[Titanic] Dataset Check (Train & Test dataset, Null data) - 생존자 예측
728x90
반응형
※ 타이타닉에 승선한 사람들의 데이터로 승객들의 생존여부를 예측하는 모델 구축 / 개발
※ 단계별 Flow 정리
1) Dataset check : Train, test dataset 확인 및 Null data 분포 분석 (모델 성능을 위해)
2) EDA(Exploratory Data Analysis) : 각각의 Column들을 분석하고, Feature간 어떤 관계성을 가지는지 분석
3) Feature Engineering : 모델 생선 전, 성능을 높이기 위해 엔지니어링 작업 수행
4) Model 생성 : Sklearn 라이브러리 활용 / 딥러닝 : Tensorflow or pytorch 등 사용
5) Model Training 및 Prediction : Train data를 훈련 후에 Test dataset를 통해 평가(성능도) 진행
- Gdrive 연동 후, Train과 Test dataset의 형태 파악 (Google Colab 환경에서 진행)
- missingno를 이용하여 Null data에 대한 시각화 Matrix, Bar 형태로 출력
1. Dataset 확인 (Train, Test dataset)
- Gdrive 연동 후, Train과 Test dataset의 형태 파악 (Google Colab 환경에서 진행)
1.1. 구글드라이브(Gdrive) 연동
from google.colab import drive
drive.mount('/content/drive')1.2. 필요한 라이브러리 Import
import numpy as np
# 수치해석적인 부분 / 벡터연산
import pandas as pd
# DataFrame, SQL 등의 데이터프레임을 쉽게 다룰 수 있도록
import matplotlib.pyplot as plt
# 데이터 시각화 라이브러리
import seaborn as sns
# matplotlib, seaborn의 스타일이 다양하다. -> 구글 검색 참고
plt.style.use('seaborn')
# matplotlib의 스타일은 'seaborn'으로 사용한다는 의미
sns.set(font_scale=2.5)
# seaborn 내 폰트사이즈 - 취향대로
import missingno as msno
# Null 데이터(채워지지 않은 데이터)를 쉽게 보여줄 수 있는 라이브러리
import warnings
warnings.filterwarnings('ignore')
# ignore warnings - 워닝 무시
%matplotlib inline
# matplotlib를 사용해서 그림을 그리고 show를 하면
# 새로운 창이 뜨는데, inline을 설정하면 작업중인 Notebook에서 볼 수 있도록1.3. Train, Test data 불러오기
- 해당 실습에서는 Gdrive에 파일이 업로드 되어있어서, 해당 디렉토리에서 csv 파일을 불러옴
- 테이블구조의 데이터를 쉽게 다룰 수 있는 라이브러리는 Pandas, 여러 종류들의 파일들을 읽어올 수 있음
df_train = pd.read_csv(r'/content/drive/MyDrive/Colab Notebooks/Titanic_file/train.csv', engine='python')
df_test = pd.read_csv(r'/content/drive/MyDrive/Colab Notebooks/Titanic_file/test.csv', engine='python')1.4. Train 데이터의 상단 확인 - head()
- default는 5개를 출력하며, 괄호( ) 안에 입력한 수치만큼 출력한다.
df_train.head()
>>

→ Passenger ID, Survived, Pclass, Name, Sex 등의 Feature 들을 확인할 수 있다.
→ 카테고리타입의 데이터들은 추후 One-hot 인코딩을 통해서 데이터처리에 용이하다 (Pclass, Embarked)
1.5. Feature별 간단한 통계적 수치 출력 - describe()
- count, mean, std, 최댓값, 최솟값 등 확인
df_train.describe()
>>
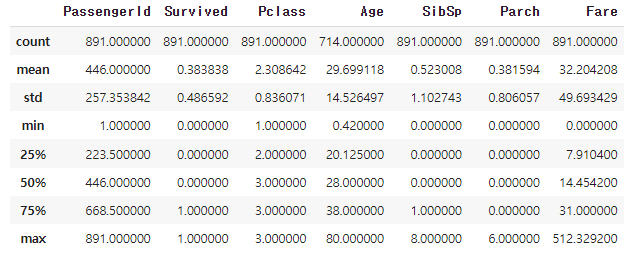
→ 각 Feature별 count 결과를 통해 maximum값인 891명이 train data에 속해있다.
→ 891(max값) 대비 Age의 count값은 '714'명으로 보아, 77개의 Null data가 있음을 알 수 있다.
1.6. Train & Test dataset의 형태 확인 - .shape
df_train.shape, df_test.shape
>>
((891, 12), (418, 11))
→ Train : 891명의 데이터가 있고, Feature(=Column)이 12개가 있다.
→ Test : 418명의 데이터가 있고, Feature는 11개 ('Survived' feature만 빠진 상태)
2. Null data(결측값)의 분포 확인
- Null data의 분포 확인
- missingno를 이용하여 Null data에 대한 시각화 Matrix, Bar 형태로 출력
2.1. 각 Column의 Null 데이터 분포를 백분율(%) 출력
for col in df_train.columns:
msg = 'column: {:>10}\t Percent of Nan value: {:.2f}%'.format(col, 100 * (df_train[col].isnull().sum() / df_train[col].shape[0]))
print(msg)
# 오른쪽 정렬 = {:>10}
# 왼쪽 정렬 = {:<10}
# 보통 정렬 = {:10}
# 위의 10은 임의의 숫자. 출력하고자 하는 문자열의 수에 따라 다르게 설정하면 된다.
>>
column: PassengerId Percent of Nan value: 0.00%
column: Survived Percent of Nan value: 0.00%
column: Pclass Percent of Nan value: 0.00%
column: Name Percent of Nan value: 0.00%
column: Sex Percent of Nan value: 0.00%
column: Age Percent of Nan value: 19.87%
column: SibSp Percent of Nan value: 0.00%
column: Parch Percent of Nan value: 0.00%
column: Ticket Percent of Nan value: 0.00%
column: Fare Percent of Nan value: 0.00%
column: Cabin Percent of Nan value: 77.10%
column: Embarked Percent of Nan value: 0.22%2-2. Null data 분포 확인하는 코드 설명
- Pandas의 기본 객체는 Series를 이룬다. (각각 Index와 Value들로 이루어짐)
- Series가 많이 쌓이게 되면 하나의 DataFrame을 이루게 된다.
1) 타입(type) 확인
type(df_train[col])
>>
pandas.core.series.Series→ df_train[col] : Pandas의 Series 타입 확인
2) Null 의 갯수 확인
# 특정 column에 Null이 있는지 확인하는 메서드 - .isnull()
df_train[col].isnull()
>>
0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Embarked, Length: 891, dtype: bool→ Null 값이 있으면 True(0), 없으면 False(1) 출력
# 모든 column의 Null 갯수 출력
df_train[col].isnull().sum()
>>
2→ sum()을 해서 2가 출력되었다는 말은 'True(=1)'개 있다는 것이며, Null 값이 2개 존재한다는 의미이다.
3) Null 값이 있는 항목에 대한 비율 출력
# col Series의 차원 확인 (총 raw 갯수 확인)
df_train[col].shape
>>
(891,)
# 백분율로 표현하기 위한 코드
df_train[col].isnull().sum() / df_train[col].shape[0]
>>
0.002244668911335578→ shape[0] : (891,0) 차원에서 891 수치만을 뽑아오기 위해 index 0으로 지정
4) 동일한 원리로 Test Dataset 에서의 Null 값 비율 출력
for col in df_test.columns:
msg = 'column: {:>10}\t Percent of Nan value: {:.2f}%'.format(col, 100 * (df_test[col].isnull().sum() / df_test[col].shape[0]))
print(msg)
>>
column: PassengerId Percent of Nan value: 0.00%
column: Pclass Percent of Nan value: 0.00%
column: Name Percent of Nan value: 0.00%
column: Sex Percent of Nan value: 0.00%
column: Age Percent of Nan value: 20.57%
column: SibSp Percent of Nan value: 0.00%
column: Parch Percent of Nan value: 0.00%
column: Ticket Percent of Nan value: 0.00%
column: Fare Percent of Nan value: 0.24%
column: Cabin Percent of Nan value: 78.23%
column: Embarked Percent of Nan value: 0.00%→ Test dataset에서는 Age, Cabin에 Null값이 각각 20.57%, 78.23% 있음을 확인
2-3. Null data 분포 시각화 - missingno
- msno(missingno) 라이브러리를 활용하여 Null data를 비교적 쉽게 분포를 확인해보자!
- 이 라이브러리는 Null값을 출력하는 일종의 Matrix를 생성하고, Matrix 내 빈 칸이 Null 값으로 시각화된다.
# 1. Matrix 형태로 출력
msno.matrix(df=df_train.iloc[:,:], figsize=(8,8), color=(0.8, 0.5, 0.2))
# 2. Bar 형태로 출력
msno.bar(df=df_train.iloc[:,:], figsize=(8,8), color=(0.8, 0.5, 0.2))
>>
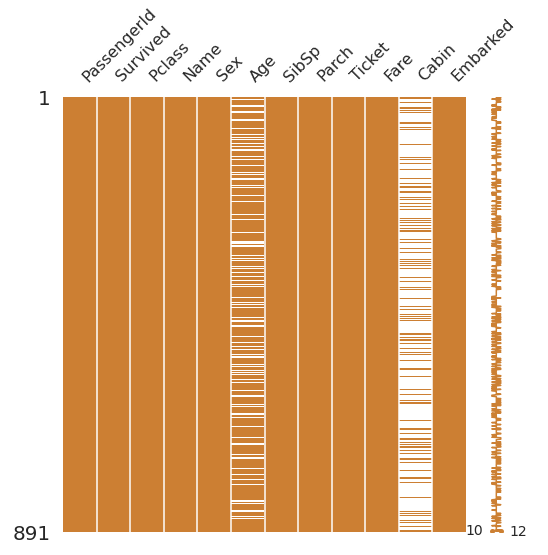
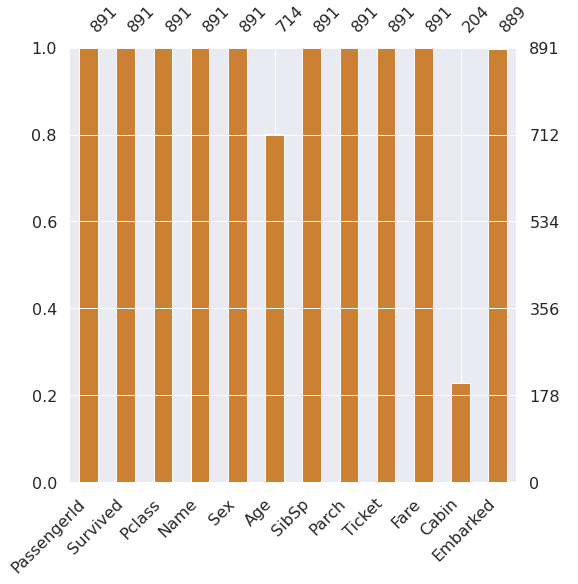
- input : df_train.iloc[:, :] : DataFrame 내 모든 데이터
- iloc (index location) : Pandas 문법으로 Indexing하는 역할
→ 원하는 row나 column 등의 원하는 위치에 있는 DataFrame을 가져올 수 있는 메서드
- figsize : 출력되는 matrix 사이즈
- color : RGB 기반의 0~1 사이의 값으로 설정할 수 있다.
2-4. iloc 실습으로 간단 설명
# iloc[] 안에 첫번째 인자는 columns(가로)를 의미하고, 2번째는 row(세로) 의미
# DataFrame에서 모든 Columns에 대한 첫번째(index=0) row data 출력
df_train.iloc[:,0]
# DataFrame 내 모든 Feature(raw data)에 대해 첫번째 column data 출력
df_train.iloc[0,:]
# Row 기준 4~5번째의 모든 Column 데이터를 추출
# [3:5] : 4, 5 포함 / 3 제외
df_train.iloc[3:5,:]
# DataFrame 내 모든 데이터를 다 포함
df_train.iloc[:,:]

3. Target Label(Survived) 분포 확인
- Dataset의 Target Label인 'Survived' Feature가 얼마나 Balance하게 분포되었는지 분석
- 우리가 목적으로 잡는 Target Label이 어떠한 Distribution을 가지는지 확인할 필요가 있다.
→ 한쪽이 너무 치우치면 모델 성능이 꽤 좋지 않을 수 있으므로, 시각화를 통해 확인해보자
- 나중에 'Plotly' 라는 시각화 라이브러리도 공부해보자. → 데이터들을 Interactive하게 시각화할 수 있다.
# pie, count plot을 통해 Distribution 확인해보기
f, ax = plt.subplots(1,2,figsize=(18,8))
df_train['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Pie plot - Survived')
ax[0].set_ylabel('')
sns.countplot('Survived', data=df_train, ax=ax[1])
ax[1].set_title('Count plot - Survived')
plt.show()
>>
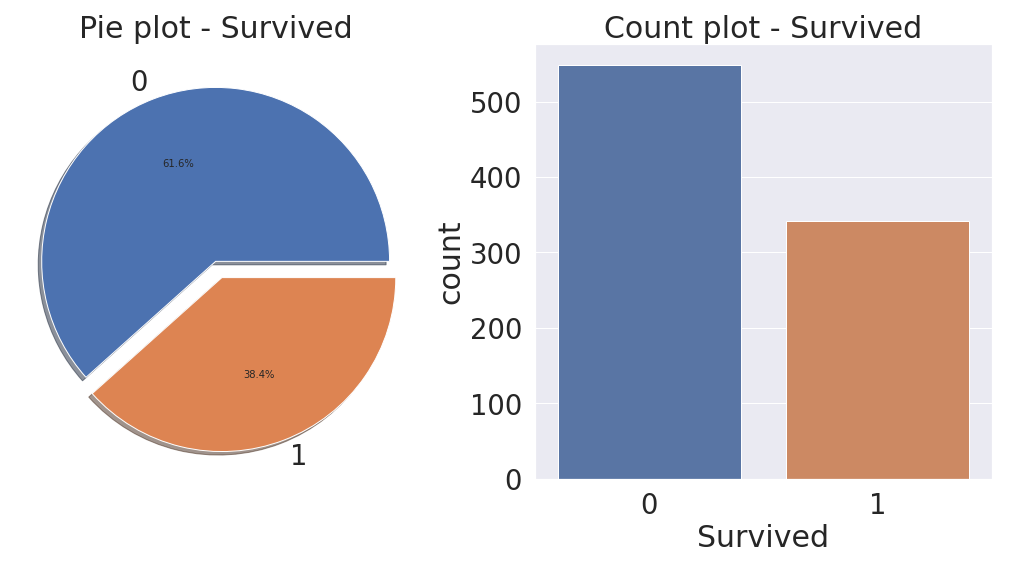
# 코드 부연 설명
- f, ax = plt.subplots(1, 2, figsize=(18,8))
: pyplot을 통해 그래프를 출력할 때는 팔레트(일종의 도화지)를 먼저 깔고나서 그림을 그리는 원리!
1행 2열의 도화지를 선언하고, 2개의 그래프를 그리기 위해서 2개의 파트로 나눔
- df_train['Survived'].value_counts()
: 'Survived' 라는 Feature 내 value별 count. value_counts() 는 각 value label별 갯수를 count 한다.
- type은 Series이며, Series는 plot() 메서드를 항상 가지고 있어서, 바로 사용하면 된다. - plot()
- explode : pie 그래프에서 데이터들 사이에 거리두기
- actopct : 퍼센트(%)로 출력하기 위한 인자
- ax : 그래프를 어느 축에 출력할 것이며, 어떤 팔레트(subplot)에 선언할 것인지 선언.
ex) ax[0] : 왼쪽, ax[1] : 오른쪽
- shadow : 그래프의 그림자 설정 여부
'Data Analyst > Kaggle & DACON' 카테고리의 다른 글
| [Titanic] Model Development(ML) - Randomforest (지도학습) (0) | 2022.12.04 |
|---|---|
| [Titanic] Feature Engineering(2) - One hot encoding, correlation (0) | 2022.11.29 |
| [Titanic] Feature Engineering(1) - 결측값(Null) 처리 (1) | 2022.10.30 |
| [Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(2) (0) | 2022.10.07 |
| [Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(1) (0) | 2022.10.06 |




댓글