(머신러닝) Feature Selection는 무엇이고 왜 꼭 알아야 하는 걸까?
728x90
반응형
Feature Selection란 무엇이고 데이터 분석 프로세스에서 왜 필요한 걸까? 그리고 어떤 종류가 있는지 살펴보자.
Feature Selection이란?
머신러닝 데이터 분석에 꼭 과정이다?

1. Feature Selection?
Feature Selection이란, 패턴이 지니고 있는 다수의 특징 중에서 당면한 결정을 하는데 필요 충분하다고 생각되는 소수의 특징을 골라 내는 것을 의미한다.
데이터가 수집되었는데 엄청 많은 데이터들(ex, 2~3천개 등)이 있다면, 그냥 돌릴 수가 없다. 메모리 이슈도 있으며 성능도 당연히 제대로 안 나올 것이다.

# 운영적 관점
1) 적재하는 데이터의 양이 적어지므로 시스템을 운영하는 비용 감소
2) 적은 변수를 사용할 경우, 그렇지 않은 경우보다 시스템의 속도가 빨라짐
# 통계적 관점
1) 데이터에 대한 해석력을 높여줌
→ 데이터의 Feature가 너무 많으면 데이터에 대한 해석력이 떨어질 수밖에 없다. 너무 볼게 많으니깐. feature 간의 관련성을 고려할 것이 너무 많다.
2) 다중공선성의 문제에 대한 해결책으로 차원 축소를 이용할 수 있음
→ 독립변수(x)는 종속변수(y)와의 관계가 있으면 종족변수를 예측하기 수월해서 베스트이지만, 독립변수끼리 높은 관계성을 보인다면 정확한 학습이 어렵기 때문에 feature selection에서 drop을 시키면 차원 축소의 효과를 볼 수 있다.
3) Robust 모델로 예측력의 향상을 기대할 수 있음 - Bias, Overfitting 방지
→ 데이터가 많을 경우, feature가 수집되는 데이터의 특징에 따라서 결과가 너무 달라질 수 있다. (=robust 하지 않다) 반대로 feature가 적으면 결과가 일관성 있게 나올 수 있다.
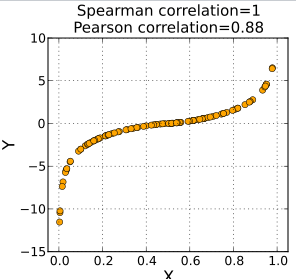
2. Pearson Correlation (상관관계)
Feature Selection을 하기 위한 여러가지 방법들 중에서 '상관 분석'이 대표적이다.
- 상관 분석(Correlation analysis)이란 두 변수가 얼마나 밀접하게 관련되어 있는지 알아보는 통계적 평가 방법이다.
→ 상관계수가 매우 높을 때, 해당 독립변수가 종속변수에 대해 유의미하다고 판단할 수 있다.
- 상관 계수를 구하는 대표 2가지
1) Pearson Correlation
: 공분산을 활용하여 이를 표준화한 상관계수
2) Spearman Correlation
: 값의 Scale은 무시하고, X와 Y의 순위 좌표로 전환하여 계산 (이상치에 대한 영향 감소)

반응형
3. Linear Model (선형모델)
- Linear Model을 활용한 Feature Selection은 전체 p-value가 일정 수준보다 작아질 때까지 p-value가 큰 변수를 제거하는 방법
→ p-value는 X값과 Y값이 우연히 발생할 확률을 의미한다. → 낮은 값을수록 우연일 확률 낮음
- 모든 X(Feature)에 대해 P-value를 계산하고 각 스텝마다 P-value가 가장 높은 X를 제거 (반복)

모든 X feature에 대한 Linear Model을 만들고 난 결과를 보면, 각 feature에 대한 p-value를 한 눈에 확인할 수 있다.
4. Feature importance
Feature Selection 중에서 가장 많이 사용되는 방법이 'Feature importance'이다. 그래서 최근까지 feature importance를 활용한 Feature Selection은 아주 일반적으로 사용되는 방법이다.
- Feature importance(중요도)은 예측에 가장 큰 영향을 주는 변수를 Permutation(순열)하며 찾아내는 기법
- Feature 간 상관관계가 존재하는 경우(=공선성 존재)에는 사용을 지양
→ 이 경우, 서로 공선성 관계를 가지는 feature들이 뽑혀 나오게 된다.
→ 따라서 다중공선성을 띄는 feature들을 제외시키고 importance를 뽑아내는 것이 중요
- Permutation Importance, SHAP 등의 기법이 주로 사용됨
→ Permutation importance는 각각의 Feature값의 importance를 계산한다. 하나의 값이 모델링의 결과가 나올때 얼마나 중요한 역할을 하는지를 확인할 수 있다.
# SHAP (SHapley Additive exPlanation)
: SHAPLEY Value는 모든 가능한 조합에 대해서 하나의 Feature의 기여도를 종합적으로 합한 값
→ Game theory 을 기반한다.
: 여러 주제가 서로 영향을 미치는 상황에서 어떤 의사결정이나 행동을 하는지에 대한 이론
→ X(독립변수)를 가지고 Y(종속변수)를 예측할때 쓰일 수 있는 모든 가능한 조합에 대해서 하나하나 feature들의 기여도를 계산해서 합해서 해당 feature의 값을 낸다.
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE (패스트캠퍼스)
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) Supervised vs Unsupervised Learning 간단 정리 (0) | 2024.02.27 |
|---|---|
| (머신러닝) Data Cleaning과 Sampling 샘플링 기법 총정리! (1) | 2024.02.27 |
| (머신러닝) Feature Engineering의 종류와 기법 기초 정리! (1) | 2024.02.26 |
| 머신러닝(ML)으로 현업에서 해결할 수 있는 문제 유형 총 정리! (1) | 2024.02.25 |
| 현업 데이터 분석의 오해와 진실 - 실패와 성공한 사례 분석 (0) | 2024.02.23 |




댓글