머신러닝(ML)으로 현업에서 해결할 수 있는 문제 유형 총 정리!
728x90
반응형
본격적인 데이터 분석을 학습하기 전에 머신러닝으로 어떠한 문제점들을 해결할 수 있는지에 대해 살펴보자. 어떤 경우와 문제를 머신러닝 모델로 분석하고 해결할 수 있을까? 유형별로 확인해보자.
머신러닝으로 접근/해결할 수 있는 문제점들은?
1. Forecast (예측)
1) Forecast란?
머신러닝으로 분석할 수 있는 많은 문제들 중에 가장 대표적인 것은 'Forecast(예측)'
- 시간의 흐름에 따라 기록된 데이터를 이용하여 변수들간의 인과관계를 분석하여 미래를 예측하는 영역
→ Time series(시계열) 데이터 자체만으로 미래를 예측하는 영역
- 주 활용 영역은 날씨 예측, 주식 예측, 상품 판매량 예측 등
- 숫자가 존재하는 모든 영역에서 연구되고 구현되는 분야
- 대표적인 알고리즘은 AR(I)MA(아리마), DeepAR 등이 상용 수준으로 쓰이는 중
→ AR : Auto Regression의 약자로 자동으로 회귀를 해준다? 그게 아니고 스스로 회귀를 한다는 의미
→ MA : Moving Average의 약자로 이동평균의 의미한다.
즉, 이동평균을 통해 스스로 회귀분석을 하는 알고리즘
# ARMA
- AR : Auto Regression의 약자로 자동으로 회귀를 해준다? 그게 아니고 스스로 회귀를 한다는 의미
- MA : Moving Average의 약자로 이동평균의 의미한다.
→ 즉, 이동평균을 통해 스스로 회귀분석을 하는 알고리즘

2) 예시 - 기업 전력량 피크 제어용 예측 엔진
Forecast 영역에서는 다양한 변수를 활용한 시계열 예측이 지속적으로 발전하고 있는 추세
- 타겟 변수와 상관관계가 높은 변수를 활용
- 시계열 예측에도 Regression, Classification의 응용이 사용됨
# example) 기업 전력량 피크 제어용 예측 엔진

위의 사진(피크 제어용 예측 엔진) 속 프로세스의 최종 목표는 전력량이 일정 수준 이상이 되면 알림을 받는 것이다. 개인 자택이 아닌 기업이 지출하는 전력비용에는 '피크'라는 개념이 들어간다. 1년치의 단위 계약을 하는데, 1년 동안 피크를 친 전력량을 기준으로 산정이 되기 때문에 기업 입장에서는 이 '피크점'을 관리해야 한다.
→ 그래서 피크점이 넘어갈 것으로 예상되면 알림을 주는 프로세스
→ 영향을 받을 수 있는 요소 : 계절/날씨/요일, 사용 이력, 고장/운행
→ 이 요소들을 모두 통합해서 시계열 예측하는 함수와 regression을 통해 값들을 예측하고, 특정 피크점을 넘을 것인지 안 넘을 것인지는 Binary Classification으로 최종적으로 판단된다.
2. Recommendation - Factorization 기반
1) Collaborative Filtering & Content based Filtering
- Recommendation(추천) 분야는 오랜 전부터 발전해오기는 했지만, 'Netflix Prize'라는 대회를 통해서 추천 연구 분야가 널리 알려준다.
- 가장 간단한 것은 '나랑 비슷한 취향의 사람을 찾아주는 방법'인 'Collaborative Filtering(협업 필터링)'
- 가장 비슷한 컨텐츠를 찾아주는 방법인 'Content based Filtering'

# Collaborative Filtering (CF, 협업 필터링)
- 모든 데이터들을 비교하면서 나와 가장 비슷한 취향을 찾아주는 개념에서 'Collaborative(협업)'
- 단순하고 나온지 오래되었지만, 여전히 기업들에서 많이 사용되고 있는 알고리즘
→ 영화를 추천받는다면, 사람을 기준으로 할 것인지 컨텐츠를 기준으로 할 것인지에 따라 종류가 나뉜다.
- 문제(한계점)
: 내가 처음 들어온 사람이고 아무것도 구매/시청한 적이 없다면? → 추천받을 수 없다. 취향을 모름
→ 'Cold Start Problem' 발생
→ 이 한계점을 풀기 위해서 나온 것이 'Content based Filtering'
# Content based Filtering
- 행과 열을 바꿔서 콘텐츠의 유사도를 계산해낼 수 있다.
→ 취향이 비슷한 사람이 아니라 비슷한 선호를 가진 콘텐츠를 찾아낼 수 있다.
- ex) 내가 처음 들어와서 하나라도 구매/시청한다면, 그와 유사한 아이템/콘텐츠를 추천받을 수 있다.
2) 희소성(Sparsity) 문제
- 현실 데이터에는 희소성(Sparsity) 문제가 매우 크기 때문에 알고리즘 적용이 어렵다.
→ 이 희소성 문제를 해결하기 위해 다양한 방법들이 시도되고 있음
- Matrix Factorization과 Factorization Machine이 대표적으로 시도되고 있음
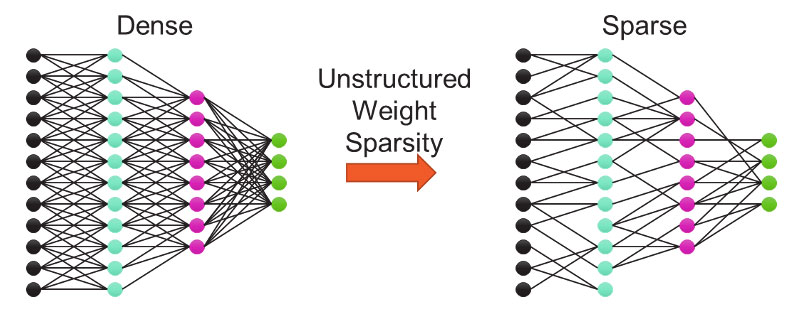
# 희소성 문제(Sparsity problem)
: 머신러닝, 데이터과학과 자연어 처리 분야에서 자주 마주치는 문제로 데이터가 매우 드물게 분포되어 있어서 분석이나 모델 학습에 어려움을 겪는 현상을 말한다. 희소성 문제는 고차원 데이터에서 더욱 심각해지는데, 데이터의 차원이 높아질수록 데이터 포인트 간의 거리가 증가하고, 데이터 분포가 더욱 희소해진다. 이로 인해 머신러닝 모델, 특히 거리 기반의 알고리즘들이 제대로 작동하지 않을 수 있다.
→ 희소성 문제를 해결하기 위해 대표적으로 차원 축소 기법(PCA), 데이터 정규화, 특성 선택 기법 등의 방식이 있다. 이러한 방법들은 중요한 정보를 유지하면서 차원을 줄임으로써 희소성을 감소시키는데 도움을 준다.
# Matrix Factorization (MF)
Matrix Factorization(MF)은 협업 필터링(Collaborative Filtering, CF) 중 model-based filtering에 속한 대표적인 알고리즘이다. 성능도 매우 준수한 편이라서 만은 추천 시스템에서 MF 알고리즘을 사용한다. 아래 간단한 예시로 감을 익혀보자.
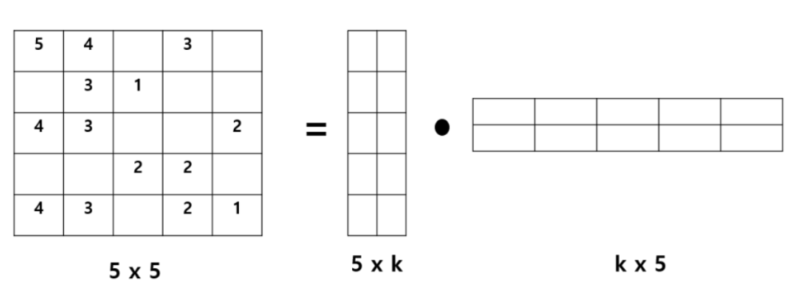
위 사진의 한 예로 행렬 A(5 x 5)를 U행렬(5 x k)와 V행렬(k x 5)로 분해가 가능하다. (이 때, k값은 예시로 2로 했지만 다른 값으로도 지정 가능하다) 이렇게 분리된 2개의 행렬은 각각 'User Latent Factor Matrix'와 'Item Latent Factor Matrix'로 각각 User(행)와 Item(열)에 내재된 잠재적 의미가 있다고 볼 수 있다.
분해된 행렬을 내적연산하게 되면, 다시 기존의 모양인 (5 x 5) 행렬로 돌아갈 수 있기 때문에 이와 같이 행렬을 분해해도 큰 무리는 없다.
그리고 분해된 행렬들이 파라미터로 취급되어 모델 학습을 통해 행렬 값들을 업데이트 해 나가고 분해된 두 행렬을 내적하여, 다시 원래의 행렬 모양으로 만들 때, 기존에 값이 없던 부분까지 모두 채워지게 된다.
→ 이를 통해, missing한 부분의 데이터를 채울 수 있게 되는 원리이다.
# Factorization Machine (FM)
Factorization Machine(FM) 방법은 기존의 Matrix Factorization(MF) 모델을 보완한 방식으로, MF 방식에서 나타내는 (user, item, rating) 행렬은 가로 축이 user, 세로 축이 item, 값이 rating인 반면에 FM 방법은 regression과 본질적으로 같은 방식이기 때문에 행렬 구성에서 가로 축은 index(각 튜플), 세로 축은 field(user, item ... rating)값은 각각의 feature 값을 갖게 된다.
# 등장 배경
- 딥러닝이 등장하기 이전까지 서포트 벡터 머신(SVM)이 가장 많이 사용되는 모델이였다.
(kernel 공간을 활용하여 비선형 데이터셋에 대해 높은 성능을 보임)
- CF(Collaborative Filtering) 환경에서는 SVM보다 MF(Matrix Factorization)계열의 모델이 더 높은 성능
- 하지만, MF모델은 유저 혹은 아이템(X)가 rating(Y)으로 이루어진 데이터에 대해서만 적용이 가능하기 때문에 한계가 있다.
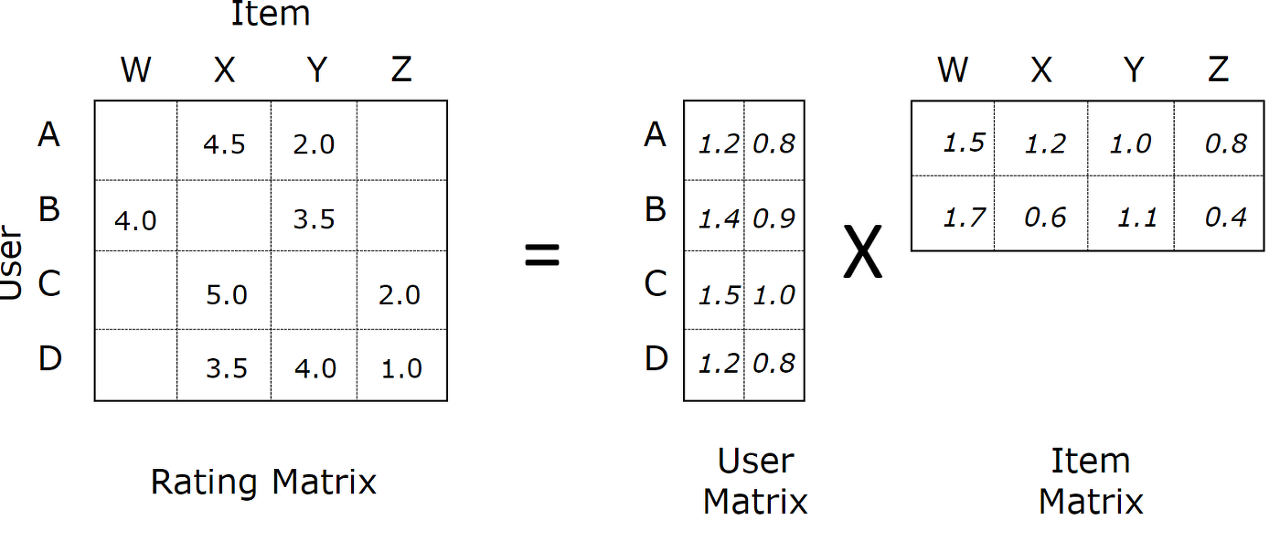
Factorization Machine의 경우, rating값을 target으로 하는 regression이기 때문에 field를 여러 가지 추가시킬 수 있는 장점이 있다. 영화를 예를 들면 영화 장르, 배우의 출현 여부 등을 one-hot encoding(categorical data의 경우)하여 넣을 수 있다. 이처럼 추가적인 feature를 입력할 수 있다는 점에서 매우 유리하다.
반응형
3. Anomaly Detection (이상 탐지)
Anomaly Detection은 임팩트가 가장 크고 가장 많은 분야에서 다루고 있는 영역에 해당된다.
- 공정 프로세스 관리, 금융 사기 거래 탐지에서 많이 사용되는 머신러닝 문제
- 현업에서 정의한 범위인 Normal을 벗어나는 데이터를 'Abnormal'라고 정의한다.
- 단순한 Outlier detection부터 Out-of-Distribution, One Class Classification 등 다양한 방법으로 접근이 가능하다.
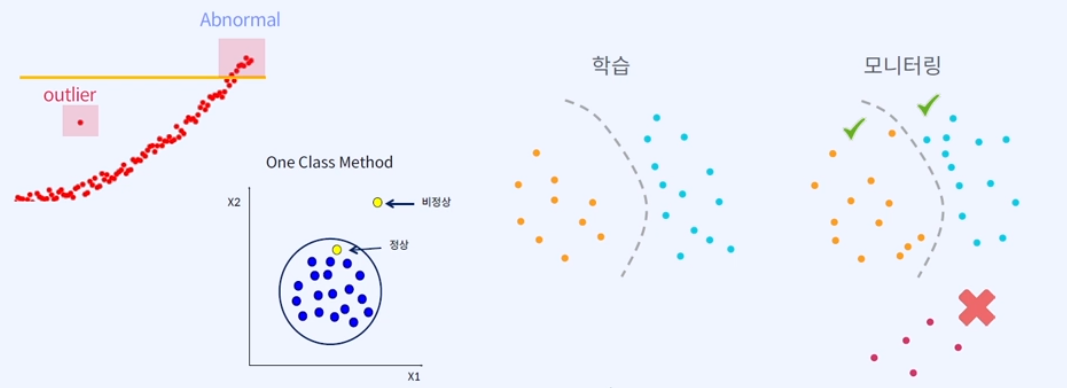
# One Class Classification (OCC)
: 비정상인 데이터가 없을 경우에 유용하게 사용됨. 이 경우 예를들어 정상 상태에 대해 학습을 해두고 정상 상태에서 얼마나 벗어나는지에 대한 distance를 계속 측정해서 이를 많이 벗어나는 때가 있다면, 비정상이라고 볼 수 있다.
→ 정상 범위에 대해서만 학습을 해두고 들어오는 데이터가 일정 범위 내를 벗어나는 경우를 detection하는 task
4. Image processing
- Image processing은 Deep learning 출현 이후에 지속적으로 발전하여 현재는 사람의 인지보다 높은 성능
- 연구는 독립적으로 이루어지지만, 현업에서는 sub task와 혼합하여 사용된다.
- Main Task
→ 1) Classification, 2) Localization, 3) Object Detection, 4) Instance Segmentation 등

Q) Image processing과 같은 기술들은 어디에 쓰일까?
- 제조업에서는 Image Processing을 적용하여 양품/불량품 자동 판정 모델에 이용
- 차량의 카메라 센서를 이용하여 운전자가 바라보는 방향의 이미지와 운전자가 볼 수 없는 영역의 이미지를 이용하여 Object detection으로 사물을 식별하고, Object classification을 통해 사람, 장애물, 차로 등을 식별
- OCR을 활용하여 아날로그 → 디지털 전환에 편리성 제공 (신분증 사진 식별 등)
5. NLP (Natural Language Processing, 자연어)
NLP(Natural Language Processing)는 컴퓨터가 인간의 언어를 처리하는 모든 기술을 의미
→ 어쩌면 세상을 곧 바꾸게 될 가장 혁신적인 기술 중 하나
→ 대표적인 Task는 번역, 감성 분석, 대화생성(챗봇), STT(Speech To Text) 등이 있다.
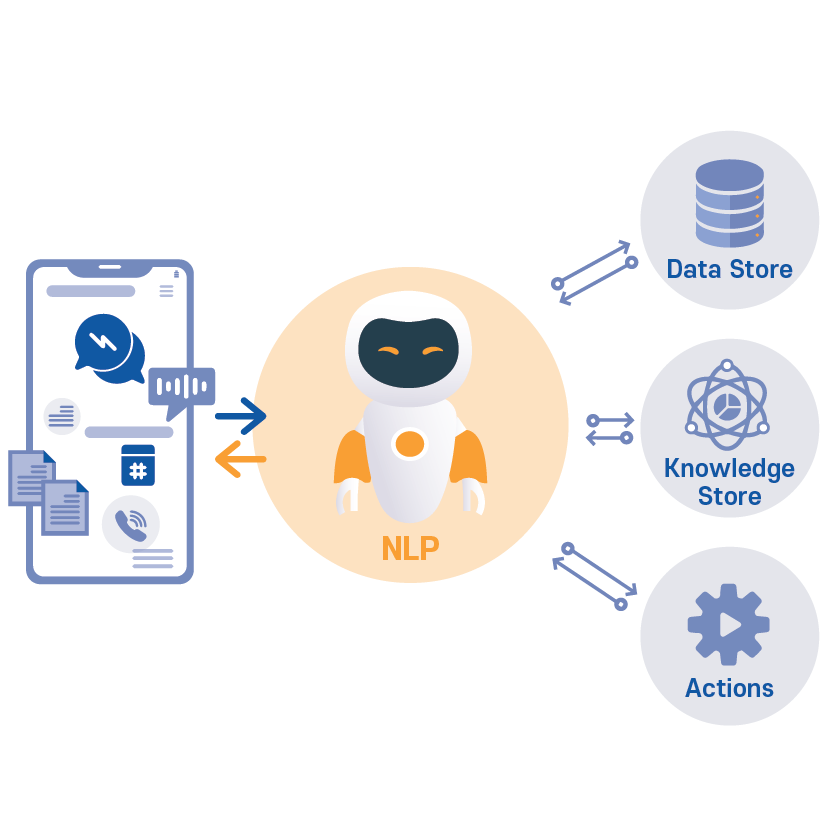
# NLP가 현재 현업에 쓰이는 곳은?
- 제품 리뷰의 Negative 비율을 관리하여 상품 평판 관리
- 다양한 미디어 매체의 데이터에서 부정적 의견을 모니터링하여 회사에 대한 평판관리
- CS 업무 중 반복적인 질문, 복잡도가 높지 않은 질문에 대한 자동 응대 (인건비 감소)
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE (패스트캠퍼스)
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) Supervised vs Unsupervised Learning 간단 정리 (0) | 2024.02.27 |
|---|---|
| (머신러닝) Data Cleaning과 Sampling 샘플링 기법 총정리! (1) | 2024.02.27 |
| (머신러닝) Feature Selection는 무엇이고 왜 꼭 알아야 하는 걸까? (1) | 2024.02.26 |
| (머신러닝) Feature Engineering의 종류와 기법 기초 정리! (1) | 2024.02.26 |
| 현업 데이터 분석의 오해와 진실 - 실패와 성공한 사례 분석 (0) | 2024.02.23 |




댓글