[파이썬 확률 통계] 시각화를 통한 데이터 요약하는법! 이론과 실습!
728x90
반응형
파이썬을 통해 데이터를 분석하고 입맛에 맞게 다루기 위해
필요한 기초적인 통계학을 학습해보자!

0. 통계란?
많은 데이터들에 대한 "해석하고 정리 및 요약"하는 작업을 통계라고 칭한다.
이제부터 아래의 순서대로 파이썬을 활용한 통계학을 학습할려고 한다.
(시각화를 통한 자료의 요약 - 논리적인 자료의 요약 - 확률 - 가설검정 및 추론)
기본적으로 통계학적인 내용을 다루어서 데이터들이 의미하는 특징을 찾아보고, 이를 텍스트 혹은 숫자로 표현할 뿐만 아니라 그래프로 시각화하는 것이 첫번째 목표이다.
이 때, 크게 "시각화를 통한 자료의 요약"과 "논리적인 자료의 요약"으로 나누어서 데이터를 이해할 필요가 있다.
→ '시각화'라는 것은 그래프나 그림을 통해서 자료들의 특징을 살펴보고 '논리적인'이라는 것은 많은 데이터들을 나타낼 수 있는 Feature(=모수)를 찾는 과정에서 나온다.
더불어 기존에 있는 명제(부정하기 어려운)에 대해 새로운 가설을 세우고 이를 논리적으로 증명하는 것이 "가설검정"이다. 이때 사용되는 여러 가지 확률분포와 통계적 가설검정하는 법에 대해 학습할 예정
→ 기본적으로 numpy, pandas, matplotlib을 포함한 파이썬 내 통계 패키지를 사용하며 학습
1. 자료의 형태
자료의 형태에는 크게 '수치형(Numerical) 자료'와 '범주형(Categorical) 자료'가 있다.

'수치형 자료'는 수치로 측정이 가능한 자료이며, '범주형 자료'는 수치로 측정 불가능한 자료로써 대표적으로 개와 고양이는 분류하는 예제가 있다.
→ 개와 고양이의 여러 사진들이 주어졌을때 각각 카테고리(=범주)에 나누어서 회귀 분석을 할 수 있다.
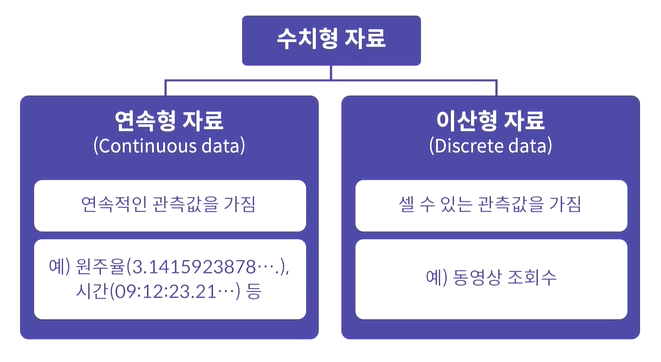
1) 수치형 자료
수치형 자료는 크게 연속형(Continuous) 자료와 이산형(Discrete) 자료로 구분할 수 있다.
→ 이산형 : 측정되는 각각의 값들이 일정 간격을 두고 떨어진 형태 (ex, 자연수, 물건 판매수)
→ 연속형 : 특정 구간 사이에 어떤 값이든 취할 수 있는 경우 (ex, 키, 몸무게 등)
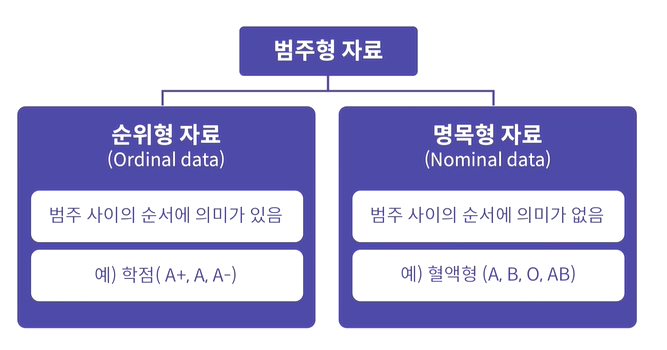
2) 범주형 자료
여러 데이터들이 카테고리로 분류할 수 있는 범주형 자료는 순위형(Ordinal) 자료와 명목형(Nominal) 자료로 나눌 수 있다. 명목형은 순서에 의미를 두지 않고, 순위형은 순서에 의미가 있는 자료를 의미한다. 대부분의 범주형 자료는 명목형 자료에 포함된다.
3) 자료의 형태 구분 시, 주의점
범주형과 수치형 자료를 구분할 때, 반드시 자료의 숫자 표현 가능 여부로 판가름되지는 않다.
→ 기본적으로 범주형 자료는 숫자로 표현되지 않으나, 사용자가 지정하여 숫자로 표기할 수 있기 떄문.
ex) 남녀 성별 구분 시 남자를 1, 여자를 0으로 표시
반대로 수치형 자료를 범주형 자료로 변환하는 경우도 있다.
ex) 나이나 건강상태(키, 몸무게 등)의 경우 특정 구간을 숫자로 구분

수치형 자료를 연속형과 이산형으로 구분할 때, 연속형은 연속적인 관측이 필요할 경우 구분
→ 시간, 몸무게 등으로 정확한 관측값은 찾아내기 어렵다.

반응형
2. 범주형 자료의 요약
범주형 자료의 경우, 다수의 범주가 반복되고 관측갑의 크기보다 포함되는 범주에 더 초점이 맞춰진다.
예를 들어, 선거 시즌에 후보자의 지지율에 대한 설문 조사를 할 때 개인이 후보자 A, B, C 중 누구를 지지하는지가 중요하지 해당 후보자를 얼마나 많이 지지하는지는 큰 의미는 없다.
→ 따라서 범주형 자료를 요약할 때는 각 범주에 속하는 관측값의 개수를 측정하게 된다.

관측하고자 하는 범주에 속하는 데이터의 개수를 파악함으로써, 전체 중 차지하는 각 범주의 비율과 범주 간의 차이점을 비교할 수 있다.
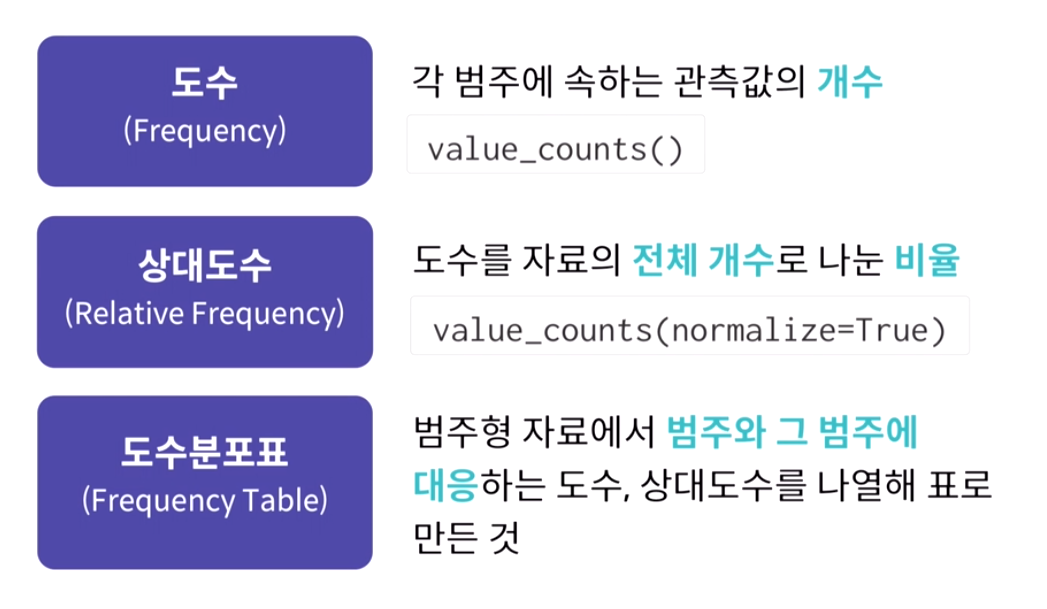
1) 도수분포표
도수(Frequency)란, 범주에 속하는 관측값의 개수를 의미한다.
→ 범주별로 얼마나 많이, 깊게 속하는지는 크게 중요하지 않고 관측값들의 개수가 중요하다.
상대도수(Relative Frequency)란, 도수를 자료의 전체 개수로 나눈 비율
→ 즉, 후보자(A, B, C)에 대해 1000명 중 각각 500, 300, 200명이 지지할 경우 상대도수는 0.5, 0.3, 0.2가 된다.
도수분포표(Frequency Table)이란, 도수와 상대도수를 통해 표로 만들어진 것
# 계산하는 법!
1) 도수
→ df[범주].value_counts() : value_counts() 함수를 이용해서 도수를 구할 수 있다.
2) 상대도수
→ df[범주].value_counts(normalize=True) : 'normalize=True' 옵션을 주어서 상대도수를 구할 수 있다.
3) 도수분포표
: 도수분포표는 몇 개의 범주를 기준으로 둘 것인지에 따라 다양한 도수분포표를 만들 수 있다.
3-1) 한 가지 범주일 경우
→ pd.crosstab(index = 범주, columns = "count") : index로 설정한 범주에 해당하는 도수를 계산하여 제작
3-2) 두 가지 범주일 경우
→ pd.crosstab(index = 범주, columns = 또 다른 범주)
: pandas crosstab 함수 내 index에는 첫번째 범주를 넣고, columns에는 또 다른 범주를 넣어주면 된다.
그러면 설정한 범주들을 모두 만족하는 도수를 계산하여 도수분포표가 제작된다.
2) 범주형 자료의 요약 예제 (주량 내기)
A, B, C, D, E라는 5명이 주량을 가지고 서로의 주량이 세다고 우기고 있다. 하지만, 술자리에 참석한 횟수가 다들 달라서 공정한 대결을 할 수가 있는 상황! 아래 예제를 통해 연습해보자
Q1) 술자리에 참여한 빈도 데이터를 저장한 파일(drink.csv)을 참고하여 누가 제일 술자리에 자주 나왔는지 확인해보자! (Attend : 참석한 경우 1, 참석하지 않은 경우 0)
Q2) 1번에서 구한 도수를 통해 상대도수를 계산해보자 (전체에서 도수의 비율 계산)
Q3) 구한 도수를 통해 도수분포표를 만들어보자
→ A, B, C, D, E의 전체 참석 횟수를 확인하고, 개인별로 몇 번 참석했는지에 대한 분포표를 출력해보자
import pandas as pd
import numpy a np
# drink 데이터 불러오고 출력
drink = pd.read_csv("drink.csv")
print(drink)
# 도수 계산
drink_freq = drink[drink["Attend"] == 1]["Name"].value_counts()
print("도수 계산")
print(drink_freq, "\n")
# 상대도수 계산
drink_relfreq = drink[drink["Attend"] == 1]["Name"].value_counts(normalize=True)
print("상대도수 계산")
print(drink_relfreq)
# 전체 참석 횟수를 확인하는 도수분포표
drink_tab = pd.crosstab(index = drink["Attend"], columns = "count")
print("전체 참석 횟수를 확인하는 도수분포표")
print(drink_tab, "\n")
# 누가 몇 번 참석했는지 확인하는 도수분포표
drink_who = pd.crosstab(index = drink["Attend"], columns = drink["Name"])
print("누가 몇 번 참석했는지 알 수 있는 도수분포표")
print(drink_who)


도수는 단순히 빈도 수만 세어주면 되기 때문에, 참석한 인원(Attend = 1)를 group화 시킨 후에 그 사람들의 참석한 횟수를 counting 해주면 끝!
※ 도수분포표는 pandas의 crosstab() 함수를 이용하여 만들 수 있고, index에는 행을, columns에는 열을 각각 지정해주면 된다.
- drink_tab = pd.crsstab(index = drink["Attend"], columns = "count")
: 참석 여부(Attend)를 index로 설정하고, columns에는 'count'라는 옵션을 넣어줌으로써 참석자들의 수를 셈
→ 실행 결과에서 '0'은 참석하지 않은 횟수, '1'은 참석한 횟수로 13번 참석하지 않고 12번 참석함
- drink_who = pd.crosstab(index = drink["Attend"], columns = drink["Name"])
: 개인별로 몇 번 참석했는지 확인하는 코드
3. 범주형 자료의 요약 및 실습 - 그래프
통계 영역에서는 그래프로 시각화함으로써 데이터들의 특징들을 해석하고 쉽게 보여주는 것이 매우 중요하다.
1) 원형그래프(Pie chart)
→ plt.pie(수치, labels = 라벨)
: matplotlib 내 pie 차트 출력. 각 영역별 수치와 라벨 지정

원형 그래프는 숫자의 나열보다는 전체적인 분포를 이해하기 쉬운 그래프이다.
즉, 장점으로 전체에서 해당 범주가 차지하는 비율을 파악하기 쉽지만 단점으로는 범주 간의 도수 비교 및 도수 크기 차이를 파악하기에는 다소 어려울 수 있다.
2) 막대그래프(Bar Chart)
→ plt.bar(x = 라벨, height = 수치)
: plt.bar() 함수를 통해 시각화하고, 라벨을 지정하고 막대차트의 높이(=크기)로 값을 넣어준다.

막대 그래프는 각 범주에서 도수의 크기를 막대로 표현된 차트로 x축은 범주, y축은 도수에 대한 눈금.
장점으로는 각 범주가 가지는 도수의 크기 차이를 비교하기 수월하지만, 각 범주가 전체에서 차지하는 비율을 비교분석하기에는 다소 어렵다.
3) 그래프 통계 실습 (원형, 막대)
앞서 술자리 참석 빈도와 상대도수 비율을 한 눈으로 비교하기 쉽도록 그래프로 시각화해보자.
→ labels, ratio 데이터 참고
import matplotlib.pyplot as plt
# 술자리 참석 상대도수 데이터
labels = ["A", "B", "C", "D", "E"]
ratio = [33, 25, 17, 17, 8]
# 원형 그래프
fig, ax = plt.subplots()
# Q1. 원형 그래프를 만드는 코드 작성
plt.pie(ratio, labels = labels)
plt.axis("equal")
# Q2. 막대 그래프 코드
plt.bar(labels, ratio)
# 그래프 출력
plt.show()

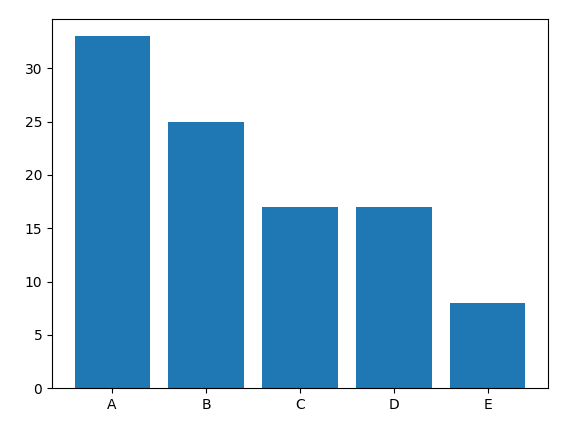
- plt.axis("equal") : pie 차트의 모양을 타원형에서 원형으로 교정해주는 역할 수행
→ "equal" 옵션을 넣지 않으면 완전한 원형이 아닌 타원형으로 출력됨
- plt.show() : 생성한 그래프를 보여주는 역할
4. 수치형 자료 요약의 요약
수치형 자료는 연속형과 이산형으로 나눌 수 있고, 그 중 이산형 자료 요약하는 부분을 먼저 보면,
이산형 자료는 관측된 수치 자료가 정확하게 셀 수 있는 경우에 해당한다. (ex, 판매된 자동차 대수 등)
이 때, 관측값의 종류가 많으면 범주형 자료 요약 기법(Pie, Bar)을 사용하고 그렇지 않으면(10~15개?) 연속형 자료 요약 기법(ex, stem_leaf)을 사용하는 것이 효율적이다.

연속형 자료는 관측값이 비교적 정확하지 않고 연속적으로 존재하는 경우에 해당하고, 관측값의 종류가 많으면 연속형 자료 요약 기법, 적다면 '점도표, 도수분포표, 히스토그램 등'을 사용하는 것이 좋다.
1) 점도표 (dot diagram)
점도표는 관측값의 개수가 상대적으로 적은 경우(20 or 25 이하)일 경우 사용한다.
→ 모든 자료를 나타낼 수 있도록 줄 위에 각 관측값에 해당되는 점을 찍어서 표시
→ 중복되는 값들은 해당 위치에 점들이 옆으로 퍼져서 출력됨
# 점도표의 특징
- 자료 전체의 개요를 파악하기 수월하다. (한 눈에 파악)
→ 어느 관측값에 많이 모여있는지 파악하기 쉽다.
- 연속형 자료의 경우 중복된 정보를 판단하기 어렵기 때문에 자료를 크기에 따라 묶어서 분석하는 것이 효율적
2) 도수분포표 (Frequency Table)
각 관측값에 대한 도수를 측정하여 도수분포표로 작성하여 분석할 수 있다.
→ 연속형 자료의 경우 다수의 구간(계급)으로 나누고 각 구간마다 관측값의 개수(도수)로 작성하여 표로 나타냄


3) 히스토그램 (Histogram)
히스토그램은 막대그래프와 유사하며 x축은 계급, y축은 빈도를 의미한다. 많은 데이터들을 히스토그램을 그리는 함수 안에 넣어주면, 아래와 같이 출력된다. (Label을 지정할 수가 있다.)
→ plt.hist() 함수 사용


# 히스토그램의 특징
- 자료의 분포를 알 수 있음
- 계급 구간과 막대의 높이를 그려준다
- 모든 계급구간의 폭이 같으면 도수, 상대도수를 막대높이로 사용된다.
4) 도수다각형
위의 히스토그램을 응용하여 아래와 같이 도수다각형 그래프를 그릴 수도 있다.
→ 검은색 실선이 히스토그램이고 해당 꼭짓점들을 이으면 도수다각형이 된다. (보라색)
→ 여러 자료들을 비교하기 위해서는 도수다각형이 더 좋다.
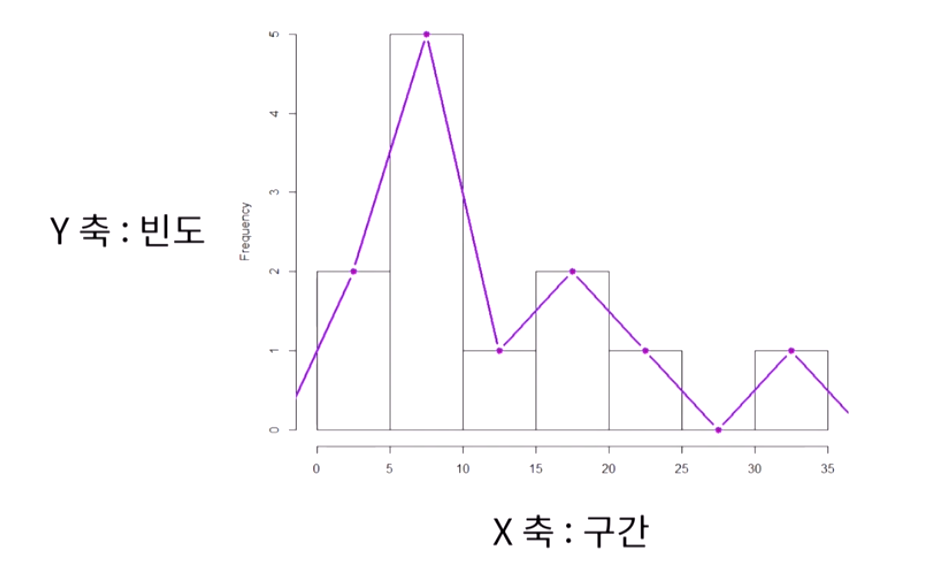
# 도수다각형의 특징
- 각 계급구간의 중앙에 점을 찍어 직선으로 연결한 형태
- 관측값의 집중된 위치, 정도, 치우친 정도, 꼬리의 두터움 등 분포의 상태를 쉽게 파악
- 관측값의 변화에 따라 도수 또는 상대도수의 변화를 잘 나타냄
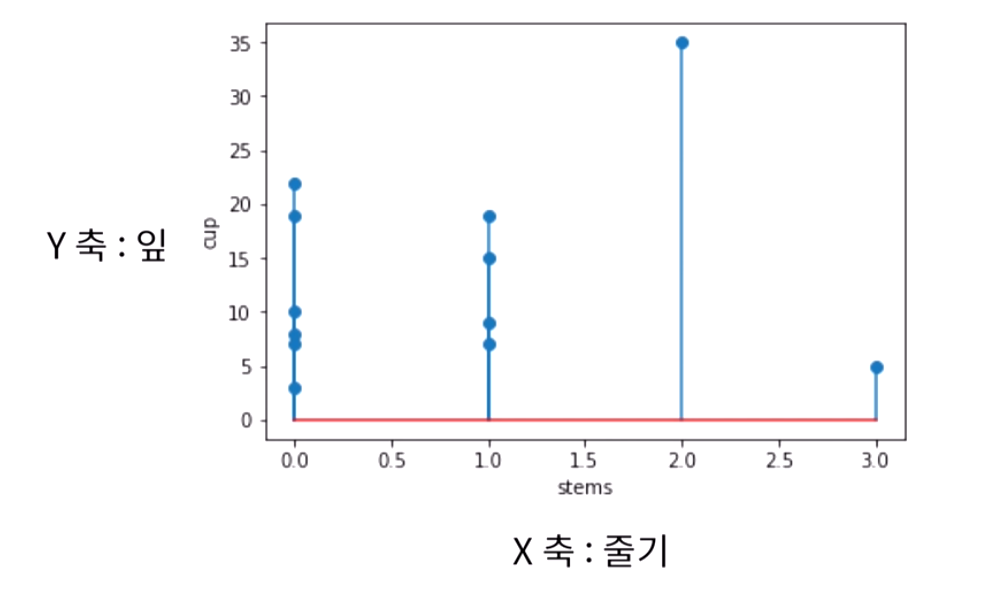
5) 줄기-잎 그림 (step-leaf Diagram)
Step-leaf Diagram은 자료(=데이터)의 갯수가 많지 않을 경우 주로 사용된다.
숫자 중 앞 단위를 줄기, 뒷 단위를 잎으로 생각하면 쉽다.
ex) 2, 5, 10, 12, 15, 17, 21, 27, 35 ...
→ 0 | 2 5
1 | 0 2 5 7
2 | 1 7
3 | 5
→ 뒷 단위를 잎으로 하여 관측값을 앞 단위 오른쪽에 오름차순으로 기입한다.

# 줄기-잎 그림의 장단점
- 장점
1) 관측값을 보여주므로 최댓값, 최솟값 등의 위치 파악이 쉬움
→ Bar, Histogram, pie의 경우 값 자체가 아닌 구간에 속해있는 도수(count 수)만 보여줌
2) 순서대로 배열된 관측값의 장점과 히스토그램의 장점을 모두 가지고 있음
3) 그리기 쉬움
- 단점
1) 관측값의 개수가 많은 경우 제한된 공간에 그리기 불가능
2) 관측값이 지나치게 흩어져 있으면 부적절
'Data Analyst > Basic Python' 카테고리의 다른 글
| [파이썬 통계] 사건과 조건부확률 & 확률분포 응용하는 법! (0) | 2023.11.06 |
|---|---|
| [파이썬 통계] 데이터를 논리적 수치로 해석하는 법! (대표값, 퍼진정도 등) (0) | 2023.11.06 |
| [Kaggle 데이터분석] 월드컵 경기 데이터의 다양한 속성 분석해보기! 실습! (0) | 2023.09.30 |
| Matplotlib 데이터 시각화, 꼭 알아야 할 이론부터 실습까지! 총정리! (0) | 2023.09.29 |
| Pandas 함수 활용법! - 조건검색, 함수로 데이터 처리 등 심화학습! (2) | 2023.09.26 |




댓글