[Titanic] Feature Engineering(2) - One hot encoding, correlation
728x90
반응형
※ 타이타닉에 승선한 사람들의 데이터로 승객들의 생존여부를 예측하는 모델 구축 / 개발
※ Dataset Check, EDA 이후 Feature Engineering 과정을 통해 모델 학습도와 성능 향상
- 문자값을 수치로 변환(Initial, Embarked, Sex), One-hot encoding(Initial, Embarked), Feature간 상관관계(correlation) 확인
- Feature Engineering(1) - 결측값(null) 처리 과정에 이어서 학습
2. String 데이터 형태 → Interger 로 변환
- String 데이터를 모델 학습에 유용하게 학습시킬 수 있도록 수치로 변경하는 작업
- 일일이 하드코딩으로 바꾸는 것보다, mapping(=map() 함수)를 통해 간단하게 변경!
2.1. Initial (Mr, Mrs …) - map()
# 'Initial' 내 어떤 데이터값들이 있는지 확인
df_train.Initial.unique()
>>
array(['Mr', 'Mrs', 'Miss', 'Master', 'Other'], dtype=object)
# map() 함수를 통해 mapping으로 값 치환
df_train['Initial'].map({'Master':0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Other': 4})
>>
0 2
1 3
2 1
3 3
4 2
..
886 4
887 1
888 1
889 2
890 2
Name: Initial, Length: 891, dtype: int64
# 변경된 값 적용시키기 - Train, Test dataset
# Train dataset에 적용
df_train['Initial'] = df_train['Initial'].map({'Master':0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Other': 4})
# Test dataset에 적용
df_test['Initial'] = df_test['Initial'].map({'Master':0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Other': 4})
# 정상 반영되었는지 확인!
df_train.head()
>>

2.2. Embarked (C, Q, S)
Embarked 데이터의 현황을 파악하고, 각 value마다 특정 값(0~2) 부여
# 'Embarked' 칼럼에 데이터값의 현황 파악
- S : 646, C : 168, Q : 77 개의 데이터 분포 확인
- "df_train.Embarked.unique()" - unique() 메서드를 통해 value만 확인할 수도 있다.
df_train['Embarked'].value_counts()
>>
S 646
C 168
Q 77
Name: Embarked, dtype: int64
# Value(S, C, Q)에 특정 수치로 치환 - map()
→ "C : 0, Q : 1, S : 2" 로 각각 수치로 치환
# Train dataset 치환
df_train['Embarked'] = df_train['Embarked'].map({'C': 0, 'Q':1, 'S':2})
# Test dataset 치환
df_test['Embarked'] = df_test['Embarked'].map({'C': 0, 'Q':1, 'S':2})
# 정상 적용되었는지 결과 확인!
df_train.head()
>>

# 추가 확인 : Null data 여부 - any()
마지막으로 Embarked 데이터 내 Null data가 잔여하는지 마지막 확인
→ False : 없음. True : 있음
→ 마지막에 sum() 처리를 해서 '1' 이상의 수치가 나오면, null data가 있는 것으로 해석
df_train.Embarked.isnull().any()
>>
False2.3. Sex (male, female)
성별(Sex)의 String 데이터를 남/여에 따라 0과 1로 치환
# Sex(성별) 내 Value 확인
→ Sex 내 총 2가지의 Value 확인 (male, female)
df_train['Sex'].unique()
>>
array(['male', 'female'], dtype=object)
# Sex(성별) 데이터 치환
→ '여성(Female) : 0, 남성(Male) : 1' 로 치환
# Train dataset 반영
df_train['Sex'] = df_train['Sex'].map({'female':0, 'male': 1})
# Test dataset 반영
df_test['Sex'] = df_test['Sex'].map({'female':0, 'male': 1})
반응형
3. Seaborn heatmap - correlation 시각화
- Pearson Correlation을 통해 Feature 간 선형적인 상관관계 확인
- Coefficient가 1에 가까울수록 양의 상관관계, -1에 가까울수록 음의 상관관계를 가지며, 0일 경우 선형적인 관계가 없는 것으로 해석할 수 있다.
# 불필요한 Feature 제거
- PassengerId, Name, Ticket, Cabin, SibSp, Parch 는 drop 시키기
- SibSp + Parch = FamilySize, Cabin은 Null 데이터가 80% 이상, Ticket은 ID가 너무 다양해서 추론 어려움
df_train.drop(['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'], axis=1, inplace=True)
df_test.drop(['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp', 'Parch'], axis=1, inplace=True)
# Drop 잘 반영되었는지 확인_train dataset
잘 반영되어 총 8개의 Columns(=Features)만 남은 것을 확인할 수 있다.
df_train.head()
>>
# Drop 잘 반영되었는지 확인_test dataset
잘 반영되어 총 7개의 Columns(=Features)만 남은 것을 확인할 수 있다.
df_test.head()
>>

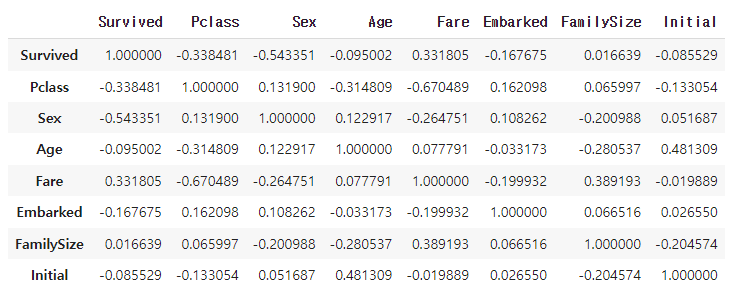
# 8개의 각 Feature 내 coefficient를 확인할 수 있는 Table 출력
- corr() : 각 Feature 내 correlation을 모두 구한다.
- Train dataset 기준 총 8개의 Feature에 대한 coefficient 확인
# heatmap_data 리스트에 저장
heatmap_data = df_train[['Survived', 'Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'FamilySize', 'Initial']]
# corr() 함수 사용
heatmap_data.corr()
>>
# Heatmap 시각화 - seaborn.heatmap()
- astype : 정의한 heatmap 데이터 내 모든 타입을 지정할 수 있다.
→ (float).corr() : pandas를 통해 correlation을 모두 구해준다.
- linewidths : 칸 사이의 간격
- vmax : 색깔의 변화
- annot : True일 경우, 칸 안에 수치 출력. False는 출력하지 않음
- annot_kws : 수치 사이즈 지정
- colormap : 다양한 스타일을 통해 Table 스타일을 바꿀 수 있다.
colormap = plt.cm.BuGn
plt.figure(figsize=(12,12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
# seaborn heatmap 출력 코드
sns.heatmap(heatmap_data.astype(float).corr(), linewidths=0.1, vmax=1.0,
square=True, cmap=colormap, linecolor='white', annot=True, annot_kws={'size':16})
>>
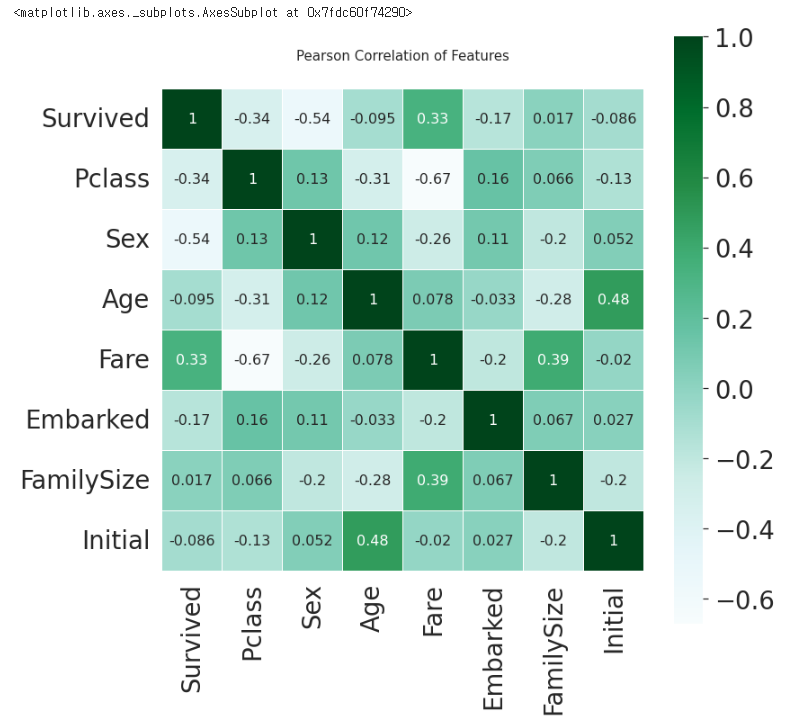
# Heatmap 해석 - 얻을 수 있는 정보
1) Sex와 Pclass는 'Survived'에 어느 정도 상관관계가 있다는 것을 알 수 있다.
- x축에 있는 'Survived' 기준으로 각 Feature별 coefficient 수치로 보면 Pclass(-0.34), Sex(-0.54), Fare(0.33)으로 어느 정도 유의미한 관계를 갖는다는 것을 알 수 있다.
- 반면, 그 외 수치들은 모두 값이 낮은 것으로 보아 관계성이 조금 떨어진다.
2) Initial과 Age는 서로 양의 상관관계를 가진다. (수치 = 0.48)
3) 자기 자신의 Feature 외, 1이나 -1의 값이 없는 것으로 보아 불필요한(redundant) Feature는 없다.
- 만약, 특정 2개의 Feature간 수치가 1이라면?
→ 2개의 Feature는 서로 선형관계성이 매우 높으므로 이 중 하나를 제거해도 무방하다는 의미가 된다.
4. One-hot Encoding
4.1. One-hot Encoding이란
원핫 인코딩(One-hot Encoding)은 사람은 쉽게 해석할 수 있는 데이터를 컴퓨터에게 아주 쉽게 주입시키기 위한 가장 기본적인 방법
- 사람과 기계는 데이터를 바라보는 형태가 매우 다르기 때문에, 사람이 쉽게 인식하는 숫자도 기계가 인공지능을 구현시키기 위해서(=모델 학습)는 컴퓨터가 잘 해석할 수 있는 숫자값으로 변환해주는 것이 좋다.
- 데이터들을 수많은 0값과 한 개의 1의 값으로 데이터를 구별하는 인코딩 방법
즉, 단어나 숫자 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 것의 인덱스에 '1'의 값을 부여.
그리고 다른 인덱스에는 '0'의 값을 부여하는 벡터 표현 방식이다.
4.2. Initial Feature
# Initial → One-hot encoding 작업
- Dataset을 설정하고, encoding할 column(=Feature)을 넣어주면 된다.
- 만약, initial 내 데이터값이 1이면, initial_1로 분류된다.
→ pd.get_dummies( )
→ 인코딩 결과, Initial_0 ~ 4까지 새롭게 생성되어 값이 부여된 것을 확인할 수 있다.
# Train, Test dataset에 모두 인코딩 적용
df_train = pd.get_dummies(df_train, columns=['Initial'], prefix='Initial')
df_test = pd.get_dummies(df_test, columns=['Initial'], prefix='Initial')
# 인코딩 후 결과 확인
df_train.head()
>>

4.3. Embarked Feature
# Embarked → One-hot encoding 작업
위에 Initial 에서 진행한 방법 그대로 진행
One-hot encoding을 하면 그 카테고리의 갯수만큼 column이 생성되기 때문에, 데이터에 카테고리가 너무 많다면 인코딩 후 데이터가 너무 커지기 때문에 학습하는데 지장이 생길 수가 있다.
→ 이 경우에는 One-hot encoding 말고 다른 비법을 사용하는 것이 좋다.
# Train, Test dataset에 one-hot encoding 적용
df_train = pd.get_dummies(df_train, columns=['Embarked'], prefix='Embarked')
df_test = pd.get_dummies(df_test, columns=['Embarked'], prefix='Embarked')
# 인코딩 후 반영된 데이터 확인
df_train.head()
>>

여기까지 Titanic dataset의 Feature Engineering 과정을 마치고, 다음 포스팅부터는 본격적인 모델 학습 및 Model Development(ML)을 하는 것을 학습할 예정
'Data Analyst > Kaggle & DACON' 카테고리의 다른 글
| [HDAT] HEV/PHEV 차량 에너지 흐름상태(HevMode) 예측하는 모델 실습 (0) | 2022.12.04 |
|---|---|
| [Titanic] Model Development(ML) - Randomforest (지도학습) (0) | 2022.12.04 |
| [Titanic] Feature Engineering(1) - 결측값(Null) 처리 (1) | 2022.10.30 |
| [Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(2) (0) | 2022.10.07 |
| [Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(1) (0) | 2022.10.06 |




댓글