Pandas 기초부터 실습까지! Series와 DataFrame 다루는 법!
728x90
반응형
Numpy 기반 라이브러리인 Pandas의 데이터 조작 방법을 학습하고
실습을 통해 Pandas의 기본 자료 형태인 Series와 DataFrame을 다뤄보자

1. Pandas란?
Pandas란, 구조화된 데이터를 효과적으로 처리하고 저장할 수 있는 파이썬 라이브러리이다.
대용량 Array 데이터를 쉽게 처리가능한 numpy를 기반으로 구성되어있어서 다양한 기능들을 제공한다.
ex) 행과 열을 가진 2차원 데이터와 엑셀 데이터에 대해서 DataFrame이라는 효율적인 자료구조를 제공한다.
2. Series 데이터
1) Series란?
Series란, numpy array가 보강된 형태인 Data와 Index를 가지고 있다. (특수한 Dictionary 형태?!)

위 Data 부분에는 1~4가 들어가고, 각 값에 따라 Index가 부여된다. 데이터타입(dtype)은 int64(정수형).
2) Series 특징1. Index
Index를 가지고 있으므로, Index로 접근이 가능하다.
import pandas as pd
data = pd.Series([1, 2, 3, 4])
data

위와 같이 각 Data마다 index값을 각각 지정해줄 수 있다.
3) Series 특징2. 딕셔너리
Series를 통해 Dictionary를 생성할 수 있고, 아래 예제를 통해 나라별 인구수를 지정할 수 있다.
population_dict = {
'china' : 141500,
'japan' : 12718,
'korea' : 5180,
'usa' : 32676,
}
population = pd.Series(population_dict)

위에서 Dictionary의 Key값들은 Series의 index로, Value값들은 Data로 들어가게 된다. (int64 타입)
3. DataFrame 형태와 속성
1) DataFrame이란?
DataFrame이란, 여러 개의 Series가 모여서 행과 열을 이룬 데이터

4개의 나라에 GDP를 Dictionary 형태로 Series를 생성해서 'gdp'로 저장
'country'에는 기존에 만들었던 population data와 방금 생성한 gdp data를 각각 'population'과 'gdp' key로 저장하여 DataFrame을 생성할 수 있다. (2차원 행렬 형태)
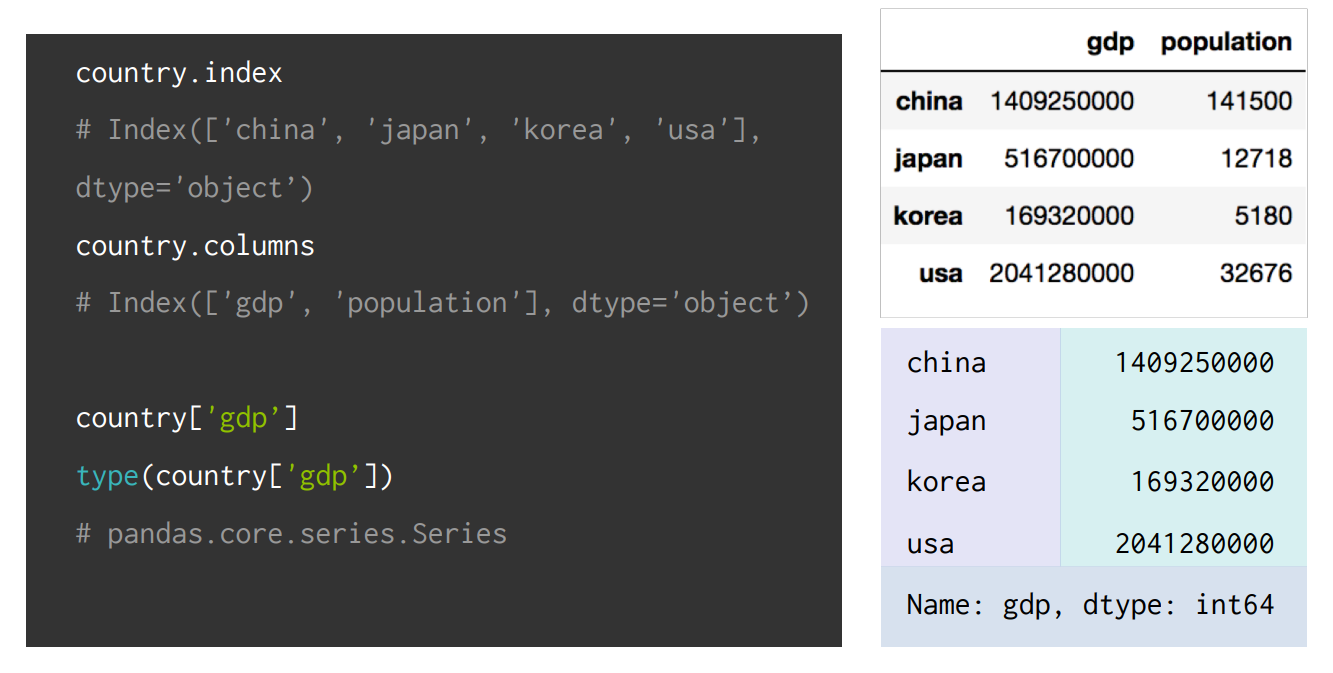
country.index과 columns에 설정한 값들이 잘 들어가있는지 확인할 수 있다. (dtype = 'object' (객체))
더불어 country['gdp'] : country DataFrame에서 gdp Column 데이터형태는 Series인 것을 알 수 있다.
이처럼 여러개의 Series 데이터가 모여서 DataFrame 형태를 이루고, 이 Series 데이터의 가장 기본적인 부분은 Numpy가 보강된 형태이다.
2) DataFrame의 연산
Series는 Numpy의 보강된 형태이므로, Numpy array처럼 연산자를 사용할 수 있다.

gdp_per_capita : 1인당 gdp (총 gdp / 인구수) → Series 연산 결과는 Series 형태
# 추출한 연산값을 DataFrame에 넣기
country['gdp per capita'] = gdp_per_capita : 'gdp per capita'라는 이름을 가진 column을 country라는 DataFrame에 추가하고, 각 index에 대한 값은 산출된 Series 데이터를 그대로 넣어주면 된다.
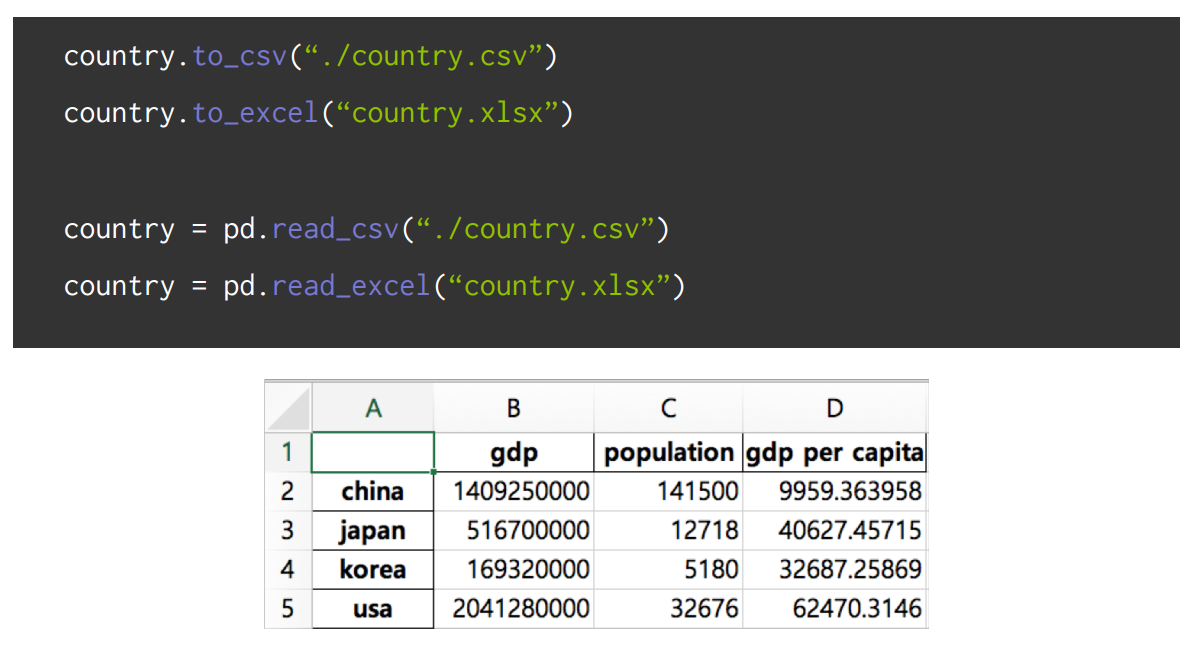
3) DataFrame 저장과 불러오기
지금까지 생성한 나라별 '인구수(population)'와 '1인당 GDP(gdp per capita)'라는 새로운 데이터를 저장하고 불러오는 법에 대해 학습하자. (.csv, .excel 형식)
4) DataFrame 다루는 예제 실습
아래 주어진 2개의 Series 데이터를 통해 DataFrame을 생성하고 아래의 예제를 풀어보자
(국가별 GDP = gdp_dict, 국가별 인구 = population_dict)
Q1) 두 Series 데이터로 'country'라는 DataFrame 생성하시오
Q2) country의 두 Column을 이용하여 새로운 Column 생성해서 DataFrame에 추가하시오
- 1인당 GDP(gdp per capita) = gdp / population
Q3) 완성한 DataFrame을 출력하시오
import numpy as np
import pandas as pd
# 2개의 주어진 Series 데이터
print("Population series data:")
population_dict = {
'korea': 5180,
'japan': 12718,
'china': 141500,
'usa' : 32676
}
population = pd.Series(population_dict)
print(population, "\n")
print("GDP series data:")
gdp_dict = {
'korea': 169320000,
'japan': 516700000,
'china': 1409250000,
'usa' : 2041280000,
}
gdp = pd.Series(gdp_dict)
print(gdp, "\n")
# 2개의 Sereis 값이 들어간 DataFrame 생성
country['gdp per capita'] = country['gdp'] / country['population']
print(country, "\n")
# 생성한 DataFrame의 index와 column을 각각 출력
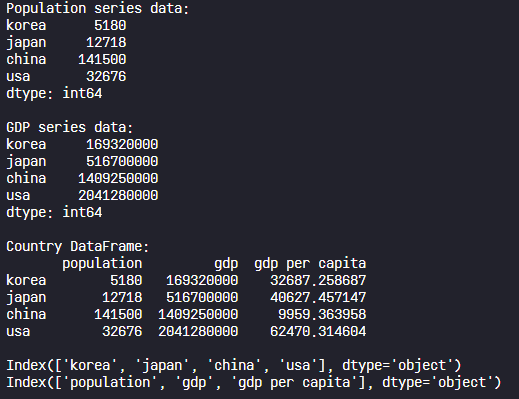
print(country.index)
print(country.columns)
4. Indexing & Slicing
Series, DataFrame 에서 원하는 데이터값을 찾고 변경하는 법에 대해서 알아보자
이 때, 데이터를 찾는 방법이 크게 2가지가 있다. (loc, iloc)
1) 데이터 찾기(1) loc : 명시적 인덱스 참조
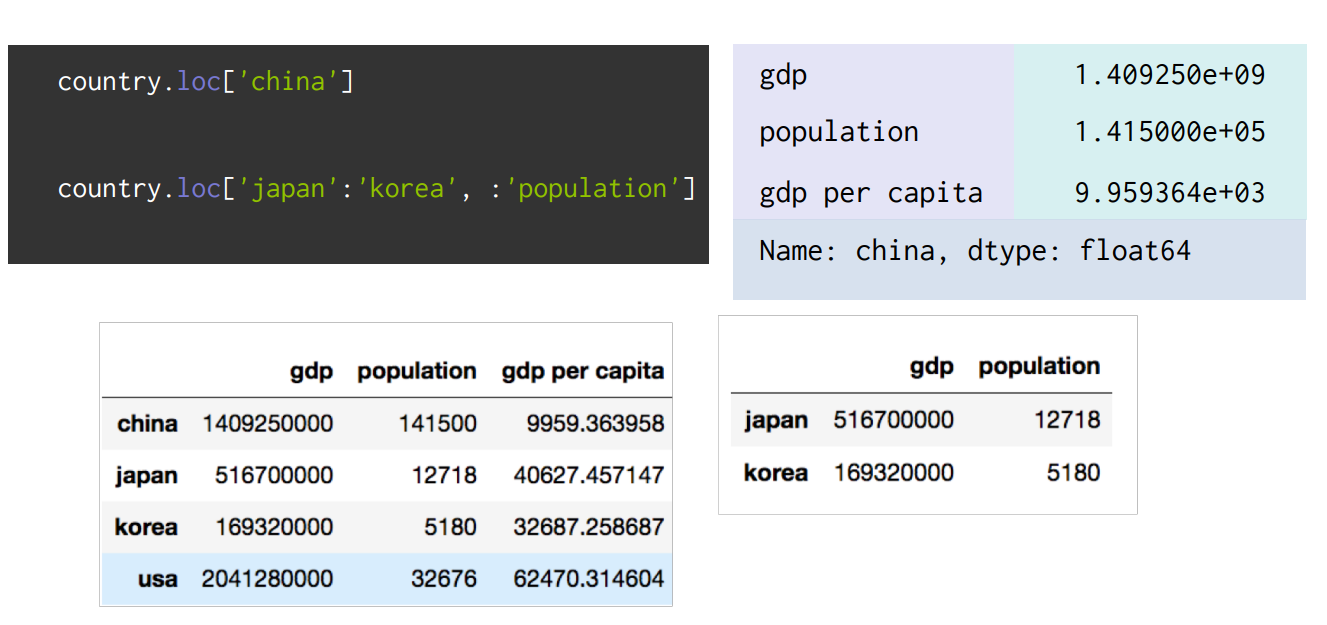
# 명확한 인덱스를 통한 데이터 추출
country.loc['china'] : 'country'라는 DataFrame에서 'china' 인덱스에 해당하는 값 추출 (Series)
# 명시적 슬라이싱을 통한 데이터 추출
country.loc['japan':'korea', :'population'] : japan부터 korea의 population 이전 값까지 추출 (DataFrame)
2) 데이터 찾기(2) iloc : 정수 인덱스 참조

# 앞에서부터의 index 정수를 통한 인덱스
country.iloc[0] : index가 0번째인 china의 Series 데이터가 추출
# 특정 부분을 슬라이싱으로 정수로 표현해서 추출
country.iloc[1:3, :2] : 1~2번째의 row 중, column의 2번째 이전의 값들(gdp, population) 추출
3) DataFrame에 새로운 데이터 추가 / 수정
DataFrame에 새로운 데이터를 추가하는 방법은 List 혹은 Dictionary 형태로 추가할 수 있다.
# dataframe의 column에 이름 추가
dataframe = pd.DataFrame(columns=['이름', '나이', '주소'])
# List 형식으로 추가. 순서대로 들어감
dataframe.loc[0] = ['임원균', '26', '서울']
# Dictionary 형식으로 추가. column의 이름이 key로 들어감
dataframe.loc[1] = {'이름':'철수', '나이':'25', '주소':'인천'}
# index 1번째 철수의 이름을 영희로 변경
dataframe.loc[1, '이름'] = '영희'

4) DataFrame에 새로운 Column 추가
위에서 생성한 DataFrame에 '전화번호'라는 Column을 추가하고 값을 넣어보자
dataframe['전화번호'] = np.nan
dataframe.loc[0, '전화번호'] = '01012341234'
len(dataframe) # 2
# dataframe의 데이터 갯수는 0~1로 2개
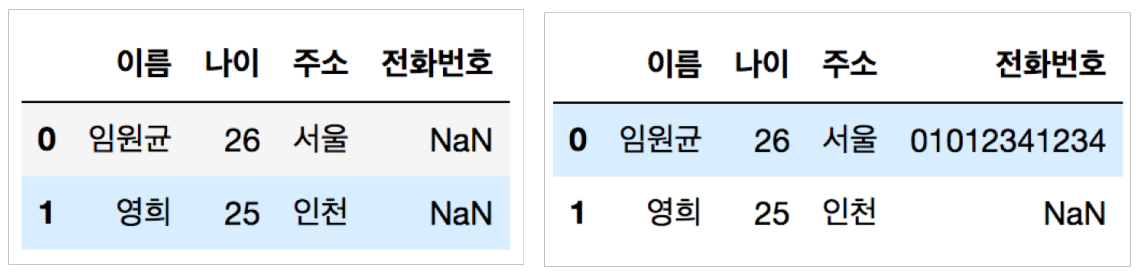
- np.nan
: Not a Number. 값이 비어있는 데이터를 의미
- dataframe.loc[0, '전화번호'] = '01012341234'
: index 0번째에 전화번호 컬럼에 '01012341234' 값을 추가
반응형
5) Column 선택하기
Column을 선택할 때, 하나만 선택할 경우 Series로 출력되고 List 형식으로 여러 개의 Column이 선택될 경우 DataFrame 형식으로 출력된다.
- Column 하나 : Series로 출력
- Column 2개 이상 : DataFrame으로 출력
dataframe["이름"]
dataframe[["이름", "주소", "나이"]]

위와 같이 생성한 DataFrame에서 특정 Column만 뽑아서 새로운 DataFrame을 만들고자 한다면 해당 Column의 이름들을 List 형식으로 넣어주면 된다.
6) DataFrame의 인덱싱/슬라이싱 예제
지금까지 학습한 DataFrame의 값을 참조하는 인덱싱(Indexing)과 슬라이싱(Slicing)에 대한 예제를 풀어보자
1) 첫번째 컬럼을 인덱스로 country.csv 파일 읽어오기 (파일은 주어짐)
2) 명시적 인덱싱(loc)을 사용하여 DataFrame의 "china" 인덱스 출력
3) 정수 인덱싱(iloc)을 사용하여 DataFrame의 1번째부터 3번째 인덱스 출력
import numpy as np
import pandas as pd
# 1) 파일 읽어오기
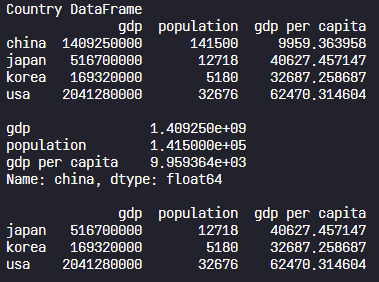
print("Country DataFrame")
country = pd.read_csv("./data/country.csv", index_col=0)
print(country, "\n")
# 2) 'china' 인덱스 출력(loc)
print(country.loc["china"], "\n")
# 3) DataFrame의 1~3번째 index 출력(iloc)
print(country.iloc[1:4])
5. Pandas 연산과 함수
1) 누락된 데이터를 확인하고 제거 및 채우기
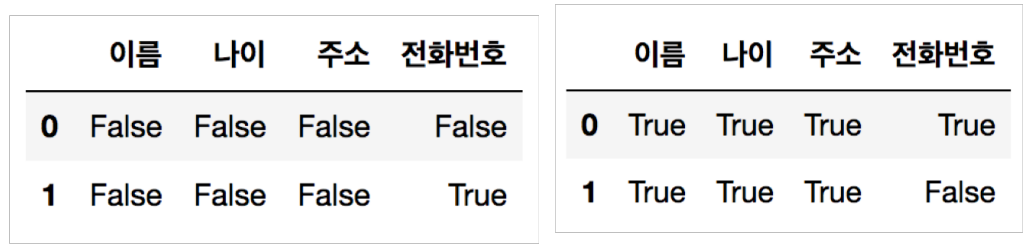
현실에서 취득하는 데이터들은 누락되어 있는 형태가 많다. 이 경우, isnull() 과 notnull() 을 통해서 확인할 수 있다.
- isnull() : 데이터가 비어있는지 확인 (비어있으면, True)
- notnull() : 데이터가 비어있지 않은 경우에 대해 확인 (비어있지 않으면, True)
- dropna() : 데이터를 제거 (비어있는 row 제거)
- fillna() : 데이터를 채워넣기
dataframe.isnull()
dataframe.notnull()
dataframe.dropna()
dataframe['전화번호'] = dataframe['전화번호'].fillna('전화번호 없음')

- dataframe.dropna()
: 1번째 index에 있는 전화번호 데이터가 비어있었음으로 dropna() 통해 제거됨 확인
- dataframe['전화번호'] = dataframe['전화번호'].fillna('전화번호 없음')
: 전화번호에 비어있는 값을 '전화번호 없음' 이라고 채우고, 그 결과(Series 데이터)를 dataframe의 전화번호에 채워넣기
2) Series 연산
numpy array에서와 동일하게 Pandas에서도 연산자를 활용할 수 있다.
# Pandas 연산
A = pd.Series([2, 4, 6], index=[0, 1, 2])
B = pd.Sereis([1, 3, 5], index=[1, 2, 3])
A + B
A.add(B, fill_value=0)

각 index에 맞는 Value끼리 연산을 수행한다. 만약 한쪽이라도 해당 index에 값이 없다면 'Nan' 출력
- A.add(B, fill_value=0)
: 한쪽에 만약 값이 비어있는 경우(Nan), 그 값을 '0'으로 취급하여 연산을 수행한다.
3) DataFrame 연산
DataFrame 형태에서도 여러가지 연산이 가능하다. add(+), sub(-), mul(*), div(/) 등
A = pd.DataFrame(np.random.randint(0, 10, (2,2)), columns=list("AB"))
b = pd.DataFrame(np.random.randint(0, 10, (3,3)), columns=list("BAC"))
A + B
A.add(B, fill_value=0)
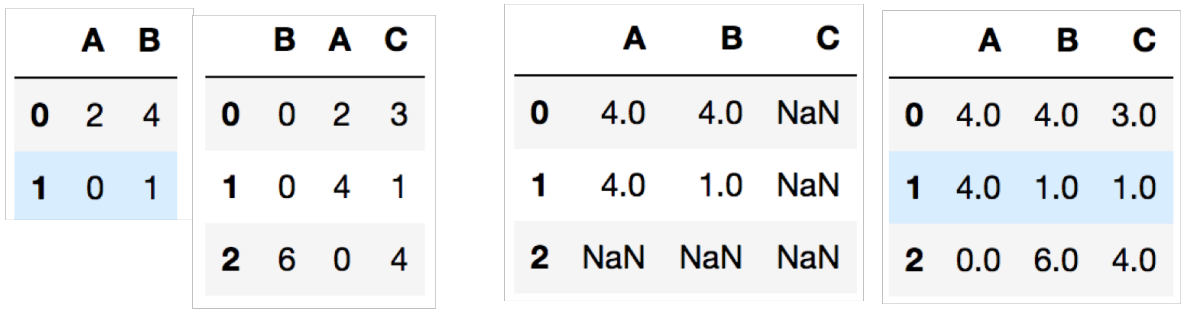
- pd.DataFrame(np.random.randint(0, 10, (2, 2)), columns=list("AB")
: 0부터 10사이의 (2,2) 사이즈의 랜덤한 데이터를 넣고, column은 A와 B로 선언
4) 집계함수 사용 (sum, mean 등)
numpy arrady에서 사용했던 집계함수(sum, mean 등)을 활용할 수 있다.
data = {
'A': [ i+5 for i in range(3) ],
'B': [ i **2 for i in range(3) ]
}
df = pd.DataFrame(data)
df['A'].sum() # 18
df.sum()
df.mean()

A : range(3), 즉 3개의 변수에 5를 더한 값들(i + 5)의 List
B : 3개의 변수에 제곱한 값(i ** 2)들의 List
→ i는 0부터 순차적으로 대입
- df['A'].sum() : A series 데이터들만 뽑아서 그 총합 출력
- df.sum() : 각 Column들이 index로 설정되고, 각 index별 sum 연산
- df.mean() : df.sum()과 동일한 원리로, 각 index별 mean(평균) 연산
6. DataFrame 정렬하기
1) 값으로 정렬하기 (1개의 column 기준)
DataFrame 내 많은 데이터들을 값으로 정렬할 수 있는 함수에 대해 알아보자.
→ sort_values()
: 인자에 column을 입력으로 넣어주면, 해당 column에 있는 값들로 지정(기준)이 되어 정렬된다.
기본적으로 오름차순으로 정렬되며, 'ascending=False' 옵션을 추가하면 내림차순으로 정렬된다.
# 데이터프레임 생성
df = pd.DataFrame({
'col1' : [2, 1, 9, 8, 7, 4],
'col2' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'col3' : [0, 1, 9, 4, 2, 3],
})
# 값 정렬하기 (sort_values)
df.sort_values('col1')

# 값들을 내림차순으로 정렬
df.sort_values('col1', ascending=False)

위의 결과처럼, 'ascending=False'를 추가하면 'col1'의 값들이 내림차순으로 정렬되는 것을 확인할 수 있다.
2) 값으로 정렬하기 (2개 이상의 column 기준)
값으로 정렬할 때 1개의 column이 아닌 2개 이상의 column을 지정(기준)으로 정렬하는 경우에 해당한다.
df.sort_values(['col2', 'col1'])
- df.sort_values(['col2', 'col1'])
: 'col2'를 기준으로 먼저 정렬하고, 그 기준에 대해 'col1'의 값들이 정렬됨
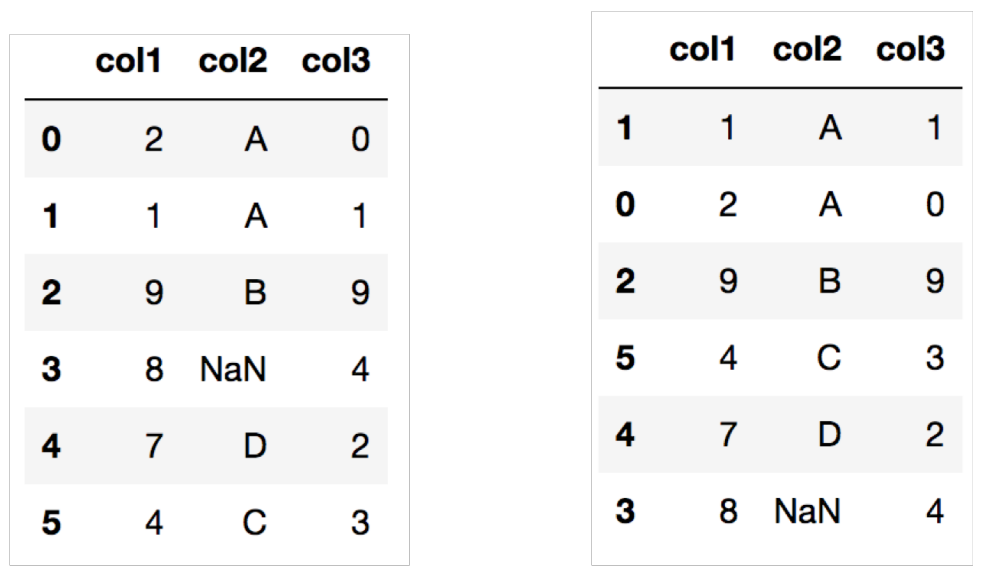
3) DataFrame 값으로 정렬하기 - 예제
데이터를 처리하는 과정에서 일정한 기준에 맞추어 정렬해야하는 과정이 필요한 상황이 많다. 지금까지 Pandas에서 데이터를 정렬하는 법을 학습했으며, 아래 예제를 통해 오름차순, 내림차순으로 정렬해보자.
1) 아래 주어진 col1을 기준으로 오름차순으로 정렬하기
2) col2를 기준으로 내림차순으로 정렬하기
3) col2를 기준으로 오름차순으로, col1를 기준으로 내림차순으로 정렬하기
import numpy as np
import pandas as pd
print("DataFrame: ")
df = pd.DataFrame({
'col1' : [2, 1, 9, 8, 7, 4],
'col2' : ['A', 'A', 'B', np.nan, 'D', 'C'],
'col3' : [0, 1, 9, 4, 2, 3],
})
print(df, "\n")
# 정렬 코드 입력
# 1) col1을 기준으로 오름차순으로 정렬하기
sorted_df1 = df.sort_values('col1', ascending = True)
# 2) col2를 기준으로 내림차순으로 정렬하기
sorted_df2 = df.sort_values('col2', ascending = False)
# 3) col2를 기준으로 오름차순, col1를 기준으로 내림차순으로 정렬하기
sorted_df3 = df.sort_values(['col2', 'col1'], ascending = (True, False))

7. Pandas 예제 - 잭이 심은 콩나무 데이터 정렬하기
잭이 심은 콩나무들의 키, 둘레, 열린 콩의 개수 데이터가 csv 파일(tree_data.csv)로 주어진다. 이 csv 데이터를 읽고, 정렬해서 height가 큰 순서대로 상위 5개 나무의 정보를 확인해보자.
→ 'height' 변수를 큰 순서대로 정렬하고, 상위 5개의 나무를 출력하시오
import pandas as pd
# csv 파일을 불러와서 tree_df로 저장하기
tree_df = pd.read.csv("./data/tree_data.csv")
# tree_df의 row 데이터의 갯수 확인
print("tree_df의 row 데이터 갯수 : ")
print(len(tree_df), "\n")
# 누락된 데이터의 여부 확인. 누락된 데이터는 제거하여 비교(dropna)
print("누락된 데이터 확인 여부 체크 : ")
print(len(tree_df.dropna()), "\n")
# height 값의 오름차순을 기준으로 데이터 정렬
tree_df = tree_df.sort_values('height', ascending=False)
# 오름차순으로 정렬된 데이터들 중 상위 5개만 출력
print("height가 큰 상위 5개의 나무 출력 : ")
print(tree_df.head(5))

- len(tree_df.dropna()
: tree_df 데이터프레임에서 누락된 데이터를 제거 후 그 갯수 출력
→ 원래 row 데이터의 수인 100개가 그대로 출력됨으로 누락된 데이터는 없다고 할 수 있다.
- tree_df.head(5)
: tree_df 의 상위 5개의 데이터를 추출하는 함수 (head)
→ iloc을 이용할 경우, tree_df.iloc[:5]
+) 정렬하고 추출한 새로운 DataFrame을 저장하고 싶다면? 괄호는 저장할 디렉토리
- tree_df.to_csv("./data")
'Data Analyst > Basic Python' 카테고리의 다른 글
| Matplotlib 데이터 시각화, 꼭 알아야 할 이론부터 실습까지! 총정리! (0) | 2023.09.29 |
|---|---|
| Pandas 함수 활용법! - 조건검색, 함수로 데이터 처리 등 심화학습! (2) | 2023.09.26 |
| [python] 데이터 분석의 기초! Numpy의 간단 총정리+실습! (0) | 2023.08.30 |
| [python] 파이썬의 핵심, 객체와 클래스란? 실습을 통해 공부하자! (0) | 2023.08.05 |
| [python] 파이썬에서 꼭 알아야 할 모듈과 패키지의 사용법과 실습! (0) | 2023.08.02 |




댓글