(머신러닝) 데이터를 'Train, Validation, Test'로 나누는 이유는?
728x90
반응형
Train, Validation, Test data에 대해 학습하고, 데이터를 왜 나누는지도 정확히 알아보자
Train / Validation / Test
데이터를 어떤 목적으로 나누는 걸까?

1. Train / Test
1) 어떻게 좋은 모델을 선택할까?
regression, classification 등의 많은 시도 끝에 '어떻게 좋은 모델을 선택할까?' 라는 질문은 마지막까지 계속 생기게 된다. 하지만, 그 과정에서 전체 데이터를 어떻게 나누고 어떤 순서로 성능을 측정하는지 알아보자

# 데이터 성능도 측정 프로세스
1. 전체 데이터를 Train 데이터와 Test 데이터로 나눔
→ Train 데이터와 Test 데이터는 겹치는 부분이 있으면 안됨
→ 둘은 가능한 최대한 독립적인 관계를 갖는 것이 좋음
2. Train 데이터를 이용해서 다양한 모델 생성
3. Test 데이터를 이용하여 생성된 모델 검증
4. Test 데이터에서 가장 좋은 성능을 보인 모델 선택
2) 프로세스별 도식화
위에서 확인한 성능도 측정하는 프로세스를 도식화한 예시가 아래 있다.
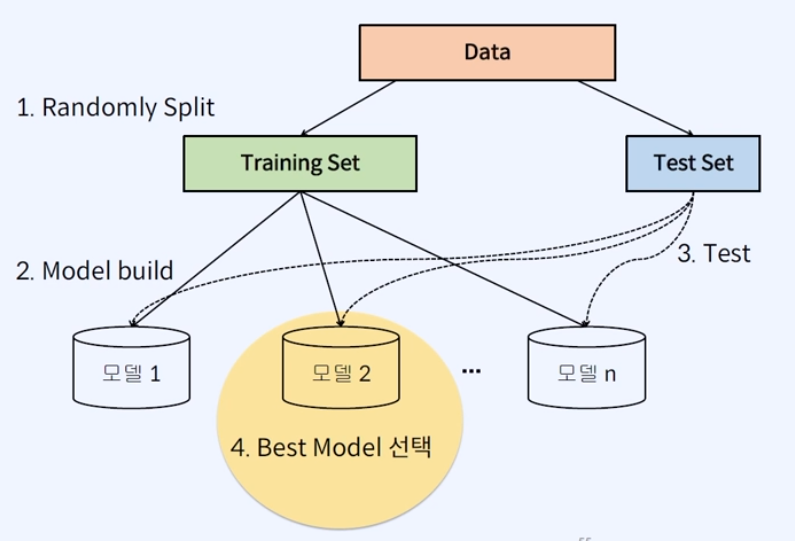
# Randomly Split
: 먼저 데이터를 Random하게 Train과 Test를 7:3 혹은 8:2 정도로 쪼갠다(split)
# Model build
: training set을 바탕으로 모델을 n개를 만들고 test set을 넣어서 성능도를 측정한다.
→ 성능도가 가장 높은 모델에 대해서 배포를 하게 된다.
3) Test Loss
- Train 데이터로 모델을 만들때는 성능 괜찮았는데.. Test 데이터에서는 안 좋네..?
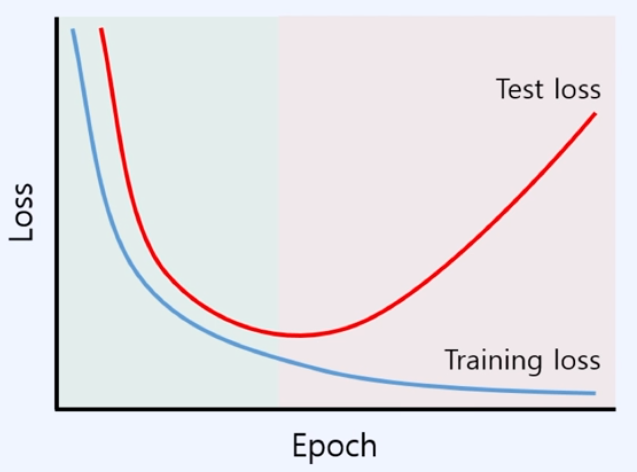
위의 예시 차트와 같이 Training Losss는 계속 0에 가깝게 수렴하지만, 어느 순간부터 Test Loss는 도중에 다시 높아지는 구간이 온다.
이같은 경우는 training set에 대해서만 중점적으로(oriented) 학습되어서 실제 Test Loss가 다시 높아지게 된다.
→ 따라서 학습(training)이 될 때, 이 모델이 잘 학습되고 있는지도 검증을 해야 한다. → " Validation "
# Train과 Test로만 나눈다면?
- 적절한 Test 크기 : 전체 데이터의 30~50% 정도
- 장점 : 단순해서 직관적으로 이해할 수 있음. 구현하기 쉬움
- 단점 : Test 데이터는 모델 생성에 사용되지 않고, 데이터가 무작위로 나눠짐
→ 이 경우, 데이터를 어떻게 나뉘냐에 따라 검증 결과가 많이 다르다.
→ 데이터의 distribution(분포)를 예상해야 되는데 이러면 정확히 분석하기 어려워진다.
반응형
2. Train / Validation / Test
1) Validation Set이란?
Train과 Test로만 나누는 방식의 한계점을 보완하기 위해 'Validation'을 추가하는 방법을 도입하게 된다.

- Random하게 데이터를 쪼개는 단계에서 데이터를 총 3개로 나누는 것이다.
→ Training set(학습), Test set(테스트용), Validation set(학습과정에서 검증용)
- Training set으로 모델을 만드는 과정에서 Validation set으로 Overfitting 여부 등의 성능을 검증하면서 모델을 생성한다.
→ 그리고나서 생성된 모델에 대해 Test set으로 정확한 성능도를 테스트하게 된다.
통상적으로 Validation Set에서 모델의 성능이 안 좋아지는 시점과 Test set에서 성능이 안 좋아지는 시점이 거의 동일하기 때문에 Validation Set만 있어도 학습과정에서 Test set의 결과가 어떻게 나올지 대략 유추해볼 수 있다.
2) Validation 추가
Validation set에서 성능이 안 좋으면 학습을 멈추면 된다?
→ Test Loss가 다시 올라가는 지점과 Validation Loss가 올라가는 지점이 유사
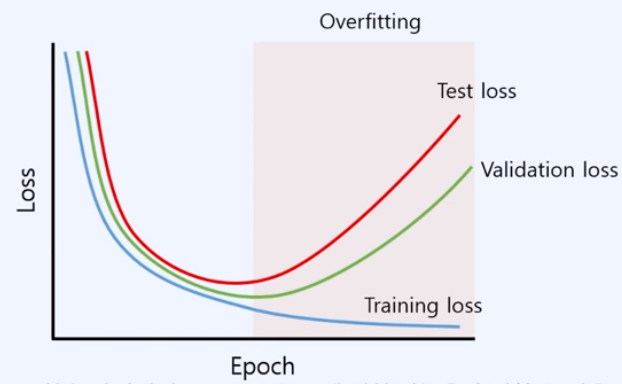
- 학습 과정에서 Unseen data에 대한 성능을 측정할 수 있음
- 학습 과정에서 Overfitting에 대해 감지할 수 있음
→ 'Early Stop' 가능
→ Training loss는 계속 낮아지는데, Validation loss가 높아지거나 더이상 낮아지지 않는 지점에 학습 종료
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE (패스트캠퍼스)
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) Overfitting은 꼭 해결해야되는 문제일까? (0) | 2024.03.01 |
|---|---|
| (머신러닝) 쉽게 이해하는 Cross Validation. 기법과 원리는? (0) | 2024.03.01 |
| (머신러닝) Clustering이란? K-means 알고리즘 원리 간단 정리! (2) | 2024.02.27 |
| (머신러닝) Classification(분류)에 대해 정확히 알고 가자 (1) | 2024.02.27 |
| (머신러닝) Regression 회귀 분석에 대해 정확히 알아보자 (0) | 2024.02.27 |




댓글