[Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(2)
728x90
반응형
※ 타이타닉에 승선한 사람들의 데이터로 승객들의 생존여부를 예측하는 모델 구축 / 개발
※ Dataset Check(타이타닉 첫번째 chapter) 이후, EDA 과정을 통해 Feature 분석 단계
→ 타이타닉 데이터분석(1) 에 이어서
4. Violinplot (Age, Sex, Pclass)
- 3개의 dimension에서 Pclass, Sex, Age를 한 눈에 비교하며 분석할 수 있도록 시각화해보자
- Seaborn - violinplot 사용. 먼저 필사를 통해 결과물을 확인하고 익혀가는 방식으로 공부하자
f, ax = plt.subplots(1,2,figsize=(18,8))
# x축 : Pclass, y축 : Age, 색깔(Survived)
sns.violinplot('Pclass', 'Age', hue='Survived', data=df_train, scale='count', split=True, ax=ax[0])
# split = True 하면, 분리해서 하나의 바이올린 안에 다 출력된다.
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10)) # 0 ~ 110까지, 10 간격으로 (나이)
sns.violinplot('Sex', 'Age', hue='Survived', data=df_train, scale='count', split=True, ax=ax[1])
# scale = 'count' : 데이터의 양상을 count로 색별하여 출력
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()
>>
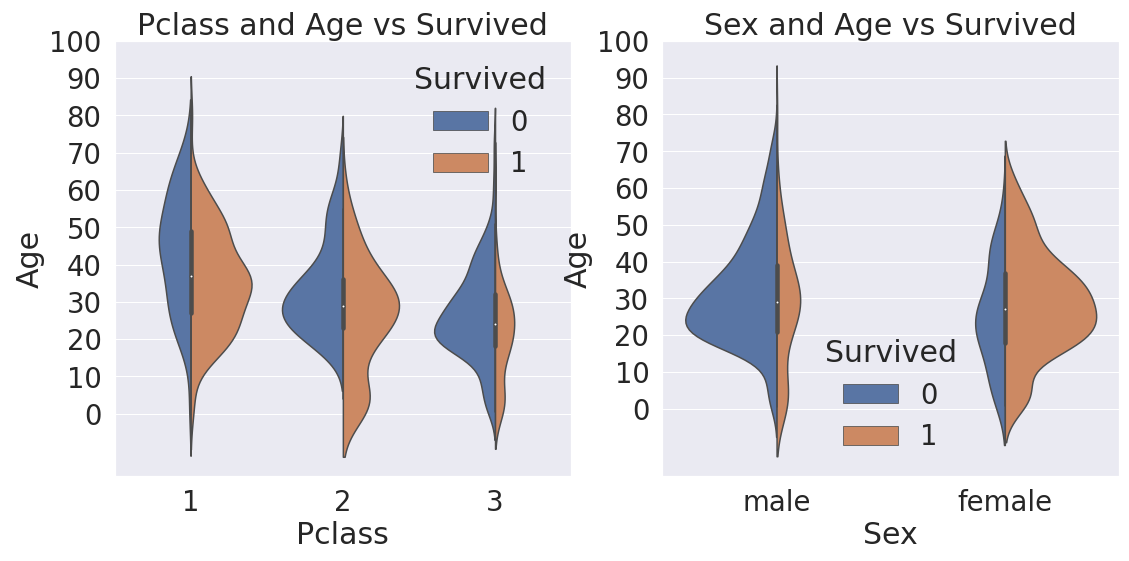
→ 위 그래프를 통해 각 Class별, Sex별 Age에 따른 생존(Survived) 양상을 시각적으로 확인할 수 있다.
( x축 : Pclass, y축 : Age )
5. EDA - Embarked (탑승 항구)
- Pandas Groupby를 통해 데이터 양상 확인
5.1. Embarked(탑승항구)에 따른 생존률 분포 확인
f, ax = plt.subplots(1,1,figsize=(7,7))
df_train[['Embarked', 'Survived']].groupby(['Embarked'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar(ax=ax)
>>
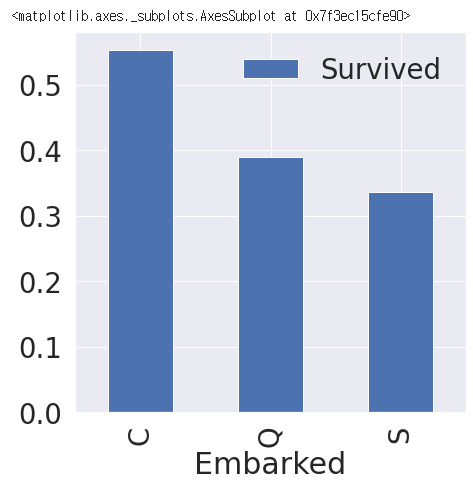
- df_train[['Embarked', 'Survived']].groupby(['Embarked'], as_index=True).mean()
: Embarked별로 생존(Survived)의 평균값
- sort_values(by='Survived', ascending=False)
: Survived를 기준으로 values를 구별 및 정렬. ascending=False : 내림차순 (True : 오름차순)
5.2. (2,2) size의 grid형식으로 데이터 해석
- (1,2)는 1차원, (2,2)는 2차원으로 4군데를 지정하여 그래프를 출력할 수 있다.
# 도화지 생성
f, ax = plt.subplots(2,2, figsize=(20,12))
# 1번재 plot
sns.countplot('Embarked', data=df_train, ax=ax[0,0])
ax[0,0].set_title('(1) No. of Passengers Boared')
# 2번째 plot
sns.countplot('Embarked', hue='Sex', data=df_train, ax=ax[0,1])
ax[0,1].set_title('(2) Male-Female split for embarked')
# 3번째 plot
sns.countplot('Embarked', hue='Survived', data=df_train, ax=ax[1,0])
ax[1,0].set_title('(3) Embarked vs Survived')
# 4번째 plot
sns.countplot('Embarked', hue='Pclass', data=df_train, ax=ax[1,1])
ax[1,1].set_title('(4) Embarked vs Pclass')
# 죄우/상하 간격 맞추는 과정 - 없으면 겹친다.
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()
>>
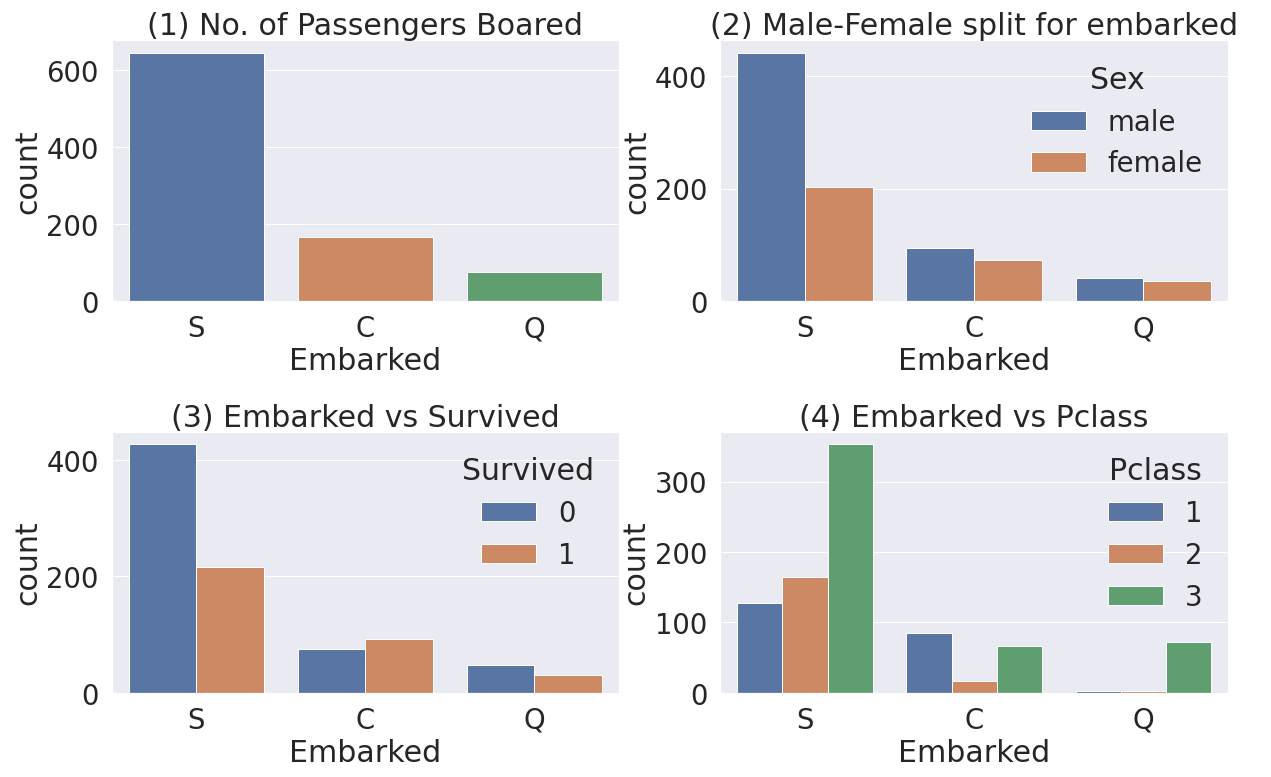
※ 위 4개의 차트 해석
1) 'S' 라는 탑승 항구(Embarked)에서 가장 많은 사람들이 탑승한 것을 확인할 수 있다.
2) 'S' 탑승항구에서는 male(남성)이 여성보다 2배이상 탑승
3) S보다 C와 Q에 탑승한 여성이 생존확률이 높다. (전체 탑승 인원 대비 생존 인원 기준)
4) C 탑승항구에는 1번 Pclass로 탑승한 비율이 높다.
6. EDA - Family (SibSp + Parch)
- SibSp : 형제자매, Parch : 부모와 자녀
- SibSp와 Parch를 'FamilySize'라는 Feature로 병합(새로운 column 추가) 후에 EDA를 실시
6.1. 새로운 컬럼 추가 (FamilySize)
- pandas.Series끼리는 더하고 빼는 등의 연산이 가능하다.
df_train['FamilySize'] = df_train['SibSp'] + df_train['Parch'] + 1
# + 1 : 본인도 포함해야되기 때문
# Test dataset에도 적용하기
df_test['FamilySize'] = df_test['SibSp'] + df_test['Parch'] + 1
# 추가한 column 확인
df_train['FamilySize']
>>
0 2
1 2
2 1
3 2
4 1
..
886 1
887 1
888 4
889 1
890 1
Name: FamilySize, Length: 891, dtype: int646.2. FamilySize의 최소/최대값과 평균값 출력
# 최댓값
print('Maximum size of Family:', df_train['FamilySize'].max())
# 최솟값
print('Minimum size of Family:', df_train['FamilySize'].min())
# 평균값
print('Average size of Family', df_train['FamilySize'].mean())
>>
Maximum size of Family: 11
Minimum size of Family: 1
Maximum size of Family 1.9046015712682386.3. FamilySize에 따른 데이터 시각화 (탑승자 수, 생존여부, 생존률)
- countplot을 통해 데이터 갯수(=명수)를 확인하고, groupyby를 통해 데이터 그룹 분류
→ 탑승객 명수, 생존여부, 생존률
# 도화지 선언
f, ax = plt.subplots(1, 3, figsize=(40, 10))
# 첫번째 그래프
sns.countplot('FamilySize', data=df_train, ax=ax[0])
ax[0].set_title('(1) No. Of Passenger Boarded', y=1.02)
# 두번째 그래프
sns.countplot('FamilySize', hue='Survived', data=df_train, ax=ax[1])
ax[1].set_title('(2) Survivved countplot depending on FamilySize', y=1.02)
# 세번째 그래프
df_train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar(ax=ax[2])
ax[2].set_title('(3) Survived rate dependiong on FamilySize', y=1.02)
# 그래프간 간격 설정
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()
>>
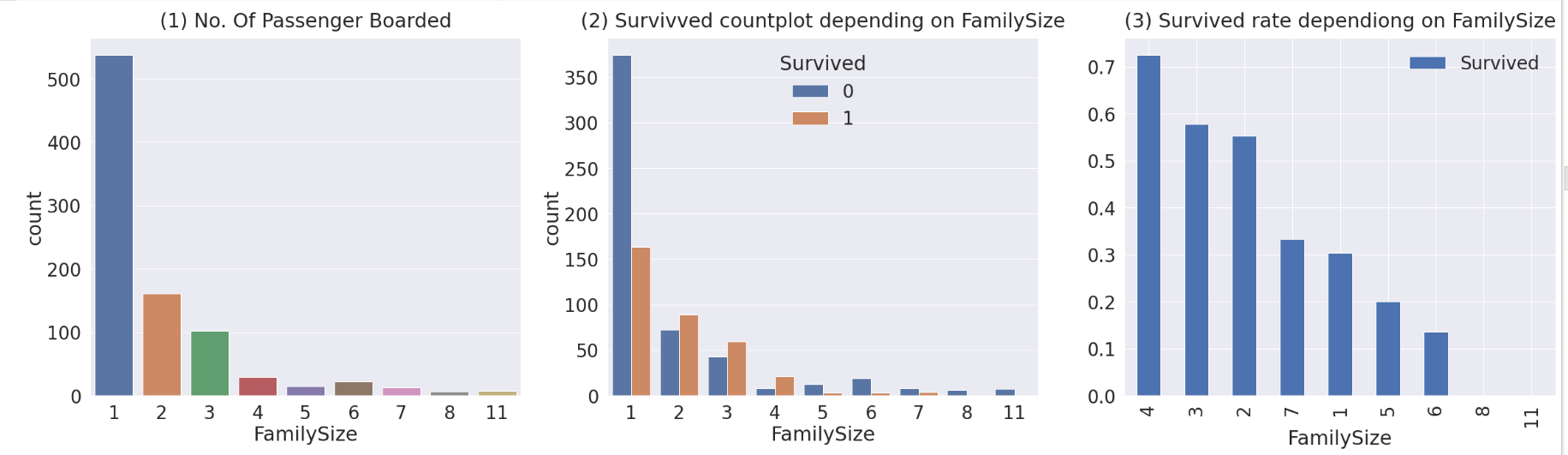
- 1번째 그래프 (Seaborn countplot)
: FamilySize에 따른 탑승자 현황(=명수) 파악 → 혼자(1명) 탑승한 인원이 가장 많고, 가족단위로도 탑승함
- 2번째 그래프 (Seaborn countplot)
: FamilySize에 따른 생존(Survived) 여부 파악 → 탑승인원 대비, 2~4명으로 탑승한 그룹이 생존을 많이 함
- 3번째 그래프 (Groupby를 통해 FamilySize 분류 후 / 평균 / 내림차순)
: 4번 탄 경우 생존률이 70% 초과, 3명은 대략 58~9%, 8~10명이 탄 가족은 모두 생존하지 못함
- 결론
: 4인 가족이 생존확률이 가장 높고, 2~4명의 가족이 생존확률은 50% 이상이며, 그 외는 생존확률이 낮다.
7. EDA - Fare, Cabin, Ticket
- Fare(탑승요금) : Continuous한 Feature.
→ Seaborn distplot 사용 / 왜도(Skewness) 확인 및 최소화
- Cabin (캐빈) : 80% 데이터가 Null data로 대부분의 데이터가 결측상태라 생존에 미치는 정보를 얻기 어렵다
→ EDA 및 데이터 분석에서 제외
- Ticket(티켓) : 다양한 이름(ID)의 티켓이 존재한다.
→ 많은 다양한 ID 중에서 어떻게 필요한 정보를 끄집어내는지가 중요. 이번 단계에서는 Skip.
7.1. 히스토그램(displot)을 통한 'Fare' 밀도 확인 - Skewness
- Skewness(왜도) : 데이터의 치우침. 히스토그램이 얼마나 쏠렸는지, 비대칭인지 확인
- 왜도란, 자료의 분포 모양이 평균을 기준으로 중심으로부터 한쪽으로 치우쳐 있는 경향을 나타내는 척도
→ a = 0 : 정규분포 / a > 0 : 우측으로 치우침 / a < 0 : 좌측으로 치우침
fig, ax = plt.subplots(1,1,figsize = (8,8))
# Seaborn Displot 사용 - Series를 받으면, 히스토그램을 그려주는 역할
g = sns.distplot(df_train['Fare'], color='b', label='Skewness: {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g = g.legend(loc='best')
>>
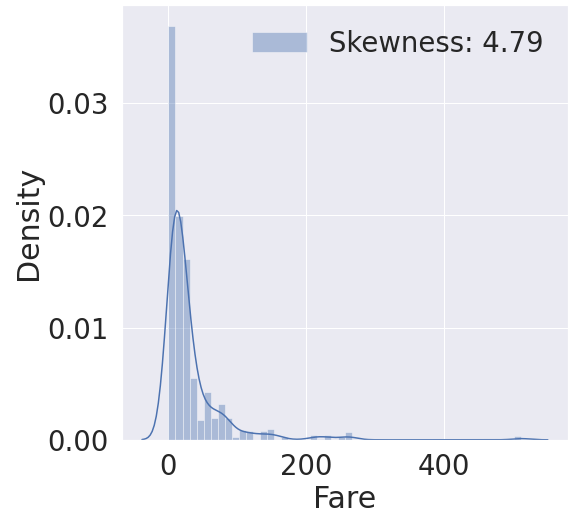
→ 위 그래프처럼, 데이터가 한 쪽으로 많이 치우치면 모델이 잘 학습되지 않고 성능이 낮아질 수가 있다.
→ 따라서 이런 경우에는 여러가지 operation을 통해 Skewness를 없애는 작업이 필요하다.
7.2. 로그를 취함으로써 Skewness(왜도) 최소화하기
# lambda 함수를 이용하여 로그 취하기
df_train['Fare'] = df_train['Fare'].map(lambda i: np.log(i) if i>0 else 0)
# 그래프로 Skewness 확인 - distplot
fig, ax = plt.subplots(1,1,figsize = (8,8))
g = sns.distplot(df_train['Fare'], color='b', label='Skewness: {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g = g.legend(loc='best')
>>
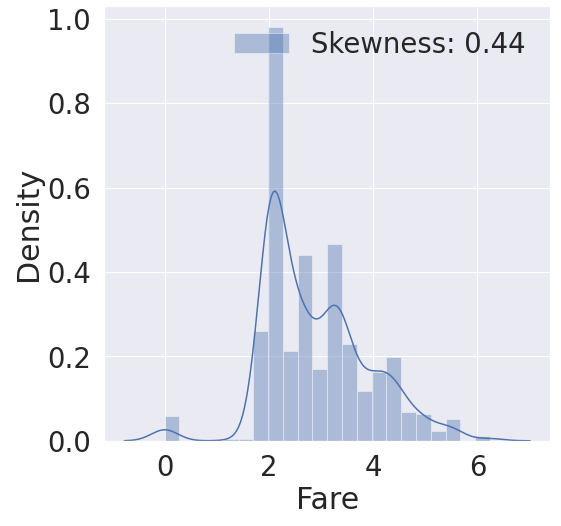
- df_train['Fare'] = df_train['Fare'].map(lambda i : np.log(i) if i > 0 else 0)
→ lambda 함수로 간단하게 한 줄로 조건문을 추가할 수 있다.
→ i가 0보다 크면 log(i)를 취하고, 0보다 작으면 0을 취한다.
→ map : 특정 Series(ex, 'Fare') 내 Values들에 동일한 operation을 적용하고 싶을 경우, map 사용
ex) lambda 함수 예시
→ x = lambda i : i * i ( i의 제곱 )
- 해석
→ 차트에서 볼 수 있듯이 Skewness(왜도)의 수치가 4.79에서 0.44로 낮춘 것을 확인할 수 있다(정규화 과정)
→ 이 작업은 일종의 Feature Engineering(=FE)라고 볼 수 있으며, 이는 모델의 학습도를 높이기 위해 작업이 필요하다.
// 여기까지 Basic한 Titanic EDA 과정을 모두 마치며, 다음 글부터는 본격적으로 Feature Engineering을 해보자.
'Data Analyst > Kaggle & DACON' 카테고리의 다른 글
| [Titanic] Model Development(ML) - Randomforest (지도학습) (0) | 2022.12.04 |
|---|---|
| [Titanic] Feature Engineering(2) - One hot encoding, correlation (0) | 2022.11.29 |
| [Titanic] Feature Engineering(1) - 결측값(Null) 처리 (1) | 2022.10.30 |
| [Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(1) (0) | 2022.10.06 |
| [Titanic] Dataset Check (Train & Test dataset, Null data) - 생존자 예측 (0) | 2022.09.24 |




댓글