현업 데이터 분석의 오해와 진실 - 실패와 성공한 사례 분석
728x90
반응형
이번 게시물에서는 AI, Machine Learning(ML)의 역사, 중요한 전환포인트와 현재 수준을 확인해보고 데이터분석이 실제 현업에서 어떻게 사용되고 있는지 알아보자. 그리고 대부분의 기업들이 AI, ML 시스템을 도입하려고 하지만, 실패하는 이유는 무엇이고 성공하는 기업의 사례는 어떤 것이 있는지 살펴보자
데이터 분석은 현업에서 어떻게 사용되나?
많은 기업들이 AI/ML 도입에 실패/성공하는 이유와 사례는?

1. AI / ML 시대
1) 역사적 흐름
보통 사람들이 AI, Machine Learning을 최신 기술이라고 생각하고 있지만, 이미 머신러닝/딥러닝에 대한 수학적 수식들은 과거부터 수세기에 걸쳐서 만들어져있다. 하지만, 중요한 것은 '그 수식과 AI 기술이 최근들어 잘 사용되고 있는 것인가?'
최근 1세기동안 S/W와 하드웨어의 발전으로 인해서 현재 수준까지 왔다.
1900세기 말의 슈퍼컴퓨터는 최근 우리가 사용하고 있는 휴대폰의 기술/기능의 절반 수준밖에 되지 않는다.
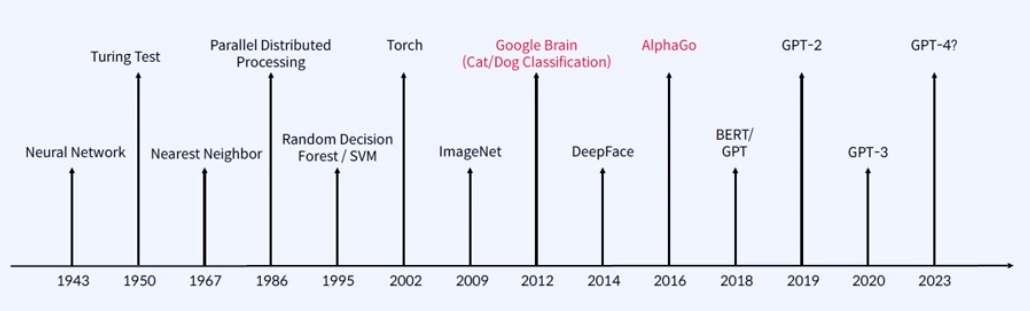
1986년도, 분산 처리(Parallel Distributed Processing) 이론이 나와서 현재 학습(Training)을 빠르게 시킬 수 있다.
1995년, 대표적인 분류 문제를 해결하는 Random Forest / SVM
2012년,Google Brain에서 나온 딥러닝을 이용한 유명한 개와 고양이를 분류하는 Cat/Dog Classification 알고리즘
2016년, AlphaGo를 통해서 일반인들도 AI를 알게 되는 계기
2018년, 이때부터 GPT가 등장하면서 지금까지 화두가 되고 있다.
2) Software 2.0
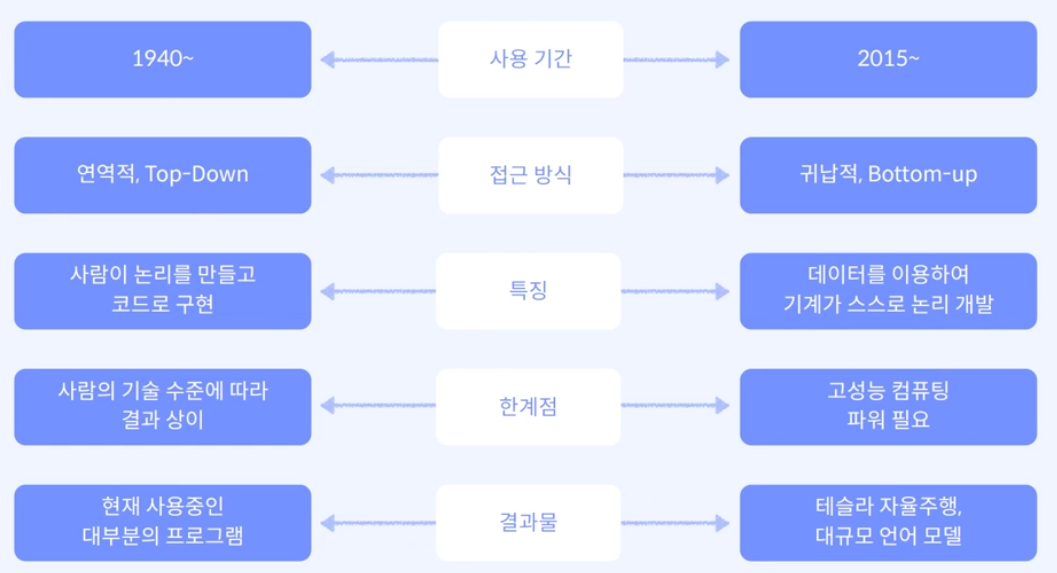
'Software 2.0'이라는 용어는 2017년부터 사용되었으나, 2015년부터 Software 2.0 시대에 돌입하고 Code Writeen by Humans(Software 1.0)에서 → Code Written by Data(Software 2.0) 패러다임 전환이 핵심이 된다.

즉, 코드가 사람이 쓰는 방식(1.0)에서 코드가 데이터에 의해서 만들어지는 방식(2.0)으로 전환되었다는 의미이다. Software 2.0은 Neural Net의 등장으로 딥러닝을 기반하고 있다.
3) 초거대 모델의 등장
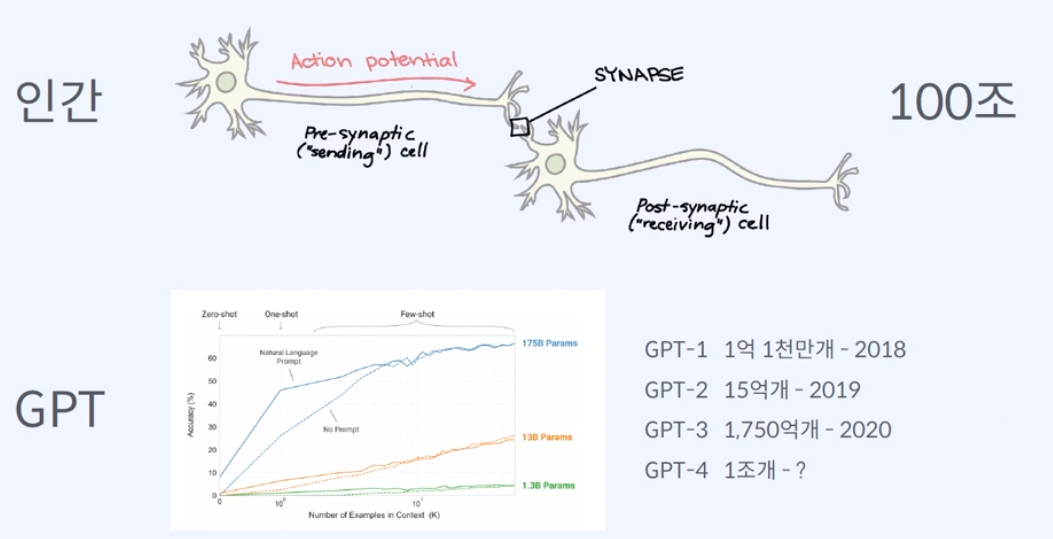
인간을 본떠서 인간이 어떻게 사고를 하는지를 보면, 신경을 전달해주는 신경세포체인 뉴런(Neuron)이 있고 뉴런과 뉴런을 이어주는 시냅스(Synapse)는 무려 100조개를 가지고 있다고 한다.
최초 GPT-1는 인간의 이 시냅스에 해당하는 파라미터(parameter)가 1억 1천만개를 가지고 있었으며, 곧 나올 GPT-4는 1조개를 돌파를 전망하고 있다.
4) 개발자에게 데이터 분석이란?
현업에서 데이터 분석의 활용은 어떻게 이루어질까?
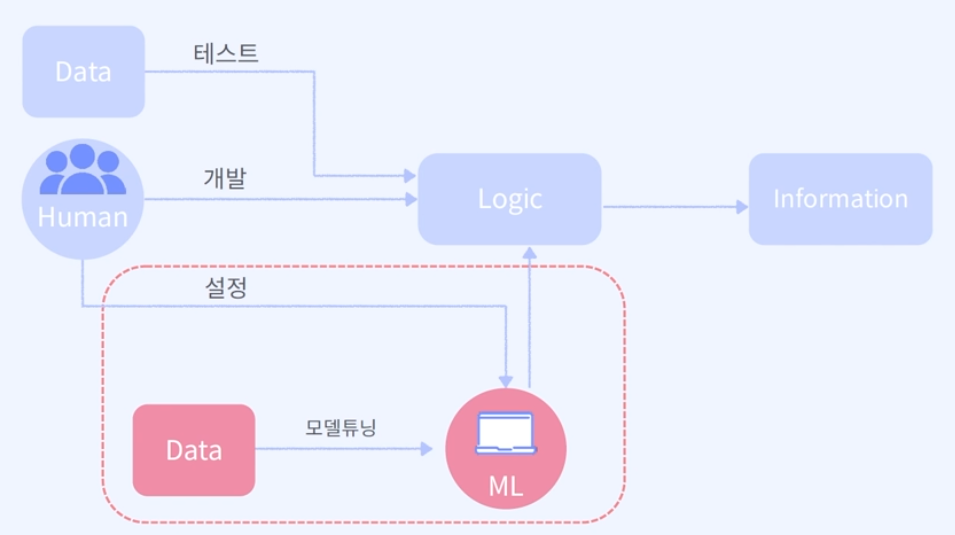
데이터 분석은 특정 데이터(Data)에 대해서 사람들은 궁극적으로 원하는 정보(information)을 도출해내는 것이 목표이다. 프래그래머(개발자)는 클라이언트에게 원하는 정보를 도출하도록 데이터와 요구사항을 전달받으면 데이터 분석에 들어가게 된다.
분석을 통해서 주어진 데이터를 원하는 정보를 도출할 수 있다 / 가능하다, 불가능하다 등의 결과물이 나오게 된다.
과거에는 사람들이 주어진 Data를 수동으로 돌렸다면, 최근에는 사람들이 이 로직(Logic)을 만들지 않고 모델튜닝(ML)을 통해서 기계가 학습할 수 있는 설정만(hyperparameter, resource, 분산처리를 위한 infra 설정 등)을 해준다. 이로써 다양한 방법으로 기계가 학습할 수 있는 환경만을 구축만 해준다.
→ 이 환경이 구축된다면, 개발자는 데이터만 부어주고 기계가 학습해서(=function을 만들어준다) Logic이 만들어지고, 결과(정보)가 도출된다. 심지어 결과값이 이상하면 다시 학습하고 또 학습하고를 반복하게 된다.
2. 실제 현업에서는?
1) 데이터 분석 프로세스 - 이상 vs 현실
실제 현업에서는 어떤 프로세스로 일을 하고 발생되는 문제에 대해 이상적인 데이터 분석 프로세스와 실제 현실과의 차이를 비교하면서 알아보자.
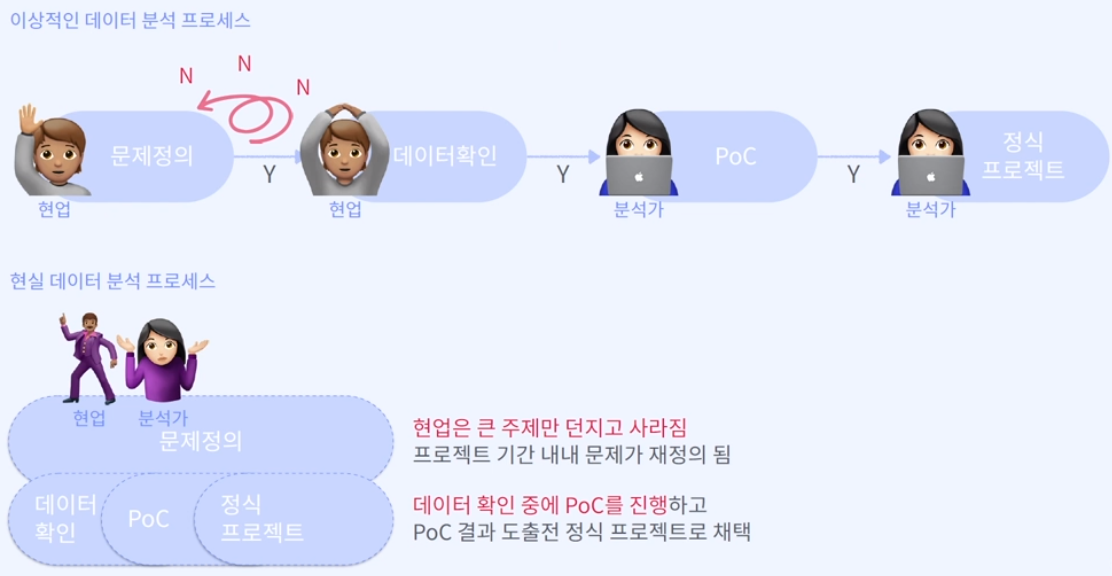
# 이상적인 데이터 분석 프로세스
1) 문제 정의
: 우리가 바라는 것과 현재의 차이. 현업에서는 '비용 절감, 프로세스 개선 등'이 주된 문제이다.
2) 데이터 확인
: 개발자는 클라이언트에게 데이터 여부 확인. 하지만 문제를 정의하고 데이터를 확인하는 데 상당히 오랜 시간이 걸린다.
3) PoC (Proof of Concept)
: 분석가는 데이터를 받아서 어떤 문제인지 머신러닝으로 풀 수 있는 문제인지 전환(분류, 회귀 문제인지 등)하고 분석 컨셉을 잡고 증명을 하는 과정을 거친다. 클라이언트와의 컨센서스를 맞추면서 효율성을 서로 맞춰야 한다.
4) 정식 프로젝트 진행
: 클라이언트의 승인이 떨어지면 정식 프로젝트가 진행된다.
→ 매우 이상적으로 현업 종사자는 현업의 일을 하고 분석가는 분석하는 일을 하는..
# 현실 데이터 분석 프로세스
- 현업 종사자는 문제가 무엇인지 정확히 인지하지 못하는 경우가 많다.
→ 막연하게 우리는 비용을 줄였으면 좋겠는데..? → 어떤 비용? 어느 정도로? 몇 %?
- 분석가(개발자) 입장에서는 목표가 명확하지 않으면, 그에 맞는 데이터를 준비하기 어렵게 된다.
→ 현업은 큰 주제만 던지고 프로젝트 기간 내내 문제가 재정의되는 경우가 허다하다.
→ 비용에 영향력이 큰 feature들이 뭐지..? 하다가 문제가 재정의된다. '아 그 비용은 자연적으로 감소돼요 등등'
→ 이러다가 프로젝트가 끝나는 시점에 나온 최종 결과물이 배포된다고 보면 된다.
2) 현실에서는 왜 비효율적으로 흘러갈까?
이상적인 프로세스가 있음에도 현실에서는 데이터 분석이 비효율적으로 끝나는 '이유'는 무엇일까?
이를 보기 위해서는 R&R(Roles and Responsibilities) 관점에서 볼 필요가 있다.

# 규제기관
: 어떤 사업을 하는 회사든 규제기관에서 각종 규제(신용보증, 산업안전 등)를 받게 되는데 여기서 사용해도 되는 데이터와 그렇지 않은 데이터가 공존
# 개발자, 운영자, 엔지니어
: 회사마다 운영되고 있는 환경(운영체제, 플랫폼 등)도 고려해야 하기 때문에 그 회사의 개발자, 운영자, 엔지니어의 협조를 받아야 된다.
# 현업관리자
: 도메인에는 전문가지만 ML은 잘 모른다.
# 일반사용자(End-User)
: 도메인도 잘 이해를 못하고, ML도 잘 모른다. ex) ML도 모르고 비용 절감에도 별 관심없음. 그냥 월급만 줘
# 데이터 분석가
: ML은 전문가지만 도메인은 잘 모른다.
→ 그래서 데이터분석가 입장에서는 예측값(Prediction)과 설명(Explanation)이 매우 중요하다. 따라서 분석가는 현업관리자와 매우 긴밀하게 작업을 해야 한다.
3) 프로젝트가 산으로 가는 사례들
대표적인 사례로 상관관계와 인과관계가 서로 맞지 않는 것이다. (상관관계 ≠ 인과관계)
그리고 데이터 분석에 대한 이해의 차이에서 오는 괴리감이 크기 때문에 프로젝트가 결국 산으로 가는 경우가 많다.
# 상관관계 (correlation)
: 관찰되는 독립변수(x)가 있고 독립변수들로 인해서 일어나는 일(y)이 있다면, x와 y 사이의 상관계수를 통해 관계로 표현하는 것

# example1) 해파리로 인한 인명 피해를 줄이고 싶다.
# 해파리 피해 원인에 대한 인자 후보 : 아이스크림 판매량, 기온, 몰리는 인파
해파리가 많이 등장하는 지역을 보니 타지역보다 아이스크림 판매량이 유독 높다.
→ 아이스크림이 많이 팔리니깐 해파리가 많이 나오더라. (상관관계 높지만, 인과관계가 없음)
하지만 아이스크림과 기온의 관계를 보면 기온이 높으면 판매량이 높다. (상관관계, 인과관계도 있지만 통제 불능)
→ 기온이 올라가서 해변에 해파리도 많고, 아이스크림도 많이 팔림
그렇다면 해변에 몰리는 인파는?
기온 상승 → 해변에 인파가 몰림 → 이 인파들을 통제하면 해파리로 인한 인명 피해를 줄일 수 있다.
따라서 일정 수준의 기온이 오르기 시작하면 인파 몰리는 것을 통제하자.
(상관관계도 크고, 인과관계도 있으며 통제도 가능하다)
# example2) 의사소통 도구의 부재
프로젝트 진행중)
- 분석가
: EDA를 해봤더니 데이터가 너무 Imbalance하고 Bias가 심해서 샘플링이 필요할 것 같다. 현재 오리지날 데이터만 갖고 Feature Importance를 뽑아봤는데 A Feature는 중요하고, B, C는 Outlier가 많아서 쓸 수 없을 것 같다.
- 현업종사자
: EDA? Imbalance? Bias? Outlier? 뭔 소린지는 모르겠지만.. 알아서 그냥 정확도 높게 해주세요
최종 결과물 배포 후)
- 현업종사자
: 확인해보니깐 잡혀야 할 불량이 전혀 잡히지 않는다. 정확도가 99.2%라고 했는데 터무니 없다.
- 분석가
: 현재 모델은 실험에서 가장 정확도가 높게 나온 99.2% 모델로 배포되어서 운영되고 있다. 데이터 자체가 너무 Imbalance하고, Bias가 심해서 할 수 있는 방법은 다 써봤는데 이게 최선이다.
→ 이해의 수준을 완벽하게 맞추지 않더라도 사용하는 단어, 기본적인 데이터 분석, 지식의 눈높이를 맞추면 일을 제대로 할 수 있다. (용어의 이해가 중요하다)
반응형
3. 기업에서 데이터 분석이 실패하는 이유는?
1) AI는 만능이 아니다
기업에서는 데이터 분석을 왜 실패할까?

" AI는 만능이 아니다 "
- 강력한 도구와 적절한 도구를 구별할 줄 알아야 한다.
→ 냉장고 1개를 옮기는데 15톤 트럭까지는 필요하지 않다.
- 분석가들은 문제에 맞는 기술을 선정할 수 있는 안목 필요
- 선택한 기술이 해당 문제에 적합하다는 것을 증명해야 한다.
- 왜 모든 문제에 Deep learning을 적용하지 못하는지에 대한 인식 필요
2) Data Scientist vs Data Engineer
Data Scientist와 Data Engineer의 R&R 이해 부족
- Scientist : 수학, 통계, 분석의 전문성
- Engineer : 프로그래밍, 분산처리, Data Pipeline에 능한 사람

Scientist는 Data Engineer에 비해 비지니스를 해결하는 것이 우선으로 business, data에 대한 이해, 통계적인 모델링과 시각화까지 많은 영역에 걸쳐서 높은 능력치가 필요하다.
하지만, 일을 하다보면 일에 집중하게 되고 R&R은 무너지기 마련..
그래서 Role 구분은 이론적으로만 가능하고 분석가는 어디까지 개발을 해야 되는지, 엔지니어는 개발된 모델을 실행할 수 있는 환경만 만들어주면 되는지에 대한 경계선이 모호하다.
에러가 발생하게 된다면...
- 모델 성능 하락, 모델 코드 내 에러
→ 분석가 : 자체 처리 불가. 모델 스크립트만 줬는데 수정해서 배포는 어떻게 하나요?
- 데이터 누락, 서버 이슈 등
→ 엔지니어 : 자체 처리 시도. 모델쪽에서 장애난 것 같은데 저도 처음 보는 에러..
+) 데이터 분석 프로세스에는 정말 다양한 컴포넌트들이 있기 때문에 R&R을 구분하면서 일하는건 비효율적일 때가 많다... Configuration, Data Collection, Feature Extraction, Data Verification, Machine Resource Management, Analysis Tools, Process Management Tools, Serving Infrastructure, Monitoring 등 이 중 ML Code는 극히 일부분
→ 그래서 분석가와 엔지니어의 마인드셋이 매우 중요하다
3) AI system Error
과거에는 코드 최적화나 새로운 알고리즘이 화두가 되어서 수많은 논문들이 나왔지만, 최근에는 그렇지 않다. 알고리즘만으로 성능이 좋아지는 것은 결국 한계가 온 것이다. 그래서 Data를 개선해서 에러율을 낮추는 방식으로 많이 가고 있다.
- 과거 : 모델(Code) 최적화 혹은 신규 알고리즘 개발 > Data 개선
- 최근 : 모델(Code) 최적화 혹은 신규 알고리즘 개발 < Data 개선

최근 데이터 중심의 접근으로 Random Forest, SVM 등의 알고리즘에 제대로 된 데이터만 넣으면 성능이 꽤 좋게 나오는 것을 노린다. 따라서 과거에는 에러를 분석해서 모델을 수정했지만, 요즘은 데이터를 튜닝하는 것이 더욱 중요해졌다.

코드 개선한다는 것은 알고리즘과 최적화하는 방법을 바꿔봐도 개선이 거의 없지만, 들어가는 컬럼을 줄이고 결측값 처리 등의 데이터를 개선한 이후에 개선율이 훨씬 좋아진 사례가 많다.
→ 대다수의 프로젝트에서는 '데이터 개선'에 집중하는 것이 훨씬 효과적이다.
# Data is Food for AI
- 실제 AI 프로젝트의 성공 여부는 데이터 정리에서 80%가 결정된다
- 나머지 20%는 Google의 BERT, OpenAI의 GPT-3과 같은 선진적인 모델이 좌우
- 하지만, 많은 사람들이 모델이 결과의 99%를 결정한다고 생각
- 따라서, 현업에서 프로젝트를 성공시키기 위해서는 데이터 준비가 철저히 필요하다
4) 그럼 어떻게 해야 하나?
1) 실패한 프로젝트의 자산화
- 자산화를 하지 않으면, 과거의 실패를 반복적으로 발생시킴
- 과거의 실패를 자산화하여 재사용 가능한 구조로 만들어야 시간이 지날수록 시행착오 시간이 짧아짐
2) Fast Fail 전략
- 빨리 실패해보고 안되는 것은 안된다는 것을 인지하고 다른 길을 찾아야 한다.
3) Small Win 문화
- 프로젝트를 작은 단위의 일로 만들고 성공 체험을 충분히 하면서 점진적 발전 형태가 필요하다
4. 기업에서 데이터 분석을 성공하는 사례는?
기업이 데이터 분석을 성공하기 위해서는 프로세스를 다시 한번 인지하는 것이 필요하다

1) 문제 인식 단계
: 어떤 문제를 풀어갈 것인가. 우리가 해결할 수 있는 것인가? 통제가 가능한가?
2) PoC & 구현
: 프로젝트 컨셉을 증명하고 구현하는 단계
3) 검증
: 구현된 프로젝트를 필드에 나가서 검증을 한다.
4) 배포
: 마지막으로 검증된 프로젝트를 배포
1) OO전자 사례 (Image Deep Learning 구현)
# 문제 인식 단계
- 요구 조건 : 타회사의 Model을 사용하고 있지만, Deep Learning Model의 전환이 주 목적
- 전체적인 정확도도 중요하지만, 미탐지(불량을 탐지하지 않는 것)를 낮추는 것이 가장 중요
- 입력 Image 180장 처리를 20ms 이내로 모델이 빠르게 돌아가야 한다. (공정시간 준수)
- 충분히 가능해보였다고 판단 → PoC 진행
# PoC & 구현
- Transfer Learning을 활용한 PoC
→ VGG가 성능은 가장 높았지만, 너무 많은 parameter로 인해 모델의 크기가 크고 추론 속도가 느림
→ Mobilenet V2 구조로 활용하여 추론 속도를 개선
→ 정확도가 99% 나왔지만, 미탐지 항목이 일부 존재. 튜닝을 통하여 정확도를 조금 낮춰도 미탐지를 개선
- Transfer Learning을 PoC하고, 현업데이터에 맞게 작업하는데 1개월 소요
# 검증
- 실제 현장(공정 라인)에 가서 프로그램 설치
→ 개발 환경 : 리눅스
→ 테스트 타겟 : Windows 10
→ 공정 PC : Windows Server 2008 (실행 불가..) → 다시 PoC 구현해서
- 공장과 거의 같은 환경해서 테스트 타겟 설정하고 에러는 디버깅하여 설치
- 프로그램 설치 및 실행 후 에러 발생
1) 모델 학습시 사용한 Test 데이터에 대한 정확도는 95.72%, 실제 공장은 50%
2) 처리시간 20ms 초과 현상 발생
3) 메모리 누수 현상 발생 등
- 미탐지에 대한 이슈 개선 (데이터를 세밀하게 보기 시작)
→ 육안으로 봐도 99.99% 일치하는 이미지지만, Label이 다름
→ Label이 일관성이 없으면 모델은 제대로 된 성능을 낼 수 없음
→ 데이터 재분류 및 재모델링 실시
# 배포
- 공장측은 주기적으로 cloud로 학습을 해줬으면 좋겠다는 피드백
- 공장은 Factory Automation(FA)망과 Office Automation(OA)망으로 분리되어 있고, FA망은 폐쇄망으로 인터넷이 되지 않는 환경.
- FA/OA망 사이 DMZ 구간을 활용하여 배포 파이프라인 구성
★ Tip
- 데이터분석의 결과는 어디에 어떻게 사용될지 아무도 모른다.
- 데이터가 주어지면, 분석해서 학습한 다음 배포해주면 엔드유저가 알아서 사용한다면 가장 이상적으로 데이터 분석가의 Role일 수 있지만 현실은 그렇지 않다.
→ 정말 많은 일들을 수행해야 한다.
→ 네트워크를 알고 있는 등 알고 있는게 많으면 많을수록 할 수 있는 일들 이 많아진다.
★ 데이터 엔지니어링의 중요성
- 모델링만 하는 분석가/모델러는 매력도가 떨어진다.
- 만든 모델이 돌 수 있는 환경(O/S 등)에 대한 이해와 적절한 IT 기술이 모델을 빛내준다.
→ 모델을 아무리 잘 만들어봤자 환경이 뒤받쳐주지 않으면 내 컴퓨터에서만 도는 binary file일 뿐이다.
- 모델링만 하는 분석가/모델러는 거의 없다.
- 모델의 성능이 나쁠 때는 알고리즘을 탓하지 말고 데이터를 살펴보자 (Data-Centric Model) ★★
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) Supervised vs Unsupervised Learning 간단 정리 (0) | 2024.02.27 |
|---|---|
| (머신러닝) Data Cleaning과 Sampling 샘플링 기법 총정리! (1) | 2024.02.27 |
| (머신러닝) Feature Selection는 무엇이고 왜 꼭 알아야 하는 걸까? (1) | 2024.02.26 |
| (머신러닝) Feature Engineering의 종류와 기법 기초 정리! (1) | 2024.02.26 |
| 머신러닝(ML)으로 현업에서 해결할 수 있는 문제 유형 총 정리! (1) | 2024.02.25 |




댓글