Pandas 함수 활용법! - 조건검색, 함수로 데이터 처리 등 심화학습!
728x90
반응형
Pandas 함수 활용법을 실습을 통해 학습해보자
Pandas를 다루기 위한 다양한 도구들을 활용!

1. 조건으로 검색하기
1) masking 연산
Numpy array와 동일하게 masking 연산이 가능하다.
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
df["A"] < 0.5

- np.random.rand(5, 2), columns=["A", "B"]
: 0~1 사이의 실수 중 5개를 랜덤하게 추출하여 2차원으로 생성하며, column의 이름은 'A'와 'B'로 지정
- df["A"] < 0.5
: A column에 있는 Series 데이터가 0.5보다 작은 경우(=참) True, 클 경우(=거짓) False
2) 조건에 맞는 DataFrame row 추출
지정한 조건에 맞는 DataFrame row를 추출할 수 있다.
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"])
df[(df["A"] < 0.5) & (df["B"] > 0.3) ]
df.query("A < 0.5 and B > 0.3")

- df[(df["A"] < 0.5) & (df["B"] > 0.3) ]
: A column 중 0.5보다 작고 B column 중 0.3보다 큰 2가지 조건을 만족하는 데이터
→ 2가지 조건 위에 DataFrame masking을 적용해야 Series가 아닌 DataFrame 형태로 출력된다.
- df.query("A < 0.5 and B > 0.3")
: query() 메서드를 통해 위의 작업을 수행할 수 있다.
3) DataFrame 내 문자열 검색
문자열의 경우, 다른 방식으로 조건 검색이 가능하다.
아래와 같이 'Animal'과 'Name'이라는 Column이 있는 DataFrame이 있고, 'Cat'이 있는 데이터만 추출할려고 할때 아래와 같이 3가지 방법으로 가능하다.
# 1)
df["Animal"].str.contains("Cat")
# 2)
df["Animal"] = "Cat"
# 3)
df.Animal.str.match("Cat")

- df["Animal"].str.contains("Cat")
: DataFrame 내 'Animal' column에 있는 데이터를 문자열(str)로 보고, "Cat"라는 문자열이 포함하면 True, 포함하지 않으면 False로 출력
- df["Animal"] = "Cat"
: 위와 동일한 결과 출력
- df.Animal.str.match("Cat")
: df → Animal column → str(문자열) → "Cat"과 매칭되면 True, 그렇지 않으면 False 출력
2. 함수로 데이터 처리하기
1) apply() 를 이용한 데이터 가공/처리하기 (lamba)
복잡한 연산을 하기 위해서 어떤 데이터값을 받아서 가공하고, 그 가공된 값을 다시 데이터에 넣기 위해서는 함수로 만들어서 처리가 필요하다. → 이때 사용되는 함수가 apply()
아래 예시는 랜덤하게 'Num'이라는 column을 생성하고, 그 값을 제곱시켜서 'Square'라는 column을 DataFrame에 추가해보자.
df = pd.DataFrame(np.arange(5), columns=["Num"])
# 함수 선언. x값을 받아서 x의 제곱을 return
def square(x):
return x ** 2
# Num 컬럼에 위에 선언한 square() 적용 - 결과는 Series 형식
df["Num"].apply(square)
# Square column에 Num의 값들을 제곱해서 넣어준다.
df["Square"] = df["Num"].apply(square) 동일
# 바로 위이 코드를 lambda식으로 표현
df["Square"] = df.Num.apply(lambda x: x ** 2)

- df = pd.DataFrame(np.arange(5), columns=["Num"])
: np.arange(5)를 통해 0부터 4까지 데이터를 생성하고, column 이름은 'Num'으로 지정
- df["Num"].apply(square)
: DataFrame 중 'Num' column에 이미 선언한 square 함수 적용
→ apply() 함수 인자에 이미 선언한 함수를 넣어주면 된다.
→ 이때 index는 Num의 데이터값이고, value는 해당 값에 제곱을 한 결과값이 된다.
- df["Square"] = df["Num"].apply(square)
: 'Num' column에 square() 함수를 적용한 결과를 'Square'라는 column에 추가해서 저장하기
- df["Square"] = df.Num.apply(lambda x: x ** 2)
: lambda 표현식으로, Num column의 임의의 x값을 받아서 x의 제곱으로 return하고 그 값을 'Square' column에 추가
2) apply() 를 통한 데이터 다루는 예제
아래와 같이 전처리가 되지 않은 데이터들이 주어졌을 때, phone의 값을 실제로 전화를 걸 수 있는 숫자번호로 바꿔보자. → apply() 함수 사용
df = pd.DataFrame(columns=["phone"])
df.loc[0] = "010-1234-1235"
df.loc[1] = "공일공-일이삼사-1235"
df.loc[2] = "010.1234.일이삼오"
df.loc[3] = "공1공-1234-1이3오"
# 전처리한 데이터를 넣기 위한 column
df["preprocess_phone"] = ''

# 데이터 전처리를 하기 위한 함수 선언
def get_preprocess_phone(phone):
mapping_dict = {
"공": "0",
"일": "1",
"이": "2",
"삼": "3",
"사": "4",
"오": "5",
"-" : "",
"." : "",
}
for key, value in mapping_dict.items():
phone = phone.replace(key, value)
return phone
df["preprocess_phone"] = df["phone"].apply(get_preprocess_phone)
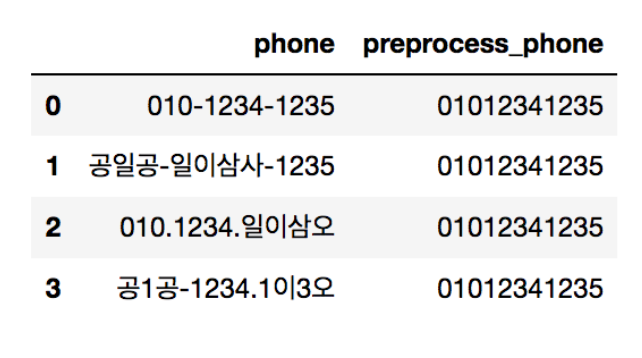
- mapping_dict { ~ } : 한글과 숫자를 key와 value 관계로 mapping
- for key, value in mapping_dict.itmes():
: .items() 하면 해당 딕셔너리의 key와 value가 나오면서 아래 반복문 수행
- phone = phone.replace(key, value)
: key와 value를 서로 바꿔준다. ex) 공 → 0, 일 → 1
- df["preprocess_phone"] = df["phone"].apply(get_preprocess_phone)
: 'phone' column의 데이터에 대해 'get preprocess_phone' 함수를 적용하며, 그 값을 'preprocess_phone' column에 추가
3) replace()를 이용한 데이터값 대체
특정 데이터값만 대체하고자 한다면, apply()가 아닌 replace() 함수로만 사용할 수 있다.
아래 예시는 'Sex'라는 column에 Male과 Female이라는 데이터가 들어있고, 이를 각각 숫자로 대체하고자 한다.
df.Sex.replace({"Male": 0, "Female": 1})
df.Sex.replace({"Male": 0, "Female": 1}, inplace=True)

위의 Column 데이터를 Male은 0, Female은 1로 대체 - replace() 사용
→ replace() 인자에 대체하고자 하는 데이터를 Dictionary 형태로 바꾸어서 넣어주면 된다.
- inplace = True
: 대체한 데이터를 Series 형태가 아닌 DataFrame로 표현하고자 할때
→ inplace 옵션을 넣지 않는다면, 'df["Sex"] = ~ ' 로 추가하면 DataFrame으로 나온다.
3. 그룹으로 묶기 (groupby, aggregate)
1) groupby를 통한 조건부 집계
간단한 집계가 아닌 조건부로 집계를 하고자 할 경우에 대해 학습하자. - groupby() 함수 사용
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1' : [1, 2, 3, 1, 2, 3],
'data2' : np.random.randint(0, 6, 0)})
# 데이터프레임(df)의 key 컬럼을 groupby 함수로 묶기
df.groupby('key')
# key로 묶은 후 합계 산출
df.groupby('key').sum()
# key와 data1을 기준으로 묶어서 합계 산출
df.groupby(['key', 'data1']).sum()

- df.groupby('key')
: 'key'값(=A, B, C)을 통해 각각 그룹별로 묶어둠. 아무 연산처리를 하지 않고, 그룹별로 지정만 상태
- df.groupby('key').sum()
: 위에서 묶인 상태의 그룹에서 sum() 수행
→ key값(= A, B, C)에 대해 data1과 data2의 합계(=sum) 연산
- df.groupby(['key', 'data1']).sum()
: key(=A, B, C)와 data1(=1, 2, 3)의 데이터로 데이터들을 묶고, sum() 연산 진행해서 data2 출력
→ 이처럼 groupby()는 여러 개의 데이터로 묶을 수 있다.
2) aggregate를 이용한 요약 통계량 산출
groupby를 통해서 집계를 한번에 계산할 수 있다. DataFrame에서 각 column마다 어떤 연산을 수행할지도 지정할 수 있어서 집계를 더 편하게 수행할 수 있다. - aggregate()
아래 예시에서 data1는 0~5, data2는 random값, key는 A, B, C로 이루어져있다.
# df를 'key' 컬럼으로 묶고, data1과 data2 각각 최솟값, 중앙값, 최댓값 연산
df.groupby('key').aggregate(['min', np.median, max])
# df를 'key' 컬럼으로 묶고, data1의 최솟값, data2의 합계 연산
df.groupby('key').aggregate({'data1': 'min', 'data2': np.sum})
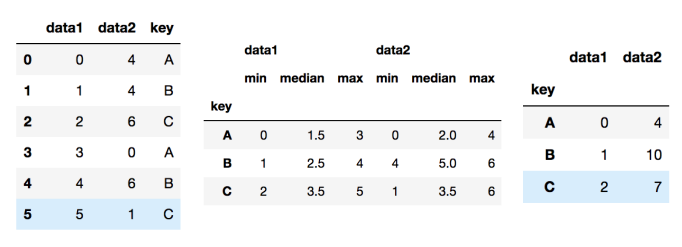
- df.groupby('key').aggregate(['min', np.median, max])
: 'key'값을 묶고 aggregate 연산 수행. 1번째는 최솟값, 2번째는 중앙값, 3번째는 최댓값
→ 'key'를 기준으로 data1과 data2가 각각 min, median, max값이 연산된다.
- df.groupby('key').aggregate({'data1': 'min', 'data2': np.sum})
: df의 'key'값을 묶고 aggregate 수행. data1에서 min값과 data2에서 np.sum 연산을 딕셔너리로 묶어서 수행
→ 이처럼 딕셔너리로 묶어서 연산을 할 경우, value로 설정한 연산만 수행
ex) data1 : min값만 연산 / data2 : np.sum만 연산
3) filter 연산 - 그룹속성으로 묶기
groupby를 통해서 그룹 속성을 기준으로 데이터 필터링이 필요할 경우 filter 연산 수행
def filter_by_mean(x):
return x['data2'].mean() > 3
df.groupby('key').mean()
# key별 data2의 평균이 3이 넘는 인덱스만 추출
df.groupby('key').filter(filter_by_mean)
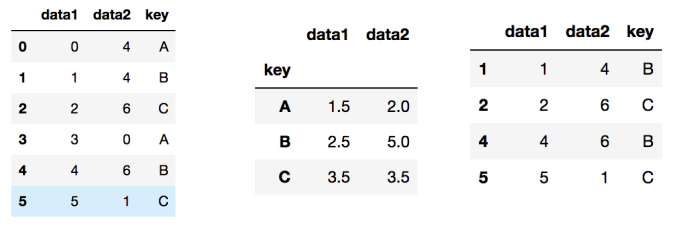
- filter_by_mean(x)
: data2의 값들 중 평균값(mean)이 3보다 큰 값들만 추출
→ x값을 받아서, 상응하는 data2값의 평균값이 3보다 크면 True, 작으면 False
- df.groupby('key').mean()
: groupby로 'key'를 묶고 mean(평균값) 연산
- df.groupby('key').filter(filter_by_mean)
: 'filter_by_mean' 함수를 통해 data2의 평균값이 3보다 큰 key값만 출력
→ 평균값이 3보다 낮은 'A'만을 제외하고 값 출력됨
4) apply() 함수 적용
groupby를 통해서 묶인 데이터에 apply() 함수를 적용할 수 있다.
→ lambda 수식 적용!
# apply를 적용하여 람다식을 이용해 최댓값에서 최솟값을 뺀 값 추출
df.groupby('key').apply(lambda x: x.max() - x.min())

- df.groupby('key').apply(lambda x: x.max() - x.min()
: x의 최댓값(max)에 최솟값(min)를 뺸 값을 연산해서 적용됨.
→ 'key'를 기준으로 data1과 data2값에 모두 적용
5) groupby로 묶은 데이터를 가져오기
groupby로 묶은 데이터를 key값을 통해 다시 가져올 수 있다. → get_group() 사용
아래 예시에는 시도별 대학교 dataset(univ.csv)에 대해 데이터를 묶고 가져와보자
df = pd.read_csv("./univ.csv")
df.head()
df.groupby("시도").get_group("충남")
len(df.groupby("시도").get_group("충남")) # 94
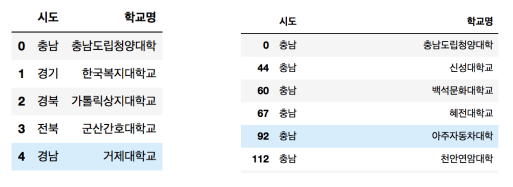
- df.groupby("시도").get_group("충남")
: groupby를 통해서 "시도"별로 데이터를 묶고 그 중에서 "충남"인 데이터만 가져오기/추출하기
- len(df.groupby("시도").get_group("충남"))
: 위의 코드를 통해 추출한 데이터들의 갯수 (len)
4. Multi-index & pivot table
1) Multi-index (행 index)
하나의 데이터프레임 내에 여러 인덱스가 존재할 수 있고, 이들을 계층적으로 만들 수 있다.
df = pd.DataFrame(
np.random.randn(4, 2),
index = [['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns = ['data1', 'data2']
)
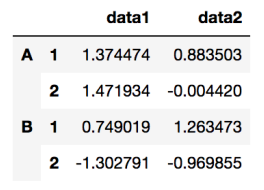
(4, 2) size로 random한 데이터들이 생성되고, 이때의 index는 (A, B), (1, 2), 2가지로 설정하며 각각 column은 data1, data2로 지정한다.
→ A, A와 B, B index는 하나로 묶이고 그 아래에 각각 1과 2의 index가 들어간다.
2) Multi-index (열 index)
위와 동일한 원리로 열 인덱스도 계층적으로 생성할 수 있다.
df = pd.DataFrame(
np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]]
)
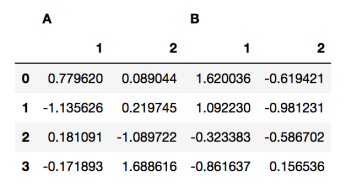
위 사진처럼 열 인덱스를 계층적으로 가져가고 싶다면, column에 index들을 넣어주면 된다.
→ A, B 컬럼 안에 각가 1과 2 column이 속해있는 형태가 된다.
3) 다중인덱스의 인덱스 탐색
다중 인덱스 칼럼의 경우 인덱싱은 계층적으로 하고, 인덱스 탐색의 경우에는 loc, iloc가 사용 가능하다.
→ DataFrame이 2번에서 생성한 것과 동일할 때, index A와 index A 안에 index 1을 추출하는 것을 확인
df["A"]
df["A"]["1"]

- df["A"]["1"]
: 위의 사진에서 오른쪽에 출력된 df["A"]에서 1 index에 해당하는 데이터만 출력된다.
4) pivot_table - 필요한 데이터 추출
데이터에서 필요한 자료만 뽑아서 새롭게 요약과 분석할 수 있는 기능이 엑셀에서의 pivot table과 같다.
이 경우, 총 3가지의 데이터가 필요하다.
1) index : 행 인덱스로 들어갈 key
2) column : 열 인덱스로 들어갈 라벨링될 값
3) value : 실제 분석할 데이터값
아래의 타이타닉 데이터로부터 필요한 자료를 뽑아오는 연습을 해보자

위 사진처럼 class가 column명으로 오고 성별(sex)가 index에 오도록 설정한다면, 각각 value들은 특정 class와 성별에 따른 평균 생존률이 된다. ex) First Class에 탑승한 남성들의 평균 생존률
> Survived는 0~1 사이의 값
> aggfunc = np.mean
: pivot table 내 값들을 어떻게 채울 것인지 결정(=Aggregation function)
→ np.mean으로 평균값으로 채운다. (value로 나오는 'survived'의 값들의 평균)
5) Multi-index와 Pivot Table 연습
Multi-index를 통해 인덱스를 계층적으로 만들고, 생성한 데이터에서 필요한 데이터만 뽑아서 새롭게 요약/분석할 수 있는 Pivot Table을 만들어보자.
인덱스가 A와 B, 1과 2로 나누어져 있는 경우에 출력되는 결과와 멀티 인덱스가 있는 테이블의 인덱싱 방법을 실습해보자.
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
np.random.randn(4, 2),
index=[['A', 'A', 'B', 'B'], [1, 2, 1, 2]],
columns=['data1', 'data2']
)
print("DataFrame1")
print(df1, "\n")
df2 = pd.DataFrame(
np.random.randn(4, 4),
columns=[["A", "A", "B", "B"], ["1", "2", "1", "2"]]
)
print("DataFrame2")
print(df2, "\n")
# 명시적 인덱싱을 활용한 df1의 인덱스 출력
print("df1.loc['A', 1]")
print(df1.loc['A', 1], "\n")
# df2의 [A][1] 컬럼 출력
print('df2["A"]["1"]')
print(df2["A"]["1"], "\n")
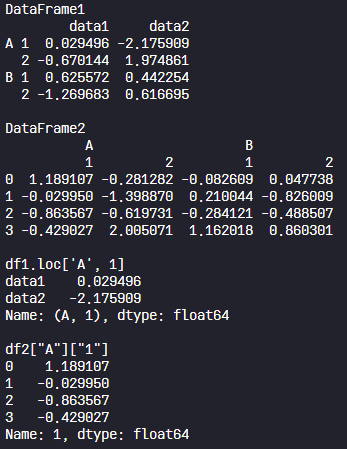
5. Pandas 심화예제 - 피리 부는 사나이를 따라가는 아이들
피리 부는 사나이가 마을의 어린이들을 데리고 떠났다.
우리는 피리 부는 사나이를 따라간 아이들을 구하기 위해 기본 정보를 파악할려고 한다.
피리 부는 사나이를 따라간 어린이들 중 남자와 여자 어린이의 평균 연령을 표로 출력하시오.
(피리 부는 사나이를 따라다니는 쥐들과 아이들에 대한 정보는 'the_pied_piper_of hamelin.csv' 파일에 저장되어있다.)
1) 일차별 아이들의 평균 나이
2) 일차별 남자와 여자 어린이의 평균 나이(pivot table)
3) 한번이라도 참가/떠난 아이들의 이름 출력
import pandas as pd
import numpy as np
# 파일을 읽어서 코드를 작성하시오
# 경로 : "./data/the_pied_piper_of_hamelin.csv"
# 파일 읽어오기. 'index_col=0' : 첫번째 컬럼을 목차로 / (424, 5) 사이즈
df = pd.read_csv("./data/the_pied_piper_of_hamelin.csv")
# 아이들(child)의 데이터만 추출. 마스킹연산 이용 (95, 5) 사이즈
children = df[df["구분"] == "Child"]
# 일차별 아이들의 평균 나이 추출/출력
print("1) 일차별 아이들의 평균 나이 출력 :")
print(children.groupby('일차').mean(), "\n")
# 일차별 남자와 여자 어린이의 평균 나이
print("2) 일차별 남자와 여자 어린이의 평균 나이 :")
df2 = children.pivot_table(index="일차", coluns="성별", values="나이", aggfunc=np.mean)
print(df2, "\n")
# 떠난/참가한 아이들의 이름 출력(unique)
print("3) 한번이라도 참가/떠난 아이들의 이름 출력 :")
for name in children["이름"].unique():
print(name)

- 주어진 데이터에는 child뿐 아니라 Rat을 포함한 다른 생물도 있고, column은 일차/구분/이름/나이/성별로 구분된다. 사이즈는 (424, 5) 사이즈
→ 여러 데이터들이 있기 때문에 아이들(child) 데이터만 추출해야 한다.
→ children = df[df["구분"] == "child"] → (95, 5) 사이즈로 추출
- for name in children["이름"].unique():
: 여러 번 참가한 아이들의 이름을 하나로 출력하기 위해 unique 함수 사용 (중복 X)
'Data Analyst > Basic Python' 카테고리의 다른 글
| [Kaggle 데이터분석] 월드컵 경기 데이터의 다양한 속성 분석해보기! 실습! (0) | 2023.09.30 |
|---|---|
| Matplotlib 데이터 시각화, 꼭 알아야 할 이론부터 실습까지! 총정리! (0) | 2023.09.29 |
| Pandas 기초부터 실습까지! Series와 DataFrame 다루는 법! (0) | 2023.09.06 |
| [python] 데이터 분석의 기초! Numpy의 간단 총정리+실습! (0) | 2023.08.30 |
| [python] 파이썬의 핵심, 객체와 클래스란? 실습을 통해 공부하자! (0) | 2023.08.05 |




댓글