(머신러닝) Overfitting은 꼭 해결해야되는 문제일까?
728x90
반응형
머신러닝의 목표는 training dataset을 이용하여 모델을 학습하고, 학습된 모델을 이용하여 관측되지 않았던 새로운 데이터에 대해 예측을 수행하는 것이다. 따라서 training set에 포함되지 않은 데이터들을 test set으로 구성하고, 이 test set에 대해 모델의 성능을 측정함으로써 새로운 데이터에 대한 모델의 성능을 평가한다.
→ 따라서 머신러닝 모델은 train set만을 가지고 test set에 대한 정확한 예측이 가능하도록 training하게 되는데, 이 과정에서 overfitting이 일어나게 되고, 일반화를 위한 모델의 경우 이를 방지하지만 오히려 overfitting이 필요한 경우가 있을 수 있다.
모델 학습하면서 종종 발생하는
Overfitting 꼭 해결해야되는 문제일까?

1. Underfitting(과소적합) & Overfitting(과적합)
머신러닝 모델은 training에 대한 손실 함수(loss function)가 작아지도록 학습을 진행하기 때문에 classification 문제의 경우, 아래와 같이 모델의 decistion boundary는 training set에 적합(fitting)하게 된다.

하지만, 모델이 training set에 너무 과하게 적합(overfitting)되면, 모델이 데이터에 내재된 구조나 패턴을 일반화한 것이 아니기에 올바른 학습 결과인지는 생각해볼 필요가 있다는 것은 맞다.

따라서 위의 그림과 같이 test 데이터에 대해 training data가 조금은 덜 적합된 모델이더라도, 실제로는 더 높은 정확도를 보일 수가 있다.

- 왼쪽 구간 : 학습 오차(training loss)와 테스트 오차(test loss)가 같이 감소하는 구간
→ Underfitting(과소적합)
- 오른쪽 구간 : 학습 오차는 감소하지만, 테스트 오차는 증가하는 구간
→ Overfitting(과대적합)
1. Fitting
Fitting의 의미는 무엇일까?
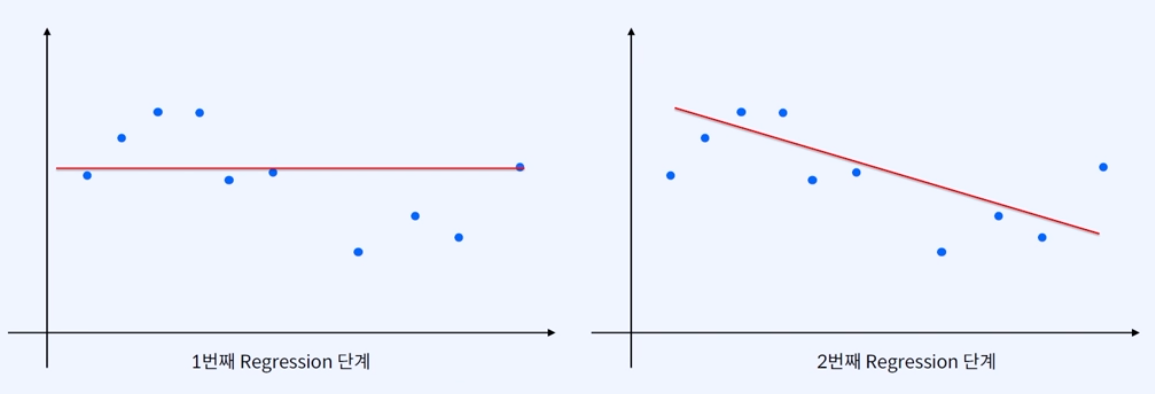
위와 같이 2차원의 데이터들이 주어지고, regression 문제를 해결하고자 할 때 regression line은 여러가지로 그려질 수 있다. 여기서 얼마나 fit 한지는 데이터와 regression line과의 distance를 구해서 더하고, 곱하고 나눠서 에러(Error)를 구한 다음, 그 에러를 줄여나가면 점차 적합한 line을 만들어낼 수 있다.

그렇다면, polynomial regression 결과 가상의 regression line이 위와 같다면?
에러는 '0'이 나오는데 이게 최선의 모델일까?
→ 이번 모델은 '일반화되지 않은 모델'이라고 표현할 수 있다.
2. Overfitting은 반드시 문제일까?
많은 사람들이 Overfitting은 '해결해야 할 문제'라고 말하는 경우가 있지만, 꼭 그렇지만은 않다.
→ 본인이 일반화된 모델을 만들 것인지, 특화된 모델을 만들 것인지에 따라 다르다.
→ 즉, 어떤 특정 모델에서는 Overfitting이 적절하게 필요할 수 있다.
예를들어 공장 라인에서 몇 천만개의 제품을 만들어내는데, 불량이 잘 나오지도 않는 상황에서 general한 모델로 적용할 경우, 양품도 불량이라고 판정하는 경우가 간혹 있을 수 있다.
→ 이 경우에는 Overfitting을 적절하게 시켜서 양품에 대한 데이터를 충분히 표현할 수 있는 모델을 적용할 수도 있다.
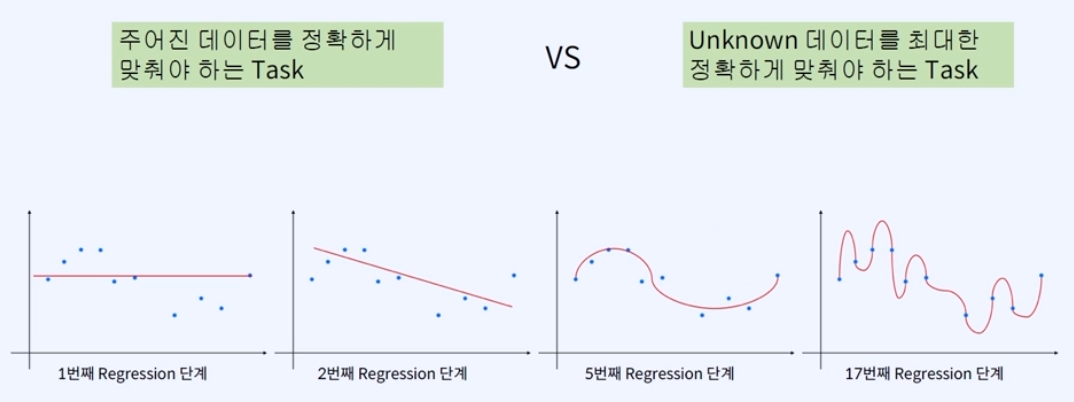
따라서 모델의 목적에 따라서 달라질 수 있다.
주어진 모델을 정확하게 맞춰야 하는 Task(의류, 우주 등)에서는 어느 정도 Overfitting이 필요하고, Unknown 데이터를 최대한 정확하게 맞춰야 하는 Task들에게는 general하게 모델을 생성해야 한다.
3. Underfitting → Overfitting
Underfitting에서 Overfitting으로 넘어가면?
- Step이 진행될수록 성능은 향상되지만, 그만큼 모델 복잡도는 증가하게 된다.
- 그럼 모델 복잡도가 증가하면,
→ 학습 데이터에 대한 성능은 계속 좋아지고
→ Unknown 데이터에 대한 성능은 계속 나빠지게 된다.
학습 참고
- 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE (패스트캠퍼스)
- 블로그(https://untitledtblog.tistory.com/158)
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) 학습된 모델을 평가하는 척도는 어떤 것이 있을까? (0) | 2024.03.01 |
|---|---|
| (머신러닝) 쉽게 이해하는 Cross Validation. 기법과 원리는? (0) | 2024.03.01 |
| (머신러닝) 데이터를 'Train, Validation, Test'로 나누는 이유는? (2) | 2024.02.28 |
| (머신러닝) Clustering이란? K-means 알고리즘 원리 간단 정리! (2) | 2024.02.27 |
| (머신러닝) Classification(분류)에 대해 정확히 알고 가자 (1) | 2024.02.27 |




댓글