[HDAT] HEV/PHEV 차량 에너지 흐름상태(HevMode) 예측하는 모델 실습
728x90
반응형
※ 2022 HDAT-DA (Hyundai motor group Data Analytic Test) HevMode 예측 모델 실습
: HEV/PHEV 차량의 에너지 흐름 상태 정보인 'HevMode' 정보에 대한 상세 데이터 분석 및 이를 통한 에너지 흐름 상태(HevMode) 예측하는 모델을 생성하는 것이 목표
# 단계별 Flow 정리
1) Dataset check : 데이터 불러오기 & Train, Test dataset, Submission (총 3가지 파일)
2) EDA(Exploratory Data Analysis) : Column들과 Target의 분포도 시각화, 결측값 점검, Correlation 분석
3) Feature Engineering : Feature간 관계성 분석 및 데이터 전처리 작업 (다중 공선성 방지)
4) Model 설계 : Sklearn 패키지 - Logistic Regression과 RandomForestClassifier 사용
5) Model Training 및 Prediction : Train data를 훈련 후에 Test dataset를 통해 평가(성능도) 및 제출
1. 데이터 불러오기 및 형태 확인
Google Drive와 연동 후, 저장된 Dataset (Train, Test)을 불러와 형태 파악하기\
1-1. Import & 데이터 불러오기
# 필요한 라이브러리 Import
import pandas as pd
import numpy as np
import os, random
def seed_everything(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
seed_everything()
# 데이터 불러오기 (총 3가지의 csv 파일 - 경로 : Gdrive)
df_train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/hyundai_test/train.csv')
df_test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/hyundai_test/test.csv')
df_submission = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/hyundai_test/sample_submission.csv')1-2. 주어진 Data 형태 파악하기
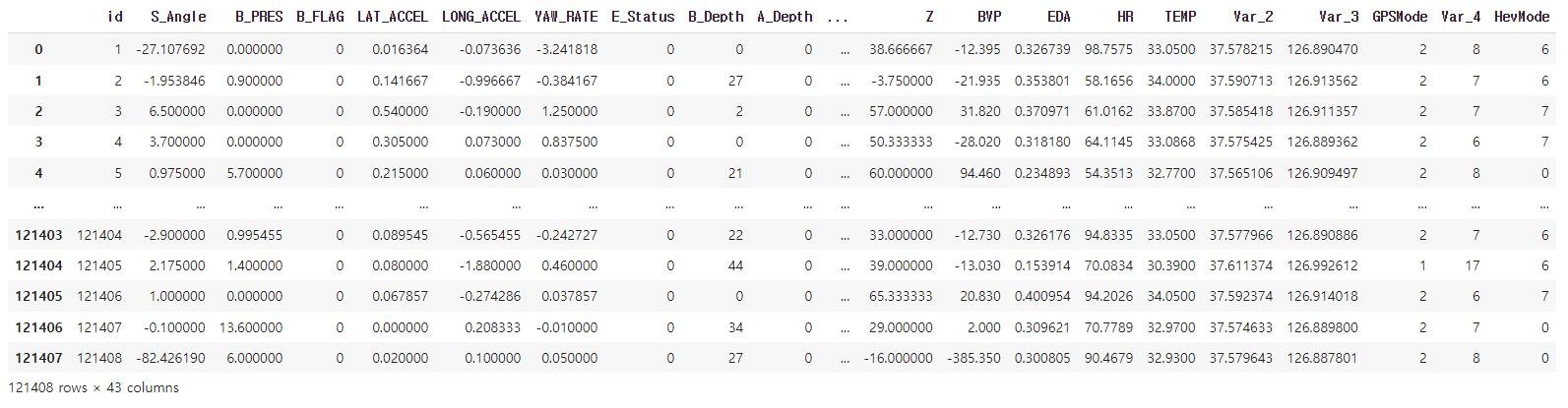
# Train Dataset 형태 확인 - 모델 학습 용도
df_train
>>
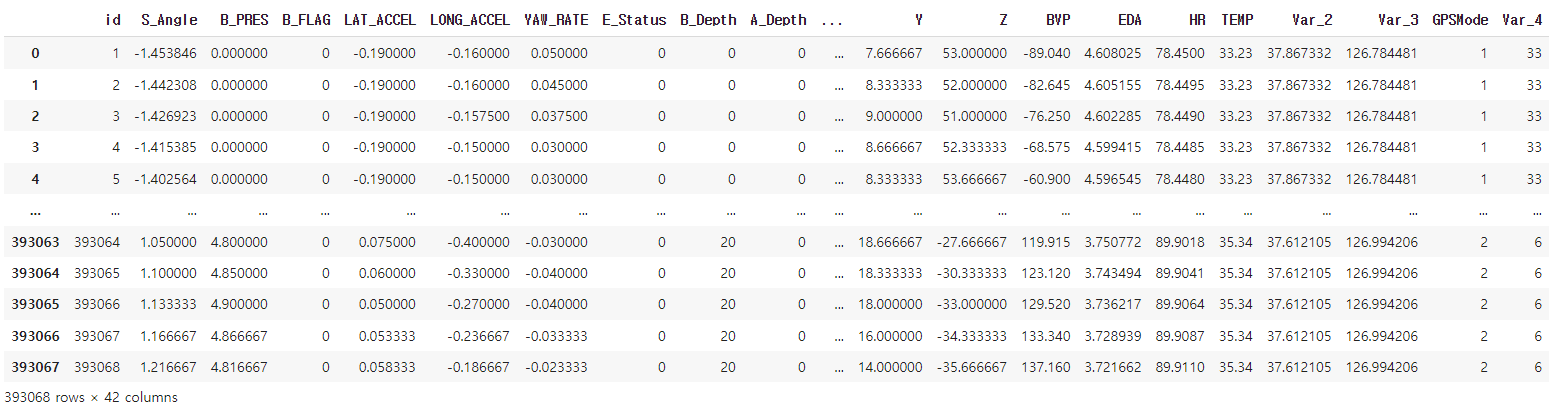
# Test Dataset 형태 확인 - 모델을 통해 최종 제출할 HevMode 예측
df_test
>>
# Sample_submission - 타겟 데이터인 HevMode의 예측값을 제출하는 용도의 파일
df_submission
>>
2. 기초 통계 분석 & EDA
간단한 그래프를 시각하여 이를 통해 필요한 인사이트 도출 및 간단한 데이터 분석
2-1. 수치형 변수의 통계치 확인 & Target의 분포도
# Train dataset 내 Feature 목록 확인
# Train dataset에서 Column에 해당하는 목록
print(df_train.columns)
>>

# Column의 갯수 확인 - 총 43개의 데이터
print(len(df_train.columns))
>>
43
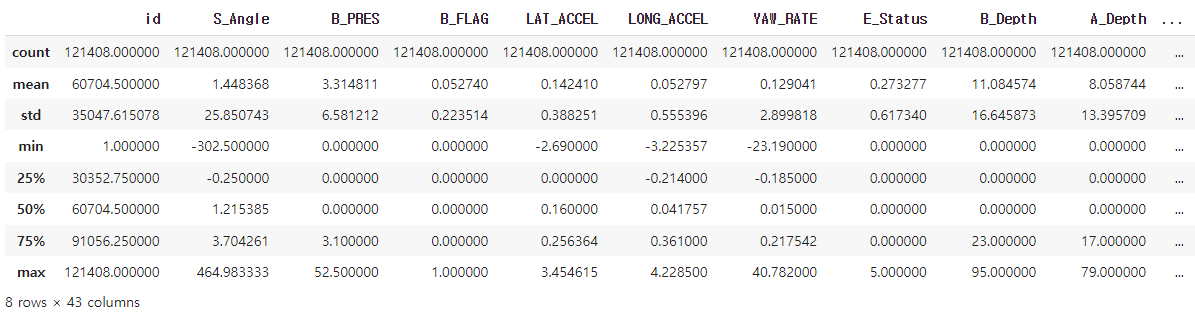
# 기본 통계치(수치형 변수) 출력 - describe( )
df_train.describe()
# count : 행 갯수
# mean : 해당 변수의 평균값
# std : 표준 편차
# min : 최솟값
# 25% : 1사분기 수
# 50% : 2사분기 수
# 75% : 3사분기 수
# max : 최댓값
>>
# Target Label인 'HevMode' 값의 분포도 확인 - value_counts( )
df_train['HevMode'].value_counts()
>>

위를 통해 Targt값이 6인 것은 34,944개, 7은 31,536개 .. 등의 값으로 구성되어있음을 알 수 있다.
# 위에서 확인한 Target의 분포도 시각화 - seaborn, histplot
# 시각화에 필요한 라이브러리 import
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 그래프 출력
sns.histplot(df_train['HevMode'], bins = 13)
plt.show()
>>
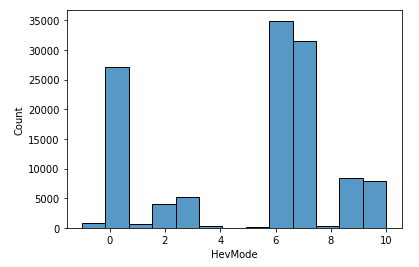
위 그래프와 지금까지 작업을 통해 알 수 있는 인사이트(Insight)는 Train data 갯수는 121,408개이며, '6, 7, 0'의 데이터 갯수가 많아서 Target 변수인 'HevMode'에 심한 데이터 불균형 문제가 있어 정확한 예측은 쉽지 않을 수 있으므로 데이터를 복제하거나 도메인 지식을 활용해야 적합한 결론을 낼 수 있다.
2-2. 결측값(Null) 존재 여부 확인
# 결측값 여부 확인법(1) - isna()
비어있는 Series 가 출력되었다는 것은 결측값이 없다는 의미
temp = df_train.isna().sum()
temp[temp>0]
>>
Series([], dtype: int64)
# 결측값 여부 확인법(2) - for문, format 사용
# 각 Column마다 Null값의 분포를 백분율(%)로 출력한 것
for col in df_train.columns:
msg = 'column: {:>10}\t Percent of Nan value: {:.2f}%'.format(
col, 100 * (df_train[col].isnull().sum() / df_train[col].shape[0]))
print(msg)
# 오른쪽 정렬 = {:>10}
# 왼쪽 정렬 = {:<10}
# 보통 정렬 = {:10}
# 위의 10은 임의의 숫자. 출력하고자 하는 문자열의 수에 따라. 출력할 byte 수에 따라 다르게 설정하면 된다.
>>
column: id Percent of Nan value: 0.00%
column: S_Angle Percent of Nan value: 0.00%
column: B_PRES Percent of Nan value: 0.00%
column: B_FLAG Percent of Nan value: 0.00%
column: LAT_ACCEL Percent of Nan value: 0.00%
...
...
column: Var_2 Percent of Nan value: 0.00%
column: Var_3 Percent of Nan value: 0.00%
column: GPSMode Percent of Nan value: 0.00%
column: Var_4 Percent of Nan value: 0.00%
column: HevMode Percent of Nan value: 0.00%
위에서 볼 수 있듯이 모든 Feature에 대한 결측값(Null)은 없음
- df_train[col] : pandas의 Series 타입으로 각각 Index와 Value들로 이루어짐
- df_train[col].isnull().sum() : column들의 Null값의 총 합(갯수).
ex, '0' (False : 없음), '1 이상' (True : 있음)
- df_train[col].shape[0] : 121,408 (총 column의 수)
+) df_train[col].shape 은 (121408,0) 으로 121,408개의 raw로 이루어짐으로 index[0]을 출력해서 값만 추출
반응형
2-3. Feature 간 상관관계(Correlation) 점검 - 상관분석표 출력
# Feature 간 상관관계 확인 - heatmap( )
- Feature의 수가 너무 많으므로 아래 방법으로 출력!
- 상관 분석표를 볼 때는 Target Label인 'HevMode'을 기준으로 다른 Feature들을 분석하는게 빠르다.
temp = df_train.corr()
mask = np.zeros_like(temp)
mask[np.triu_indices_from(mask)] = True
fig, ax = plt.subplots(figsize = (20,20))
sns.heatmap(temp,
cmap = 'RdYlBu_r',
annot = False,
mask=mask,
linewidths=.5,
cbar_kws={"shrink": .5},
vmin = -1,
vmax = 1
)
plt.show()
>>
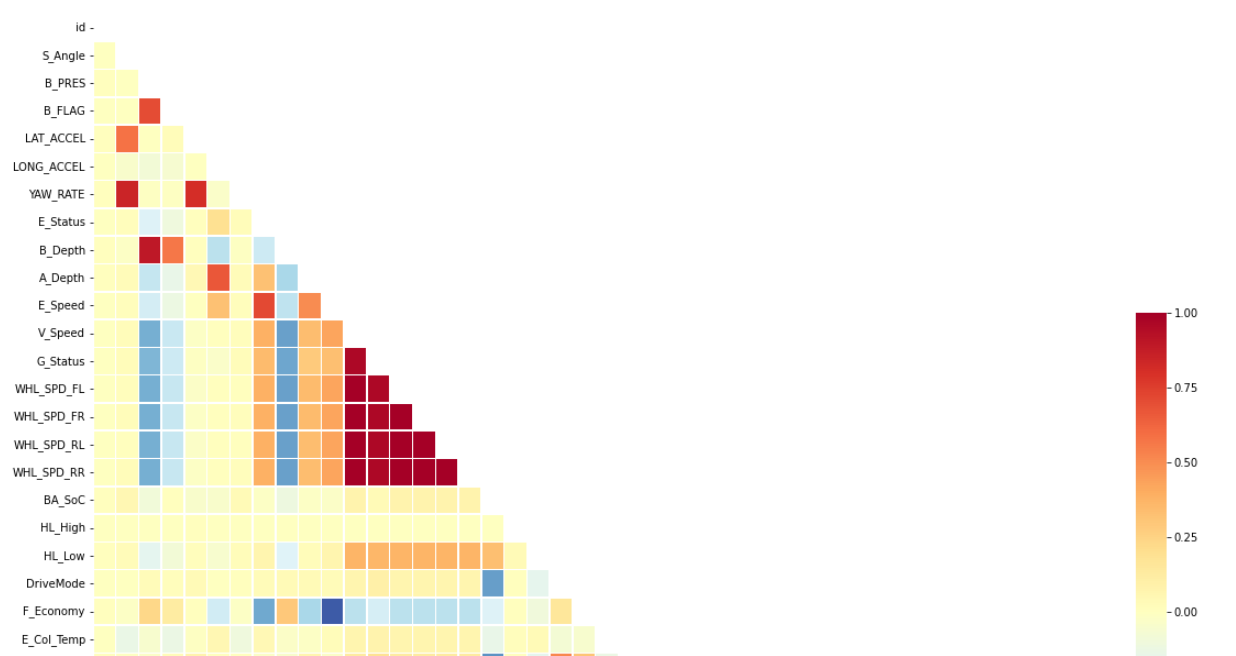
...
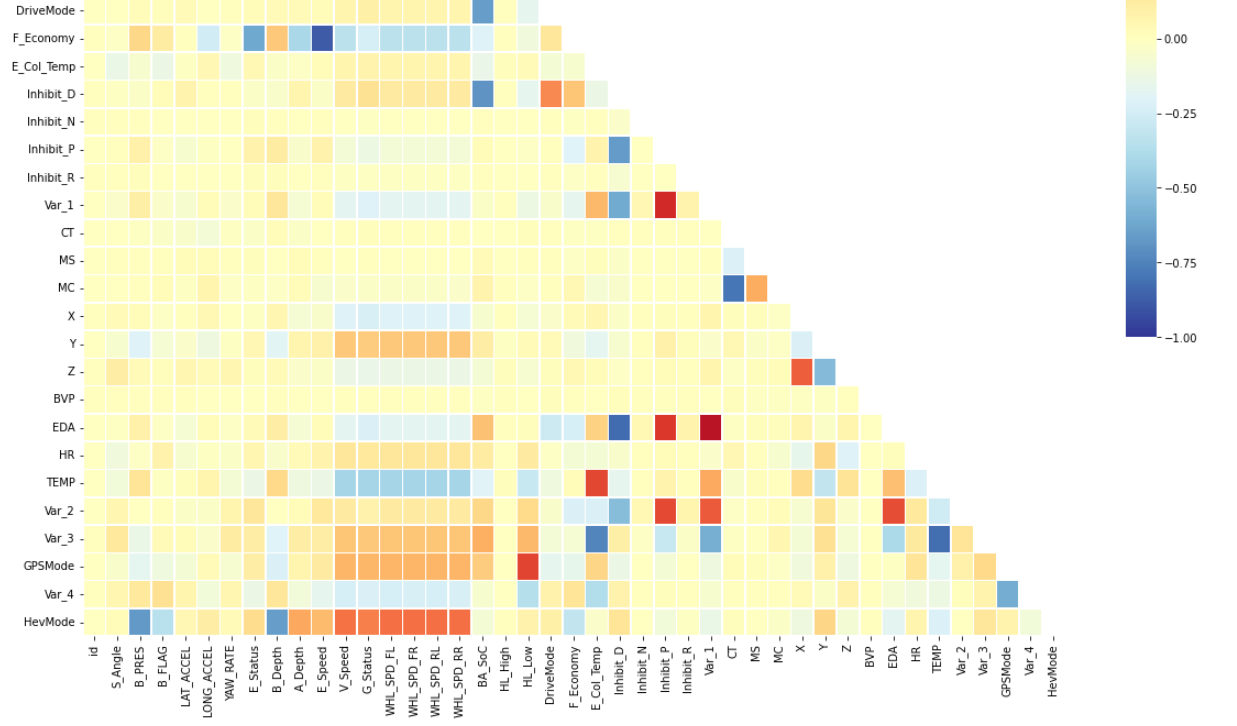
# Target 변수(=HevMode)에 대한 상관관계를 보고 얻을 수 있는 인사이트
1) B_Depth, B_PRES, V_Speed, G_Status, WHL_SPD_FL ~ RR의 변수들과 강한 상관관계를 보인다.
2) WHL_SPD(휠속도)로 시작하는 변수들은 동일한 특성을 가진 데이터로 추정
즉, '다중 공선성(Multi-Collinearity)' 이슈가 발생할 여지가 있다. → '데이터 전처리' 필요
3) Inhibit 변수들(D, N, P, R)과 HL_High, Low 변수는 모두 상관관계가 '0'에 가까운 것을 알 수 있다.따라서 추가적인 원인 분석이 필요하다
# 다중 공선성(Multi-Collinearity) 이란?
다중공선성 문제는 통계학의 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나는 문제이다.
- 즉, 독립변수(Feature) 간 높은 상관관계를 가지는 경우. (상관계수가 -1 or 1에 가까운 경우)
- 회귀분석의 전제는 독립변수들로 변수를 선정하는데, '다중공선성이 있다'는 의미는 각 Feature 간 상관관계가 높으므로 기존 전제에 모순으로 작용되어 다중공선성을 제거하는 작업이 필요하다.
- 더불어 Feature 간 높은 상관계수를 가지는 경우, 실제로 필요한 Target에 대한 예측을 하는 과정에서 중복되는 요인이 발생하여 성능도가 낮게 나오는 문제가 발생할 수 있다.
하지만, 다중공선성이 있다면 상관관계가 높지만 상관관계가 높다고해서 꼭 다중공선성이 반드시 있다고 할 수는 없다
따라서 다중공선성을 판단하는 지표인 분산 팽창 인자(Variance Inflation Factor, VIF)를 보고, 이 지표가 10 이상인 경우에 다중공선성이 있다고 판단하고 전처리 작업을 해주면 된다.
# 추가 원인 분석(1) : 'HL_High'의 분포 확인
분석 결과, '0' 의 값이 전체 비중에서 압도적으로 많이 있음
df_train[['HL_High']].value_counts()
>>
HL_High
0 121390
1 18
dtype: int64
# 추가 원인 분석(2) : 'Inhibit_N'의 분포 확인
분석 결과, '0' 의 값이 너무 많이 있음 (위와 동일)
df_train[['Inhibit_N']].value_counts()
>>
Inhibit_N
0 121406
1 2
dtype: int64
# 추가 원인 분석(3) : 'Inhibit_R'의 분포 확인
분석 결과, '0' 의 값이 너무 많이 있음 (위와 동일)
df_train[['Inhibit_R']].value_counts()
>>
Inhibit_R
0 121403
1 5
dtype: int64
추가 원인 분석(1~3)에서 알 수 있듯이 해당 Feature들은 대부분의 row에서 동일한 값인 '0'을 아주 높은 비중으로 가지고 있으므로 상관관계 분석이 큰 의미가 없다. 즉, 이에 해당하는 변수들은 제거하는 것이 좋다.
3. 데이터 전처리
여기까지 기초통계 및 EDA(Exploratory Data Analysis)을 통해 얻은 인사이트를 바탕으로 데이터 분석이 용이하도록 데이터 가공을 해보자
3-1. 불필요한 Features 제거하기 ( VIF )
- '다중 공선성' 문제 발생을 방지하기 위해 분산 팽창 인자(VIF)가 10인 column은 제거
- 분산 팽창 인자가 '10'을 넘는 인수들을 List에 저장해서 이것을 drop 시킬 column에 할당 (drop_columns)
# 필요한 라이브러리 import
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 별 의미없는 변수인 'id' 제거
drop_columns = ['id']
# 다중 공선성을 야기할 수 있는 변수(VIF > 10) 추출 - drop_columns
feature = df_train.drop(['HevMode'], axis =1)
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(feature.values, i) for i in range(feature.shape[1])]
vif["features"] = feature.columns
picked = list(vif[vif['VIF Factor']>10].features)
drop_columns.extend(picked)
# Train과 Test dataframe에서 제거할 columns drop 하기
df_train_drop = df_train.drop(columns = drop_columns)
df_test_drop = df_test.drop(columns = drop_columns)
3-2. 제대로 drop 되었는지 검토 - Train dataset
df_train_drop
>>
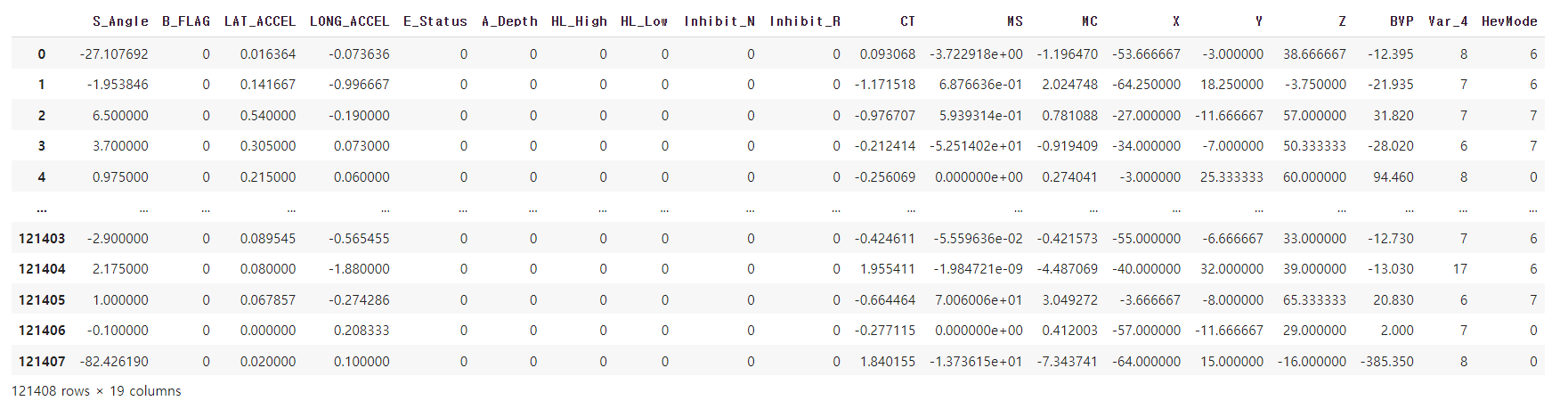
- 'id'와 HL_High, HL_Low, Inhibit_N ... 등의 'VIF > 10'의 조건에 해당하는 Feature들이 제거됨
- drop된 이후 총 19개의 columns 남음 (HevMode 포함) 최소 43개의 columns → 19개
3-3. 위와 동일하게 검토 - Test dataset
Test dataset에도 잘 반영되었는지 확인 (제거 후 총 18개의 column 남음)
df_test_drop
>>

4. 분석 모델 설계 및 예측
- 분석 모델을 생성하기 위해 주어진 데이터(Train, Test)가 정형 데이터(Structured data)이고, Target Label이 이산형 타입(Discrete Type)인 것을 고려해야 한다.
- 선형 회귀 모델 중, 분류 문제에 사용되는 'Logistic Regression'을 사용하고, RandomForest 모델 중 Classifier를 사용해보자
4-1. Train data를 독립변수와 종속변수로 분리하기
train_x, train_y = df_train_drop.drop('HevMode', axis = 1), df_train_drop['HevMode']
4-2. Logistic Regression 모델 학습 및 예측
# 필요한 라이브러리 import
from sklearn.linear_model import LogisticRegression
# 모델 선언
linear_model = LogisticRegression()
# 모델 학습 - fit() 메서드 이용하여 독립변수와 종속변수 선언
linear_model.fit(train_x, train_y)
# 결과 예측 - predict() 메서드 사용
linear_prediction = linear_model.predict(df_test_drop)
4-3. RandomForest 모델 학습 및 예측
# 필요한 라이브러리 import - sklearn의 ensemble
from sklearn.ensemble import RandomForestClassifier
# 모델 선언
rf_model = RandomForestClassifier()
# 모델 학습 - fit() 메서드
rf_model.fit(train_x, train_y)
# 결과 예측 - predict() 메서드 사용
rf_prediction = rf_model.predict(df_test_drop)
5. 제출 파일 생성
- 학습한 모델을 사용하여 예측값(prediction)을 생성하고 submission 파일을 만들어서 제출!
- 2개의 모델(Logistic Regression, RandomForest)을 사용해서 예측값이 2개로 생성. 제출 파일도 2개
- Submission 파일에 예측한 'HevMode' 값을 추가해서 잘 반영되었는지 확인해보기!
linear_submission = df_submission.copy()
rf_submission = df_submission.copy()
linear_submission['HevMode'] = linear_prediction
rf_submission['HevMode'] = rf_prediction
5-1. HevMode 예측값 반영 여부 확인 (Logistic Regression)
linear_submission
>>
5-2. HevMode 예측값 반영 여부 확인 (RandomForest)
>>
5-3. 예측값이 포함된 정답 파일 csv로 저장하기
모델을 통해 예측한 Target Label이 저장된 파일을 csv 형식의 파일로 저장
linear_submission.to_csv('/content/drive/MyDrive/Colab Notebooks/hyundai_test/logistic_submission.csv', index=False)
rf_submission.to_csv('/content/drive/MyDrive/Colab Notebooks/hyundai_test/rf_submission.csv', index=False)
// 여기까지 모든 실습을 맞치며 성능도(=정답률)은 65~68% 정도 나오며, 이후 성능을 높이는 학습도 진행 예정
'Data Analyst > Kaggle & DACON' 카테고리의 다른 글
| [Titanic] Model Development(ML) - Randomforest (지도학습) (0) | 2022.12.04 |
|---|---|
| [Titanic] Feature Engineering(2) - One hot encoding, correlation (0) | 2022.11.29 |
| [Titanic] Feature Engineering(1) - 결측값(Null) 처리 (1) | 2022.10.30 |
| [Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(2) (0) | 2022.10.07 |
| [Titanic] EDA (Exploratory Data Analysis) - 타이타닉 데이터 분석(1) (0) | 2022.10.06 |




댓글