Matplotlib 데이터 시각화, 꼭 알아야 할 이론부터 실습까지! 총정리!
728x90
반응형
지금까지 학습한 Numpy, Pandas의 내용과
matplotlib 라이브러리의 시각화 기능으로 실습을 통해 데이터를 시각화해보자

1. Matplotlib이란?
Matplotlib이란, 파이썬에서 데이터를 그래프나 차트로 시각화할 수 있는 라이브러리
Numpy, Pandas와 같은 라이브러리들과 함께 결합해서 다양한 그래프들을 손쉽게 그릴 수 있음
1) 그래프 그리기 (Statement & Object-Oriented Interface)
'matplotlib.pyplot'을 import하고 plt.plot에 데이터를 넣어주면 그래프가 출력된다.
> 아래의 코드에서는 plt.plot(x, y)에 순차적으로 x와 y값이 들어가게 된다.
# Statement Interface (자동으로 Figure와 ax 생성)
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [1, 2, 3, 4, 5]
plt.plot(x, y)
출력할 그래프에 title, xlabel, ylabel도 추가할 수 있다.
→ plt.title("제목"), plt.xlabel(), plt.ylabel()
# Object-Oriented Interface (객체지향으로 Figure와 ax를 user가 그려서 그래프 출력)
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [1, 2, 3, 4, 5]
fig, ax = plt.subplots()
ax.plot(x, y)
ax.set_title("First Plot")
ax.set_xlabel("x")
ax.set_ylabel("y")
- fig, ax = plt.subplots()
: plt.subplots()로부터 fig와 ax를 가져온다.
- ax.plot(x, y)
: x와 y 데이터를 불러와서 넣는다.
2) matplotlib 구조
matplotlib 구조를 보면서 figure와 ax를 포함한 그래프를 그릴 때의 도구들을 살펴보자
> Figure, Axes
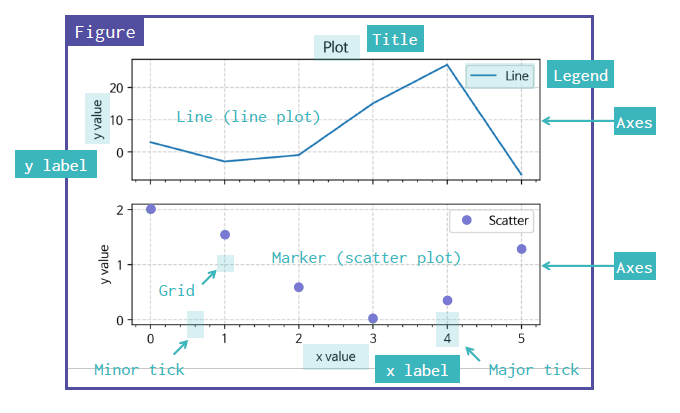
- Figure : 가장 큰 도화지
→ 표현되는 그래프들은 가장 큰 범주인 Figure 내에서 모두 출력된다.
- Axes : Figure(도화지) 안에서 표현되는 그래프들의 영역
- Marker : scatter plot(산점도)에서 표현되는 점들
- Grid : 그래프에서 격자모양으로 점선들이 겹치는 부분
- Major tick : x label 혹은 y label에서 큰 눈금
- Minor tick : Major tick 사이에 있는 작은 눈금
- Legend : 각 그래프 우측 상단에 있으며, 어떤 그래프인지 알려주는 범례
3) 그래프 저장하기
시각화한 그래프를 저장하기 위해서는 전체 도화지, 즉 Figure를 저장해야한다.
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [1, 2, 3, 4, 5]
fig, ax = plt.subplots()
ax.plot(x, y)
ax.set_title("First Plot")
ax.set_xlabel("x")
ax.set_ylabel("y")
fig.set_dpi(300)
fig.savefig("first_plot.png")
- fig.set_dpi(300)
: dpi (=dot per inch)로 1인치 제곱당 몇 dot까지 들어갈 수 있는지를 지정할 수 있다.
→ 300 정도로 지정하면, 출력물에 대해서는 모두 잘 표현된다.
→ 더 작게 저화질로 저장하고 싶다면, 300보다 낮춰서 저장하면 된다.
- fig.savefig("first_plot.png")
: savefig()를 통해서 'first_plot' 라는 이름으로 png 확장자로 그래프 저장
→ 현재 작업하고 있는 디렉토리에 저장된다.
4) 여러 개의 그래프 그리기
하나의 Figure(도화지) 안에 여러 개의 그래프를 시각화해보자
x = np.linspace(0, np.pi*4, 100)
fig, axes = plt.subplots(2, 1)
axes[0].plot(x, np.sin(x))
axes[1].plot(x, np.cos(x))

- x = np.linspace(0, np.pi*4, 100)
: numpy의 linspace 함수를 통해 0~4π 까지 100개의 균등한 구간으로 나누어서 나온 데이터를 x라고 지정
- plt.subplots(2, 1)
: 세로축으로 2개(0, 1), 가로축으로 1개의 데이터를 가진 Fig와 axes를 출력
→ 위부터 axes[0], axes[1] 순서대로 시각화된다.
→ subplot()을 통해서 Figure 내에 몇 개의 그래프를 시각화시킬 것인지 지정할 수 있다.
- axes[0].plot(x, np.sin(x))
: 첫번째 그래프에 x값에 따른 sin값을 시각화
→ axes[1]인 두번째 그래프는 cos값을 시각화
2. Matplotlib 그래프 정리
지금까지 Matplotlib의 기초적인 부분들을 학습했고, 이를 기반으로 어떤 그래프들을 그릴 수 있는지 살펴보자
1) Line plot & 옵션(Line style, color, marker)
Line plot을 아래 코드로 출력해보며, ax.plot() 안에 3가지 옵션을 추가해보자
fig, ax = plt.subplot()
x = np.arange(15)
y = x ** 2
ax.plot(
x, y,
linestyle = ":",
marker = "*",
color = "#524FA1"
)

- x = np.arange(15)
: 0~14까지의 데이터를 가져와서 x에 넣는다
- ax.plot() 내 옵션
→ linestyle, marker, color ... 위의 시각화된 그래프 참고
# Line Style
Line plot을 그릴 때 참고할만한 4가지의 Line Style을 출력해서 각각 비교해보자
→ 위에 있는 코드부터 순서대로 출력된 모습 (사진 참고)
x = np.arange(10)
fig, ax = plt.subplots()
# dotted
ax.plot(x, x+6, linestyle = ":")
# dashdot
ax.plot(x, x+4, linestyle = "-.")
# dashed
ax.plot(x, x+2, linestyle = "--")
# solid
ax.plot(x, x, linestyle = "-")
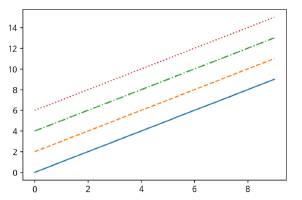
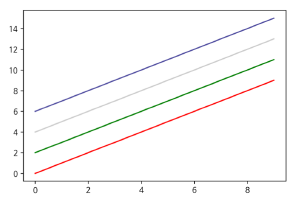
# Line Color
Plot을 그릴 때, Line에 색상도 4가지 방법으로 추가할 수 있으며, 아래 코드와 실행결과를 확인해보자
x = np.arange(10)
fig, ax = plt.subplots()
# RGB에 대한 16진수 코드
ax.plot(x, x+6, color = "#524FA1")
# 0 ~ 1 사이의 값이 문자열 - 0이면 검은색, 1이면 투명한 흰색
ax.plot(x, x+4, color = '0.8')
# 색상 이름의 풀네임
ax.plot(x, x+2, color = "green")
# RGB, CMYK 등의 문자열
ax.plot(x, x, color = "r")
# Marker
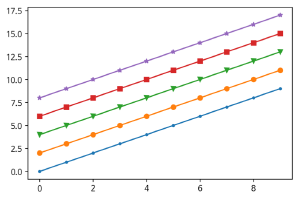
Marker에도 종류가 많지만, 대표적으로 쓰이는 5개를 아래와 같이 출력해보자
→ 코드 순서대로 시각화된 결과 확인
x = np.arange(10)
fig, ax = plt.subplots()
ax.plt(x, x+8, marker="*")
ax.plt(x, x+6, marker="s")
ax.plt(x, x+4, marker="v")
ax.plt(x, x+2, marker="o")
ax.plt(x, x, marker=".")
2) 그래프 속성 (축 경계, 범례(legend))
지금까지 Line Plot 에 어떤 속성이 들어가는지를 확인했다면, 이제부터 그래프 자체에는 어떤 옵션들이 있는지 확인해보자
# 축 경계 조정하기
축 경계란, x와 y축이 어디서부터 시작되고 어디까지 끝나는 지에 대한 조정을 의미한다.
→ set_xlim(), set_ylim() 를 통해서 경계를 설정할 수 있다.
→ 축 경계를 조정하지 않으면, matplotlib에 의해 최적화된 그래프로 시각화된다.
x = np.linspace(0, 10, 1000)
fig, ax = plt.subplots()
ax.plot(x, np.sin(x))
ax.set_xlim(-2, 12)
ax.set_ylim(-1.5, 1.5)
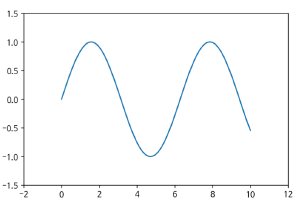
- x = np.linspace(0, 10, 1000)
: linspace() 함수를 통해 0부터 10사이의 1000개의 데이터를 뽑아서 x로 가져오기
- ax.plot(x, np.sin(x))
: ax.plot()를 통해 x값과 x값에 따른 sin(x) 그래프를 출력
- ax.set_xlim(-2, 12)
: x축을 -2부터 12까지 경계 조정
- ax.set_ylim(-1.5, 1.5)
: y축을 -1.5부터 1.5까지 경계 조정
# 범례 (legend)
아래 코드는 x값이 0~9까지의 정수라고 가정할 때, 'y=x'와 'y=x^2' 그래프로 표현하며, 각각 label 값을 넣어준다. 그리고 x와 y에 각각 label과 legend를 지정
fig, ax = plt.subplots()
ax.plot(x, x, label='y=x')
ax.plot(x, x**2, label='y=x^2')
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend(
loc = 'upper right',
shadow = True,
fancybox = True,
borderpad = 2
)
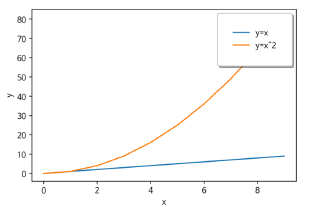
- ax.set_xlabel("x")
: x축 label에 'x'라고 지정. ylabel도 동일
- loc = 'upper right'
: legend 속성값으로 안에는 그래프의 선과 Label값이 표시된다. 우측 상단에 표시(loc = location)
→ lower left, center 등으로도 설정 가능
- shadow = True
: 범례(legend)의 그림자 표시 On 설정
- fancybox = True
: legend가 표현되는 박스를 둥글게 출력할 수 있다. (True일 경우)
- borderpad = 2
: 범례 박스 안(표시되는 데이터 밖)에 있는 흰색 영역의 크기 (숫자가 클수록 여백이 커진다)
3) Matplotlib 그래프 출력 연습
지금까지 학습한 내용을 기반으로 어떤 그래프들을 그리고 옵션을 추가하는 연습을 해보자
→ 취향에 따라 ax.plot() 함수의 marker, color, linestyle의 옵션을 변경해보자
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 2가지의 그래프 출력 (x = 0~9)
x = np.arange(10)
fig, ax = plt.subplots()
ax.plot(
x, x, label='y=x',
marker='o',
color='blue',
linestyle=":"
)
ax.plot(
x, x**2, label='y=x^2',
marker='^',
color='red',
linestyle='--'
)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend(
loc='upper left',
shadow=True,
fancybox=True,
borderpad=2
)
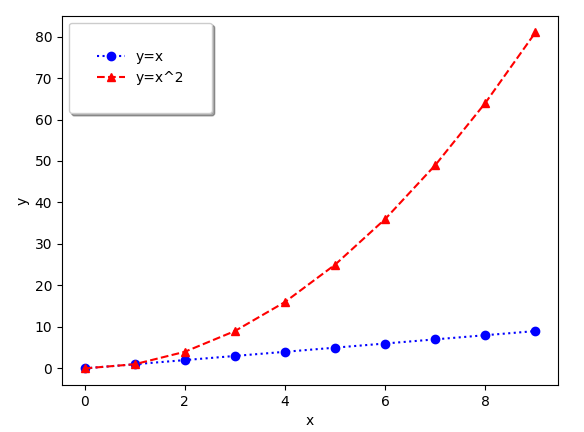
예시 코드에서는 figure와 ax가 각각 1개인데, ax.plot 함수를 2번 호출함으로써
하나의 ax 안에 여러개의 그래프를 출력하면 겹쳐서 그릴 수 있게 된다.
3. Scatter (산점도)
1) Scatter 그래프란?
Scatter 그래프는 산점도라고도 하며, 이를 사용하게 되면 값 사이의 관계를 파악하기 용이해지고 데이터셋에서 이상값을 찾기도 용이하다. 두 개 이상의 측정값의 상관 관계를 파악하고 시각화 할 수 있는 그래프의 유형이다.
그래프는 아래와 같이 표현될 수 있으며, 코드를 통해 학습해보자
fig, ax = plt.subplots()
# x = 0 ~ 9
x = np.arange(10)
ax.plot(
x, x**2, "o"
markersize = 15,
markerfacecolor = 'white',
markeredgecolor = 'blue'
)

- ax.plot( ~, "o", ~)
: ax.plot() 안에 세번째 인자에 "o"을 입력하면, 라인이 아닌 원으로 그래프가 표현된다.
- markersize = 15
: 출력되는 원의 크기
- markfacecolor = 'white'
: 원 안의 색상 지정
- markteredgecolor = 'blue'
: 원을 그리는 가장 바깥쪽의 edge 색상
2) Scatter 그래프의 Size와 Color 지정
Scatter 그래프에서의 원의 Size와 Color를 각각 지정한 채로 만들어줄 수 있다.
→ 아래 코드에서는 x, y, colors, sizes 값 모두 랜덤하게 추출해서 scatter 그래프를 그려보자
fig, ax = plt.subplots()
x = np.random.randn(50)
y = np.random.randn(50)
colors = np.random.randint(0, 100, 50)
sizes = 500 * np.pi * np.random.rand(50) **2
ax.scatter(
x, y, c=colors, s=sizes, alpha=0.3
)

- x = np.random.randn(50)
: randn()을 통해서 정규분포에서 50개씩 x값을 추출 (y도 동일)
- colors = np.random.randint(0, 100, 50)
: randint() 함수를 통해 0부터 100 사이 50개의 랜덤한 수를 colors에 넣어준다
- sizes = 500 * np.pi * np.random.rand(50) ** 2
: sizes라는 변수 안에도 임의의 수가 곱혀지도록 하여 값이 랜던하게
- ax.scatter(x, y, c=colors, s=sizes, alpha=0.3)
: x, y값을 통해 원의 중심이 어디에 찍힐지 정하고, c는 color, s는 size를 지정, alptha는 투명도 설정(데이터가 잘 보이도록)
4. Bar & Histogram
Bar 그래프(=막대 그래프)는 여러 값을 비교하는데 매우 적합한 그래프이다. 여러개의 데이터를 입력받고 그 값들을 한눈에 비교 할 수 있다.
Histogram은 일정 시간동안의 숫자 데이터 분포를 시각화하는데 적합하다.
1) Bar Plot (Single)
x = np.arange(10)
fig, ax = plt.subplots(figsize=(12,4))
ax.bar(x, x*2)
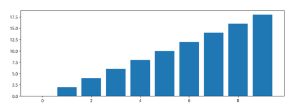
- figsize = (12, 4)
: figure 사이즈를 지정 가로로 12, 세로로 4인 Figure 안에서 그래프 출력
- ax.bar(x, x*2)
: bar plot. x와 y값을 넣어준다.
2) 누적된 Bar Plot
누적된 Bar plot을 표현하기 위해서는 첫번째 데이터로 Bar plot을 하고, 그 y값을 다음 데이터의 bottom을 기준으로 다음 y값만큼 쌓아올리는 원리로 실행된다.
x = np.random.rand(3)
y = np.random.rand(3)
z = np.random.rand(3)
data = [x, y, z]
fig, ax = plt.subplots()
x_ax = np.arange(3)
for i in x_ax:
ax.bar(x_ax, data[i],
bottom = np.sum(data[:i}, axis=0))
ax.set_xticks(x_ax)
ax.set_xticklabels(["A", "B", "C"])

- x = np.random.rand(3)
: 0부터 1사이의 3개의 데이터 추출(y, z도 동일)
- x_ax = np.arange(3)
: 0~2까지 총 3개의 값 추출 (= 0, 1, 2) → x값의 데이터
- ax.bar(x_ax, data[i, ~
: for문에서 i값이 1씩 증가함으로 x_ax(=x값)은 순차적으로 (0, 1, 2)에 data의 [x, y, z] 순서대로 값이 들어간다.
- bottom = np.sum(data[:i], axis=0 ~
: bottom 인자에는 Bar plot을 그리는 시작점이 어디인지 설정.
→ np.sum(data[:i] ~ : 현재 data값 이전까지의 sum값 기준, 즉 이전까지의 y값의 총합.
→ axis = 0 : x축을 기준으로
- ax.set_xticks(x_ax)
: x축은 np.arange(3)에 의해서 (0, 1, 2)이지만, xticks으로 지정
- ax.set_xticklabels(["A", "B", "C"])
: xtick값에 각각 "A", "B", "C"라는 문자열로 넣어준다.
3) Histogram (=도수분포표)
fig, ax = plt.subplots()
data = np.random.randn(1000)
ax.hist(data, bins=50)
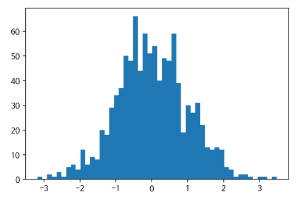
- data = np.random.randn(1000)
: randn() 함수를 통해 표준정규분포에서 1000개의 데이터 추출하여 data로 가져온다.
- ax.hist(data, bins=50)
: ax.hist()를 통해 Histogram를 표현하며, x값에는 data로 넣는다.
→ bins 인자는 출력되는 Bar가 얼마큼 나오게 될 것인지 설정. bins값이 클수록 Bar 폭이 좁고 많이 출력되고, 작을수록 폭이 넓고 조금 출력되게 된다.
4) Bar & Histogram 그래프 예제
지금까지 학습한 Bar와 Histogram 그래프를 간단한 예제로 연습해보자
아래 x와 y 데이터는 각각 스포츠의 종목과 각 스포츠를 선호하는 학생의 수를 조사한 결과이다. (z는 난수)
x와 y 데이터에 대한 막대그래프와 z 데이터를 등급을 50개로 나눈 히스토그램을 출력해보자
# Tip
: matplotlib의 pyplot으로 그래프를 그릴 때 한글을 기본 폰트로 지원하지 않는다. 따라서 한글을 지원하는 '나눔바른고딕' 폰트로 바꾼 코드를 적용시켜야 한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# pyplot에서 한글 지원 폰트로 바꾸어서 한글로 표시
import matplotlib.font_manager as fm
fname = './NanumBarunGothic.ttf'
font = fm.FontProperties(fname = fname).get_name()
plt.rcParams["font.family"] = font
x = np.array(["축구", "야구", "농구", "배드민턴", "탁구"])
y = np.array([18, 7, 12, 10, 8])
# 히스토그램을 표현하기 위한 z값(난수) 추출
z = np.random.randn(1000)
fig, axes = plt.subplots(1, 2, figsize=(8,4))
# Bar 그래프
axes[0].bar(x, y)
# 히스토그램
axes[1].hist(z, bins=50)
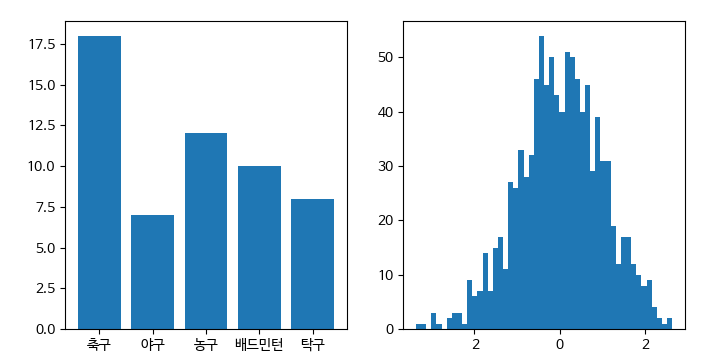
- fig, axes = plt.subplots(1, 2, figsize = (8, 4))
: 하나의 figure에 1*2 size로 2개의 그래프를 가로로 배치하도록 그리는 코드 (axes[0], axes[1])
→ figsize는 (8, 4)
# pyplot으로 그래프를 표현할 때 한글 폰트는 default로 지원되지 않기 때문에 한글 지원 폰트로 바꾸어서 한글을 사용할 수 있다.
5. Matplotlib with Pandas
지금까지는 Matplotlib에 numpy 데이터를 가지고 그래프를 그렸다면, 이번에는 Pandas의 DataFrame이나 Series 데이터를 넣어서 시각화하는 방법에 대해 확인해보자
1) Line plot
'president_height.csv'라는 미국 대통령의 키(height) 정보가 있는 데이터가 주어지고, 이를 통해 그래프를 그려보자
df = pd.read_csv("./president_height.csv")
fig, ax = plt.subplots()
ax.plot(df["order"], df["height(cm)"], label="height")
ax.set_xlabel("order")
ax.set_ylabel("height(cm)")
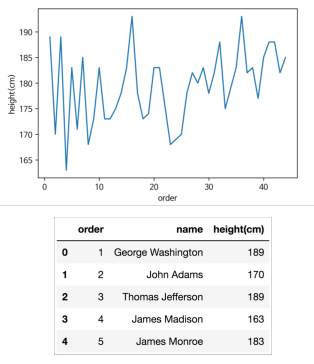
- ax.plot(df["order"], df["height(cm)"], label="height")
: x축에는 데이터프레임의 'order'값(=순서)으로 잡고, y축에는 height(cm)값으로 설정 (label은 'height')
- ax.set_xlabel("order"), ax.set_ylabel("height(cm)")
→ x와 y축 label을 각각 'order'와 'height(cm)'로 입력
2) Scatter plot 예제 - 포켓몬데이터
아래 DataFrame와 같이 포켓몬스터의 이름, Type, HP 등의 데이터가 주어지고, 이를 통해 불과 물 포켓몬의 공격(Attack)과 방어(Defense)를 비교해서 시각화를 해보자
→ 공격과 방어에 대한 불과 물의 포켓몬의 Scatter 그래프를 시각화해보자 (빨간색 : Fire, 파란색 : Water)
fire = df[(df['Type 1'] == 'Fire') | (df['Type 2'] == 'Fire')]
water = df[(df['Type 1'] == 'Water') | (df['Type 2'] == 'Water')]
fig, ax = plt.subplots()
# fire와 water에 대한 scatter 그래프를 2번 그림
ax.scatter(fire['Attack'], fire['Defense'], color='R', label='Fire', marker="*", s=50)
ax.scatter(water['Attack'], water['Defense'], color='B', label='Water', s=25)
ax.set_xlabel("Attack")
ax.set_ylabel("Defense")
ax.legend(loc="upper right")
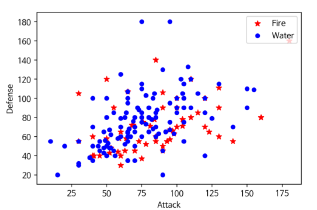
- fire = df[(df['Type 1'] == 'Fire') | ((df['Type 2']) == 'Fire']
: df에서 'Type 1'에 불이 있거나 'Type 2'에 불이 있을 경우, 'fire'라는 새로운 df를 만든다.
→ 마스킹 연산 활용. water도 동일 원리
# 주어진 데이터 내 포켓몬스터들의 공격과 수비 능력치가 x와 y축으로 주어지고 물 속성 포켓몬은 파란색, 불 속성 포켓몬은 빨간색으로 표현한 그래프로 시각화
6. Matplotlib 예제 - 토끼와 거북이 경주 결과 시각화
토끼와 거북이가 달리기 시합을 하기로 했다.
1초마다 토끼와 거북이의 위치가 기록된 데이터(the_hare_and_the_tortoise.csv)를 통해 시간별 위치를 그래프로 시각화해보자
from matplot import pyplot as plt
import pandas as pd
plt.rcParams["font.family"] = 'NanumBarunGothic'
# 경로 : "./data/the_hare_and_the_tortoise.csv"
# 첫번째(=0번쨰) 컬럼을 index로 설정
df = pd.read_csv('./data/the_hare_and_the_tortoise.csv', index_col=0)
# 또는 특정 컬럼을 index로 잡고 싶다면? - 아래는 '시간' 데이터를 index로 설정
df.set_index("시간", inplace=True)
# 그래프 그리기
fig, ax = plt.subplots()
ax.plot(df['토끼'], color='blue')
ax.plot(df['거북이'], color='orange')
ax.legend(loc="upper left")
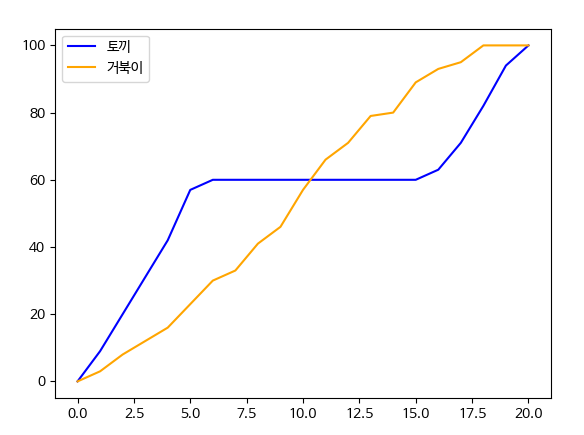
- ax.plot(df['토끼'], color='blue')
: x축에 df['시간']을 생략해도 시간 데이터가 index로 잡힌다.
→ 첫번째 컬럼을 index로 변경했기 때문에 (index_col = 0)
- inplace = True
: 변경한 값을 반영해서 원본도 변경된 값으로 저장됨
'Data Analyst > Basic Python' 카테고리의 다른 글
| [파이썬 확률 통계] 시각화를 통한 데이터 요약하는법! 이론과 실습! (2) | 2023.10.17 |
|---|---|
| [Kaggle 데이터분석] 월드컵 경기 데이터의 다양한 속성 분석해보기! 실습! (0) | 2023.09.30 |
| Pandas 함수 활용법! - 조건검색, 함수로 데이터 처리 등 심화학습! (2) | 2023.09.26 |
| Pandas 기초부터 실습까지! Series와 DataFrame 다루는 법! (0) | 2023.09.06 |
| [python] 데이터 분석의 기초! Numpy의 간단 총정리+실습! (0) | 2023.08.30 |




댓글