", "Fourth"],
kind="bar",
color=['gold', 'silver', 'brown', 'black'],
figsize=(15, 12),
fontsize=10,
width=0.8,
align='center')
plot 함수로 직접 호출한 코드는 matplotlib보다 간편하지만, 그래프 전체에 대한 섬세한 설정은 어렵다.
'Data Analyst > Basic Python' 카테고리의 다른 글
| [파이썬 통계] 데이터를 논리적 수치로 해석하는 법! (대표값, 퍼진정도 등) (0) | 2023.11.06 |
|---|---|
| [파이썬 확률 통계] 시각화를 통한 데이터 요약하는법! 이론과 실습! (2) | 2023.10.17 |
| Matplotlib 데이터 시각화, 꼭 알아야 할 이론부터 실습까지! 총정리! (0) | 2023.09.29 |
| Pandas 함수 활용법! - 조건검색, 함수로 데이터 처리 등 심화학습! (2) | 2023.09.26 |
| Pandas 기초부터 실습까지! Series와 DataFrame 다루는 법! (0) | 2023.09.06 |




댓글