(머신러닝) Classification(분류)에 대해 정확히 알고 가자
728x90
반응형
이번 게시물을 통해서 흔히 많이 들어본 Classification(분류)에 대한 기본적인 개념과 알고리즘의 원리 및 종류를 간단히 알고, binary classification이 무엇이고 우리가 당면한 문제가 binary classification인지 multiclass classification인지를 판단하고, 이를 어떤 방법으로 풀 수 있는지 살펴보자.
Classification(분류)란?
분류 알고리즘의 원리와 binary classification에 대해 알아보자
1. Classification?
1) Definition
Regression이 데이터를 가장 잘 표현할 수 있는 함수를 찾는 방법이라면, Classification은 데이터를 가장 잘 나누는(=분류하는) 함수를 찾는 방법이다.
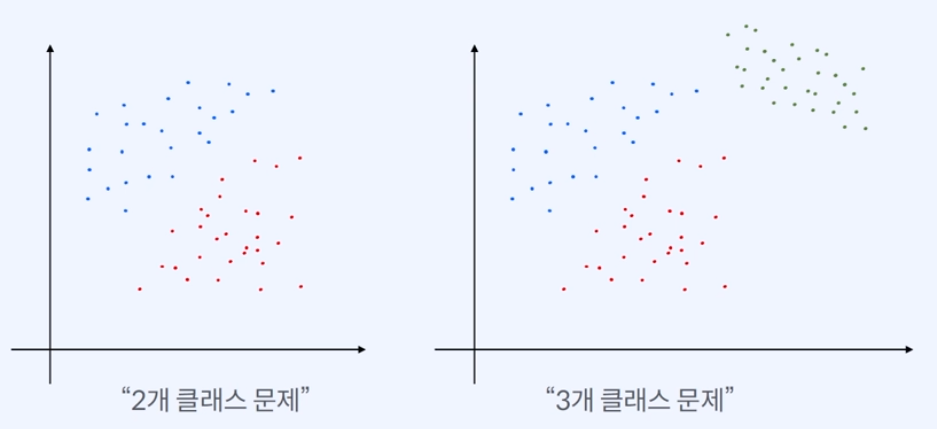
위 왼쪽 차트에는 2개의 클래스를 가진 데이터에 대한 차트로 빨간색과 파란색으로 클래스로 나눌 수 있다. (=Binary Classification), 오른쪽 차트는 초록색 클래스가 추가되어 총 3가지로 분류할 수 있다. (=Multi-class Classification)
이처럼 Classification은 데이터의 클래스들이 2~3개 등이 있을 때 클래스로 잘 나누는 함수를 찾는 방법을 말한다.
2) 이러면 잘 나눠진걸까?
아래의 두 개의 차트 중 어떤게 분류를 더 잘 했다고 할 수 있을까?
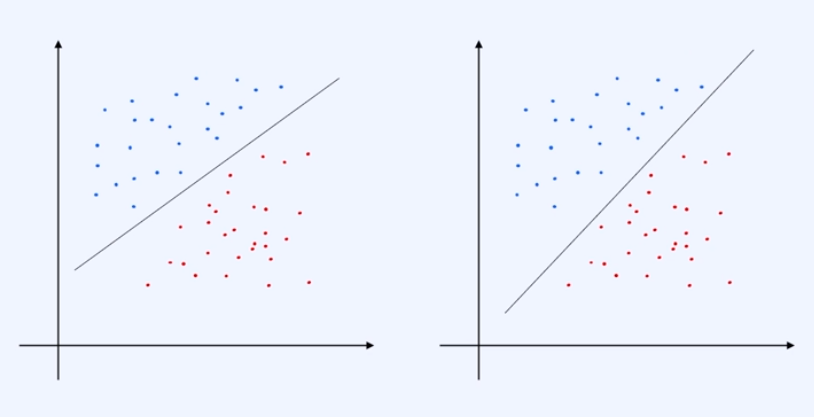
선의 양상이 미묘하게 다를뿐 데이터는 잘 나누었지만, 만약 새로운 데이터가 들어온다면?
→ 새로운 데이터에 따라 Classification의 성능도는 100% 확신하기는 어렵다
3) 제일 좋은 분류 경계는?
'제일 좋은 분류 경계'라는 것이 존재할까?
분류하는 선들 중에서 어느 선이 제일 좋을지, 그것을 결정하는 방법에는 뭐가 있을까?

새로운 데이터가 들어오면 설정한 분류경계를 평가할 수 있는데, 위와 같이 새로운 데이터가 빨간색 영역에 해당하는 것 같지만 현재의 분류 경계 기준에서는 파란색 클래스로 분류될 수가 있다.
→ 계속 분류작업을 거치면서 최적의 분류 경계를 찾아내는 과정을 거치게 된다.
따라서, Classification이란 데이터를 가장 잘 나눌 수 있는 최적의 분류 경계를 찾는 방법이라고 볼 수 있다.
반응형
2. SVM (Support Vector Machine)
1) SVM이란?
Classification에는 다양한 방법들이 있는데, 그 중에서 요즘은 잘 쓰이지는 않아도 Classification의 개념을 잡기 위해서 유용한 방법에는 'SVM(Support Vector Machine)'이 있다.
- SVM은 Binary classification 문제에 좋은 성능을 보이는 알고리즘으로, 2개 클래스의 데이터를 가장 잘 나눌 수 있는 경계를 찾는 알고리즘이다.
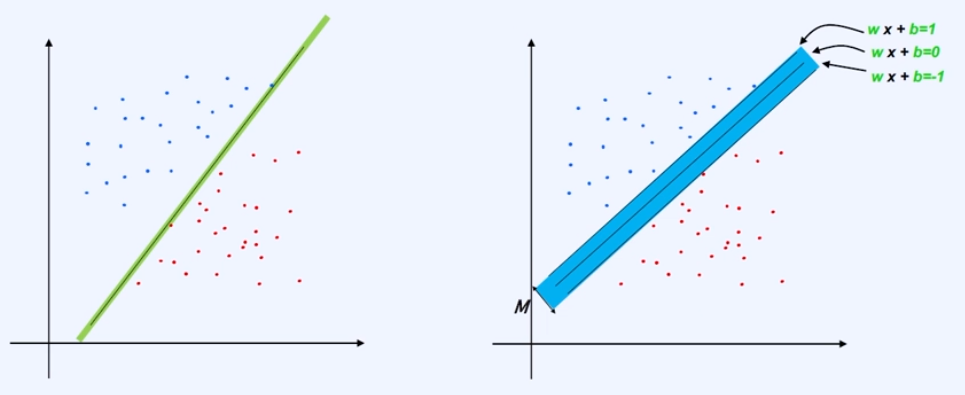
- SVM 알고리즘에서는 경계선의 너비(Margin)가 넓은 모델이 성능이 우수한 모델로 판정한다.
위의 왼쪽 차트 내 경계선을 기준으로 파란색과 빨간색의 데이터가 너무 가까이에 있으므로, 그만큼 경계선의 너비가 좁을 수밖에 없다. 반면 오른쪽 차트는 경계선과 데이터 간 거리가 비교적 길기 때문에 너비가 더 넓다고 볼 수 있다.
→ 경계선에서 가장 가까운 점을 'Support Vector'라고 한다.
알고리즘은 처음에 경계선이 설정되면 데이터 간 경계서에서 가장 가까운 Support Vector를 구하고 그 거리(residual)으로 수식을 생성한다. 그리고 그 수식에서 너비(=margin)이 최대가 되는 모델을 찾는 과정이다.
2차원의 데이터에서는 위와 같이 간단하지만, 실제 데이터에서는 다차원에서 데이터를 처리해야 하는 경우가 많다. 그래서 최근까지 PCA과 같은 Feature Selection 등의 차원을 축소하는 방법들을 활용해서 2차원으로 표기를 하고, 이를 바탕으로 시각화 및 알고리즘 적용을 하기도 한다.
→ 다차원의 데이터를 2차원으로 매핑(mapping) 하게 되면, 사람들이 이해하기 쉽게 시각화하기 용이하다.
→ 데이터 분석을 할 때, 차원이 늘어날수록 원하는 데이터를 뽑아낼 수 있는 여지는 많아지지만 연산이 오래 걸리게 된다. 그리고 그만큼 성능도가 떨어질 수 있다(차원의 저주). 이때 SVM은 Kernel trick을 통해서 이를 해결할 수 있다.
2) Multiclass classification
Multiclass classification은 결국 binary classification을 확장한 개념이다. 그럼 어떻게 확장할까?
ex1) A, B, C 중에 A가 아닌 나머지로 분류를 1번, B가 아닌 나머지 그리고나서 C로 분류
→ 겹치는 교집합에 해당되는 데이터는 횟수에 따라서 클래스를 결정하는 알고리즘이 있다.
ex2) 각 클래스별로 가중치를 따로 계산한 값을 기준으로 경계선을 분류

무엇보다 기본적으로 가장 중요한 것은 binary classification이 무엇이고 우리가 당면한 문제가 binary classification인지 multiclass classification인지를 판단하고, 이를 어떤 방법으로 풀 수 있는지 숙지하는 것이다.
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) 데이터를 'Train, Validation, Test'로 나누는 이유는? (2) | 2024.02.28 |
|---|---|
| (머신러닝) Clustering이란? K-means 알고리즘 원리 간단 정리! (2) | 2024.02.27 |
| (머신러닝) Regression 회귀 분석에 대해 정확히 알아보자 (0) | 2024.02.27 |
| (머신러닝) Supervised vs Unsupervised Learning 간단 정리 (0) | 2024.02.27 |
| (머신러닝) Data Cleaning과 Sampling 샘플링 기법 총정리! (1) | 2024.02.27 |




댓글