(머신러닝) Data Cleaning과 Sampling 샘플링 기법 총정리!
728x90
반응형
이번 게시물에서는 'Data Cleaning'과 'Data Sampling'에 대해서 학습해보자.
→ Data Cleaning이란 무엇이고 왜 해야 되는 걸까?
→ Data Sampling은 왜 필요하고 상황별 어떤 기법을 사용해야될까?
Data Cleaning과 Data Sampling이란?
샘플링의 유형과 상황별 어떤 기법을 사용해야될까?

1. Missing Value
Data Cleaning이란 모델에 데이터를 넣기 전에 데이터를 쓸 수 있도록 만드는 프로세스를 말한다. Data Cleaning을 학습하기 전에 그 타겟인 'Missing Value'에 대해 알아야 할 필요가 있다.

- 실제 데이터에서는 N/A, Null 등의 이상값들이 존재한다 → Missing value 처리
→ N/A (Not Available) : 표현할 수 없는 값
→ Null : 공백이나 비어있는 값 (띄어쓰기 포함)
시스템 내 어떤 부분에 오류가 나거나 파이프라인의 어떤 부분에서 missing value가 생겨날지 예상하기 어렵기 때문에 로직을 만들때 missing value가 들어온다는 전제 하에 코드를 개발하면 안정성 ↑
- Zero 비율이 0.95 이상인 경우 → 분석에 의미가 있는지 재확인 혹은 Drop
- 독립변수(데이터의 Feature) 간 상관관계가 높은 경우 → 다중공선성 의심
# 다중공선성
: 공선성은 데이터가 서로가 서로에게 미치는 정도인데, 입력변수들 간의 높은 상관관계가 존재하여 회귀 계수의 분산을 크게 하는 특징
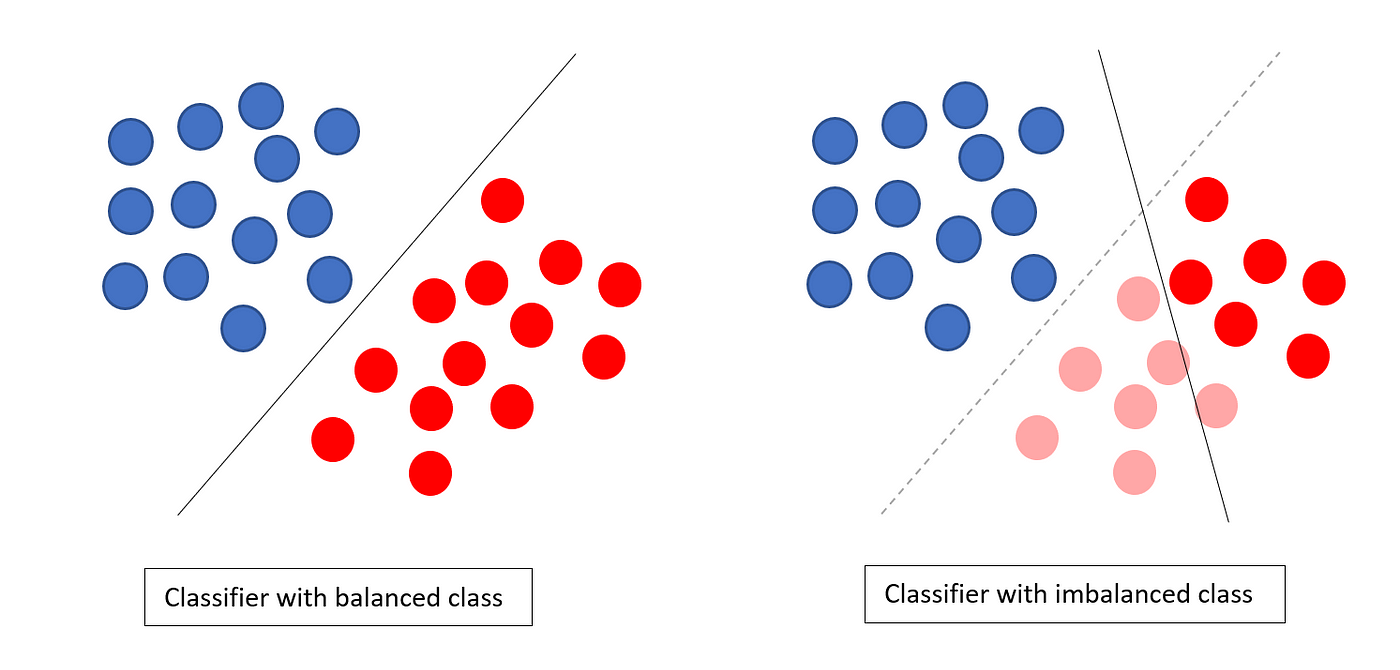
2. Class imbalance
현실에 있는 데이터들의 90% 이상은 imbalance하기 때문에 Class imbalance를 체크해야 한다.
ex) 2000만 고객이 있는 곳에서 하루에 특정 상품을 구매하는 고객이 50만명이라면?
→ 50만명이라는 수치는 크지만, 2000만의 고객과 비교하면 매우 imbalance하기 때문에 1950만명과 50만명을 모델링을 하게 된다면 모델 학습 결과는 당연히 '모두 구매하지 않음'이라고 나올 확률이 높다.
→ 이럴 경우 sampling 작업이 필요하다
- class imbalance 체크 → 비율이 '0.9' 이상인 경우 샘플링 고려
- Imbalance 데이터를 Drop하는 것보다 밸런스를 맞출 수 있는 방법을 사용하는 경우가 많다.
- 한쪽을 줄이거나 늘리는 방법보다는 실제 데이터의 분포를 유지하면서 데이터의 밸런스를 맞출 수 있는 방법을 적용해야 한다.
반응형
3. Sampling (샘플링)
먼저 sampling(샘플링)이란, 데이터들 중에서 몇 개를 추출한다는 의미이다. sampling에는 데이터를 적게 추출하하는 방법(Undersampling)이 있고, 많이 뽑아내는 방법(Oversampling)이 있다.
# Sampling이 필요한 이유는?
: 데이터가 inbalance하게 분포되어있을 때 데이터가 비교적 균등하게 분포되어 학습될 수 있도록 추출(sampling)이 필요하다. 데이터의 분포가 많은 쪽에서 Undersampling을 통해 줄이는 방법과 분포가 적은 쪽에서 Oversampling을 통해 늘리는 방법이 있다.
→ Undersampling과 Oversampling의 사용 판단은 데이터의 분포를 보고 판단하면 된다.
# Undersampling
- 데이터 내 클래스 비율이 Imbalance 할 경우, 타겟의 모수가 많은 쪽을 줄이는 기법
→ 잘못하면 데이터가 너무 적어질 수 있고 학습할 때 쓸 수 있는 데이터가 너무 적어 모델의 성능도가 떨어질 수 있다.
- Random, Near Miss, Tomek Links, ENN 등의 기법이 있다.
1) Random Undersampling
Random Undersampling은 지정한 종속변수(=target)의 Category 중 비율이 적은 Category를 기준으로 비율이 높은 Category의 데이터를 Random한 방법으로 제거

Random Undersampling만 할 경우, 성능이 좋지 않다. 따라서 이후에 통계값(평균, 분산, 표준편차 등)들을 확인해보면서 데이터 분포가 바뀌었는지 검토가 필요하다.
→ 만약 sampling 이후에 통계값들의 변동이 있다면 데이터 특성에 영향을 준 것이기 때문에 해당 기법으로 sampling을 하면 안된다. 반대로 변동없이 분포가 동일하다면 문제는 없다.
2) NearMiss Undersampling
NearMiss Undersampling은 Near-Miss 알고리즘을 사용하여 데이터를 제거하는 방법(근접한 데이터 제거)
→ 제거할 대상을 선정하기 위해 이웃한 근접 데이터 간의 거리를 계산하기 때문에 오래 걸림
→ 계산이 너무 오래걸리는 경우가 많아서 잘 안 쓰이는 기법

3) Tomek Links
Tomek Links는 데이터의 중심 분포를 거의 유지하면서 분류 경계를 조정하기 때문에 제거되는 샘플이 한정적이다. → Undersampling의 효과가 낮음
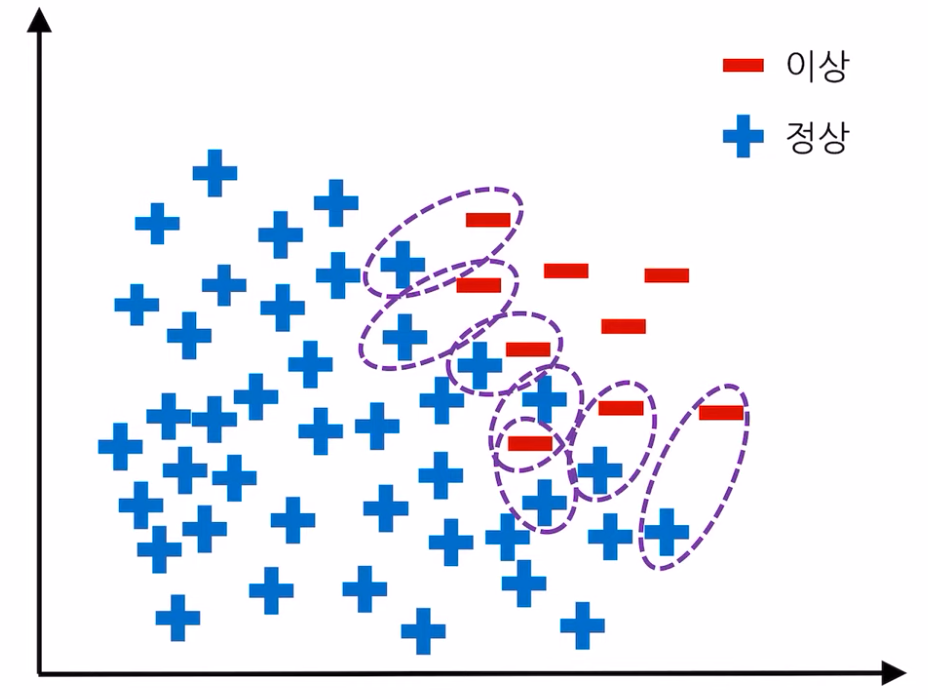
데이터 간 분류 경계에 있는 데이터들을 조정하기 때문에 경계가 뚜렷해지기 때문에 Classification 하기 수월해진다.
→ Undersampling의 효과가 떨어짐. 샘플링을 해도 데이터가 많이 줄어들지는 않는다.
4) ENN (Edited Nearest Neighbors)
ENN(Edited Nearest Neighbors)는 다수 클래스 데이터 중 가장 가까운(Nearest Neighbors) k개의 데이터가 모두 다수 클래스가 아니면 삭제하는 방법
→ 소수 클래스 주변의 다수 클래스 데이터는 삭제
→ 데이터 간 경계를 뚜렷하게 하는 효과가 있다. Undersampling의 효과가 떨어질 수 있음

# Oversampling
Undersampling과 반대로 데이터 내 클래스 비율이 Imbalance 할 경우, 타겟의 모수가 많은 쪽을 줄이는 기법이다.
→ Random, SMOTE 기법 등이 있다.
→ 데이터의 분포에 전혀 영향을 미치지 않지만, 샘플링 효과가 크게 좋지는 않다.
1) Random Oversampling
Random Oversampling은 Undersampling과 반대로 비율이 낮은 데이터를 Random으로 복제하여 데이터의 양을 늘리는 기법이다.

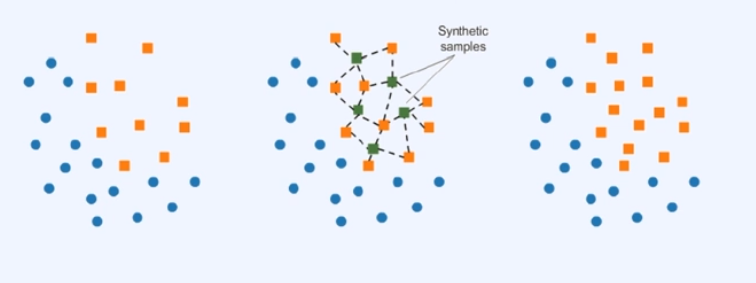
2) SMOTE(Synthetic Minority Oversampling Technique)
SMOTE는 무작위로 선택한 데이터에 KNN을 수행하고, 수행한 X(KNN, K-Nearest Neighbor)과 X의 사이에 위치한 가상의 데이터를 생성한다.
→ SMOTE는 비율이 낮은 데이터도 생성하지만, 높은 데이터도 생성할 수 있다.
# Combination
샘플링들의 각 기법들의 장점을 살려서 기법들을 혼합해서 사용할 수도 있다.
→ 실전에서는 한가지 방법(기법)으로만 시도되지 않는다.
→ SMOTEE, SMOTETOMEK 등의 기법으로 여러 기법을 혼합해서 사용하는 경우가 많다.
1) SMOTEENN
SMOTEENN은 SMOTE(Over)방법과 ENN(Under)를 조합한 기법이다.
→ SMOTE를 통해 소수 클래스 데이터를 Oversampling하고, ENN을 통해 다수 클래스의 데이터를 Undersampling하는 방법

2) SMOTETOMEK
SMOTE를 통해 소수 클래스 데이터를 Oversampling하고 TOMEK를 통해 다수 클래스의 데이터를 Undersampling하는 방법이다.
→ TOMEK의 특성으로 인해 결정 경계가 뚜렷해지게 된다.

★ 샘플링에는 정답이 없다.
→ 데이터의 분포를 얼마나 잘 유지하면서 데이터를 잘 다루냐가 정말 중요하고 관건이다.
→ 데이터의 분포가 바뀐다면, 데이터를 조작하는 것과 다를 바가 없다.
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE (패스트캠퍼스)
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) Regression 회귀 분석에 대해 정확히 알아보자 (0) | 2024.02.27 |
|---|---|
| (머신러닝) Supervised vs Unsupervised Learning 간단 정리 (0) | 2024.02.27 |
| (머신러닝) Feature Selection는 무엇이고 왜 꼭 알아야 하는 걸까? (1) | 2024.02.26 |
| (머신러닝) Feature Engineering의 종류와 기법 기초 정리! (1) | 2024.02.26 |
| 머신러닝(ML)으로 현업에서 해결할 수 있는 문제 유형 총 정리! (1) | 2024.02.25 |




댓글