(머신러닝) 쉽게 이해하는 Cross Validation. 기법과 원리는?
728x90
반응형
Cross Validation이란 무엇이고 기법의 원리는?

1. Cross Validation?
1) Definition
Cross Validation이란 결과에 대한 분산을 줄이기 위해 사용하는 기법이다.
ex) 성능 결과가 어떤거는 성능이 98%, 다른 거는 35% 등으로 들쭉날쭉하게 결과의 분산이 너무 크면 어떤 모델이 좋은 것인지 판단하기 어려워진다.
→ 'K-fold Cross validation'이 대표적으로 많이 사용된다.
Q) Cross Validation(교차 검증)이 필요한 이유?
: 만들어진 모델이 test set에만 잘 동작하는(=과적합, overfitting)되는 것을 해결하기 위해 필요하다
→ 고정된 test set을 가지고 모델의 성능을 확인하고 parameter를 수정하는 것을 반복하면 결국 모델은 test set에만 잘 동작하는 모델이 될 수 있고, 이런 현상(overfitting)으로 다른 실제 데이터로 예측을 수행하면 결과가 엉망일 수 있다.

# K-fold Cross validation
- 전체 데이터를 K개의 'fold'라는 개념으로 나눔
- train, validation, test data를 split() 함수를 통해 랜덤하게 데이터를 나누게 되는데, 어떻게 나누는지에 따라서 데이터의 분포가 달라지고 검증하기 어려운 경우가 있다.
- fold간 데이터는 서로 겹치지 않게 나눠야 함
2) Cross Validation 검증 과정
'test set'에 과적합(overfitting)되는 문제는 test set이 데이터 중 일부분으로 고정되어있고, 이 일부분의 Dataset에 대해 성능이 잘 나오도록 parameter를 반복적으로 튜닝하기 때문에 발생한다.
→ 이에 Cross Validation(교차 검증)은 데이터의 모든 부분을 사용하여 모델을 검증하고, test set을 하나로 고정하지 않는다.
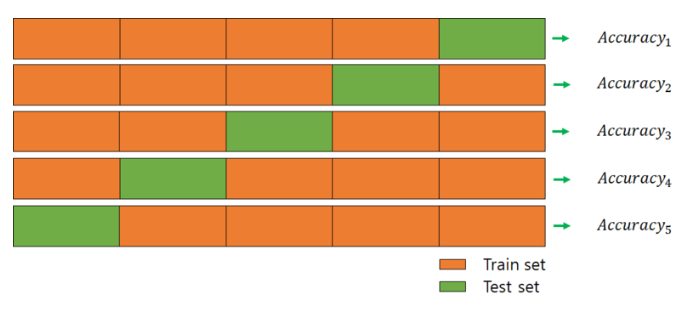
위의 예시와 같이 전체 데이터셋을 k개의 subset으로 나누고 k번의 평가를 실행하는데, 이 때 test set을 중복없이 바꾸어가면서 평가를 진행하게 된다.

다음으로 k개의 평가지표(ex, accuracy)를 평균 내어서 최종적으로 모델의 성능을 평가한다.
→ 여기까지 Cross Validation의 검증 과정
3) 4-fold Cross Validation & 동작원리
아래 예시로 4-fold cross validation을 보면서 조금 더 검증하는 과정을 익혀보자
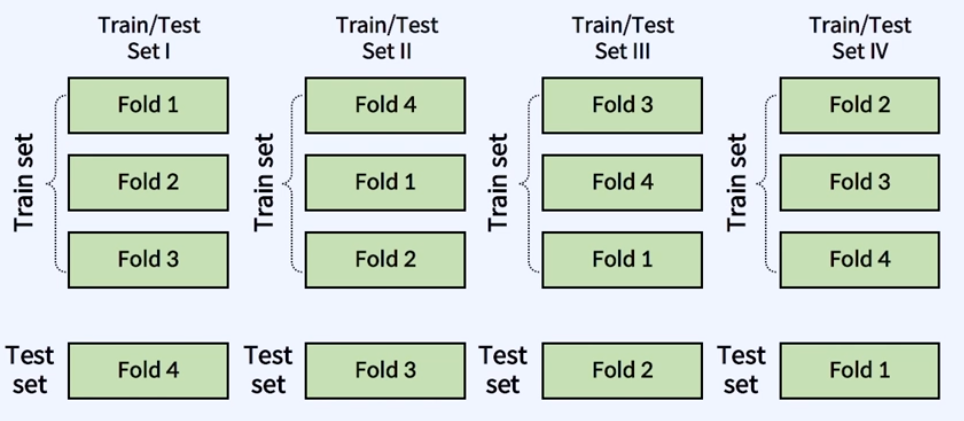
'4-fold'이기 때문에 fold를 4개로 나누고 set1에서는 1~3은 Train set, 4번째를 Test set으로, set2와 set3, 4 또한 각각 fold를 다르게 가져감으로써 fold마다 데이터의 특성이 겹치지 않도록 학습을 진행한다.
→ 즉, 데이터를 아주 잘 섞어서 모든 데이터에 대해서 검증할 수 있도록 한다.
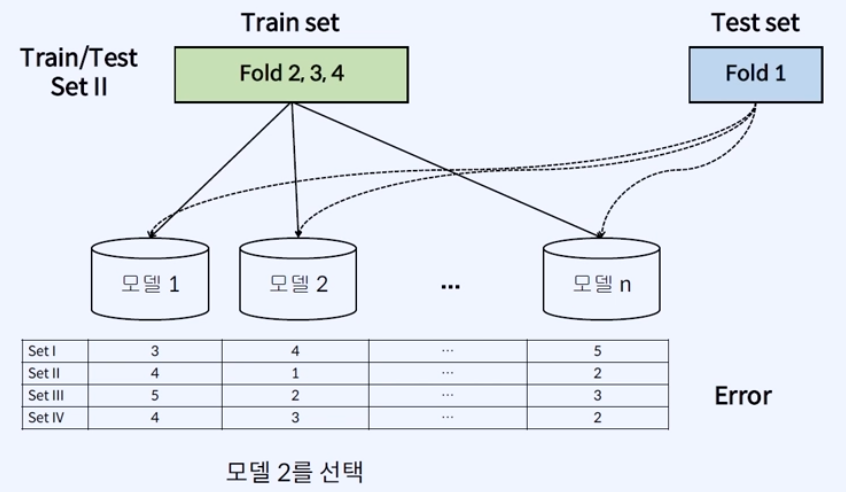
위의 예시는 'Set 1~4'에 대해서 각각 Fold를 train set과 test set으로 다르게 분할하여 학습시키고 성능도(=에러율)을 나타낸 것으로, 하나의 Set으로만 보면 모델의 에러율을 단면적으로만 볼 수 있지만, 종합적으로 검증해보면 그렇지 않다는 것을 알 수 있다.
→ 위에서는 '모델2'가 평균적으로 Error가 낮은 것을 확인할 수 있다.
→ 물론 평균으로만 모델을 선택하지는 않고, 데이터의 min, max를 보는 경우도 있을 수 있다.
# K 값을 변화하면서 성능도를 비교/분석할 수 있다.
→ 현업에서는 '10-fold'로 가장 많이 사용한다.
반응형
2. 다른 Cross Validation 기법
# StratifiedKFold
'StratifiedKFold'는 K-fold Cross validation에서 Label의 분포를 고려하지 않는 문제점을 보완한 Cross validation 기법이고, 현업에서는 더 자주 사용될 수 있다.

Class별 Label 분포를 고려하여 Fold를 나눠서 Fold별로 class의 불균형을 해결할 수 있다.
→ 위 사진에서 class가 많이 imbalance한 것을 확인할 수 있고, group index는 일정하다. 이러한 class의 불균형을 고려해서 fold를 나누는 원리이다.
3. Cross Validation의 장/단점
- 장점
1) 모든 데이터셋을 training과 test(평가)에 활용할 수 있다.
→ 특정 데이터셋에 Overfitting 되는 것을 방지할 수 있다.
2) 평가 결과에 따라 더 일반화된 모델을 만들 수 있다.
3) 정확도를 향상시킬 수 있고, 데이터 부족으로 인한 underfitting 방지할 수 있다.
- 단점
: Iteration 횟수가 많아지기 때문에 모델 training과 test하는데 시간이 오래 걸린다.
학습 참고
- 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE
- Wikipedia, "Cross-validation"
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) 학습된 모델을 평가하는 척도는 어떤 것이 있을까? (0) | 2024.03.01 |
|---|---|
| (머신러닝) Overfitting은 꼭 해결해야되는 문제일까? (0) | 2024.03.01 |
| (머신러닝) 데이터를 'Train, Validation, Test'로 나누는 이유는? (2) | 2024.02.28 |
| (머신러닝) Clustering이란? K-means 알고리즘 원리 간단 정리! (2) | 2024.02.27 |
| (머신러닝) Classification(분류)에 대해 정확히 알고 가자 (1) | 2024.02.27 |




댓글