(Regression) Ridge regression 쉬운 풀이! (Regularized Model)
728x90
반응형
Regularized Model
- Ridge regression 설명과 쉬운 풀이

1. Ridge Regression
Ridge Regression은 'β²에 Penalty Term을 부여하는 방식'이다.
- Penalty Term을 추가한 'Regularized Model의 경우 Feature 간 Scaling이 필수'
- β에 제곱을 붙이는 이유는 부호가 (-)인 경우도 있기 때문에

지난 게시물에 Simple/Multi-linear regression 할때 어떤 변수가 제일 중요한지 ranking을 수행할 수 있다고 학습했다. 이때 가장 중요한 것은 'Scaling'. 위의 수식에서 'λ'는 regularization parameter이자 penalty 개념
다시 짚고 넘어가면,
1) 만약 x1(10), x2(100), x3(10000)일 경우,
2) x들의 변수끼리 scale의 차이가 많이 나게 되고
3) β(X가 1단위 증가 했을때 y에 미치는 영향)의 scale이 달라지므로 정확하게 추정할 수 없다.
4) 여기서 Penalty를 부여해도 비중이 다르게 적용될 수밖에 없다.
→ 따라서 계수에 Penalty Term을 주는 방식에서는 Feature에 대해 Scaling을 필수로 해야 한다.
# X's ranking 학습 게시물 (모델 평가 및 성능지표 확인)
2024.04.05 - [Machine Learning/Regression Problem] - (Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리
(Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리
모델의 성능이 얼마나 잘 나왔는지 확인하고 위한 Model 평가와 지표들에 대해서 학습해보자 (지난 게시물 참고) # 지난 게시물 (β(계수) 추정법 & p-value란?) 2024.04.05 - [Machine Learning/Regression Problem] -
derrick.tistory.com
2. hyperparameter(λ) 조절
'λ'는 hyperparameter으로 값을 조절해가면서 validation/test set에서 정확도가 가장 정확도가 높은 것으로 선택하게 된다.

λ값이 너무 높게 되면, 모든 β값이 0에 가까워지게 때문에 Model이 동작하지 않을 수 있고
λ값이 너무 작게 되면, 일반 Model과 동일하게 작동해서 Overfitting이 날 리스크가 있다.
→ 그래서 λ값을 계속 조절해가면서 진행을 해야 한다.
→ λ값이 커질수록 더 많은 Penalty를 부여하는 것이다.
반응형
3. Penalty Term을 부여하는 방식(L₂)
Ridge Regression의 경우, β²에 Penalty Term을 부여할 때 "L₂ - norm = L₂ Regularization" 라고 표현한다.
→ 여기서 L₂ 는 제곱을 의미
→ 제곱 오차를 최소화하면서 회귀 계수 β²을 제한한다.

'L₂ Regularization'이 보인다면, Regularizated Model에 대해 Penalty Term을 통해서 Feature를 Selection하거나 Overfitting을 방지하기 위해서 기법을 사용한다고 보면 된다.
위의 수식에서 'subject to ~'에 해당되는 부분은 'β₁² + β₂²'의 값에 제한(t)을 두겠다는 의미이다.
4. MSE Contour 그래프로 해석
- MSE Contor 중심에서 멀어질수록 Error는 증가하게 된다.
→ Train Error를 조금 증가시키는 과정에서 Overfitting을 방지한다.
- Ridge Estimator와 MSE Contour가 만나는 점이 제약 조건을 만족하며 Error가 최소값을 갖게 된다.
# MSE (=Mean Squared Error)
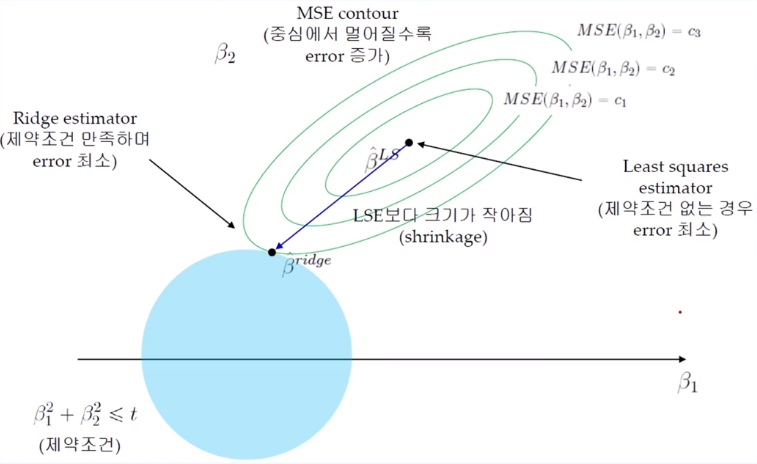
위의 그래프에서 MSE Contour의 중심점이 아무런 제약 조건이 없을 경우의 MSE으로 가장 중요한 기준이 된다.
→ 이 상태가 Overfitting 되어있는 상태라고 보면 된다.
→ 따라서 Training Set에서는 Error가 가장 낮은 상태이다.
그리고 중심점에서 멀어질수록 Error는 당연히 증가하게 된다. (β를 계속 조정)
제약조건(β₁² + β₂²)을 위의 파란색 원으로 표현했을 때, MSE를 조금씩 키우다가 원과 만나는 지점이 바로 제약조건을 만족하면서 error가 최소인 지점이 되는 것이다.
→ 이 과정에서 β의 값은 점점 줄어들고, MSE는 점차 증가하게 된다.
→ 이로써 Overfitting 방지 효과를 얻고, Validation set의 성능이 자연스럽게 올라간다.
# 학습하고 있는 모델의 MSE가 커진다고 해서 꼭 부정적인 것이 아니다!
: 그만큼 specifically하게 학습하지 않고, 적당히 학습함으로써 새로운 데이터에서도 잘 training될 수 있도록 Overfitting을 방지하는 효과를 볼 수 있다.
5. Ridge는 미분이 가능하다?
- Ridge는 미분이 가능하기 때문에 Closed Form solution을 구할 수 있음
- 빠르게 해를 찾을 수 있다는 장점이 있다.
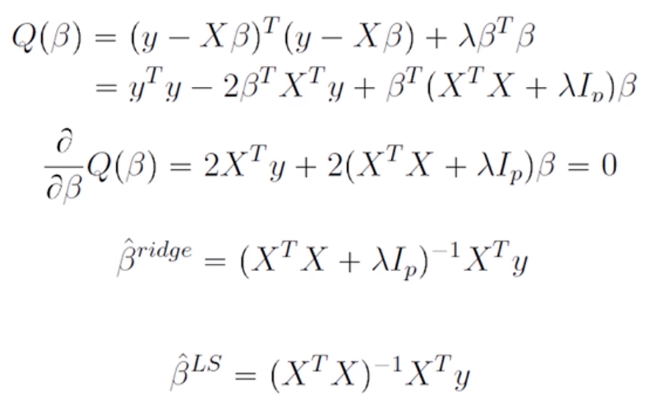
위의 수식에서 볼 수 있듯이 β에 대해 편미분을 통해 빠르게 에러를 최소화할 수 있는 값을 추정할 수 있다.
6. Ridge Regression 특징
- Ridge는 해 공간에서도 볼 수 있듯이 Feature Selection은 되지 않는다
→ 하지만 불필요한 Feature는 충분히 0에 거의 수렴하게 만들어버림
- Ridge Regression은 Feature의 크기가 결과에 큰 영향을 미치기 때문에 Scaling이 중요함
- 다중공선성(Multicollinearity) 방지에 가장 많이 쓰임
Ridge Regression은 β의 값이 큰 변수들은 빨리 줄어들게 된다.
→ why? 제곱이 있기 때문에 더 빨리 β의 값이 커지게 되고, 그만큼 λ에 대해 Penalty를 더 빠르고 많이 받게 된다.
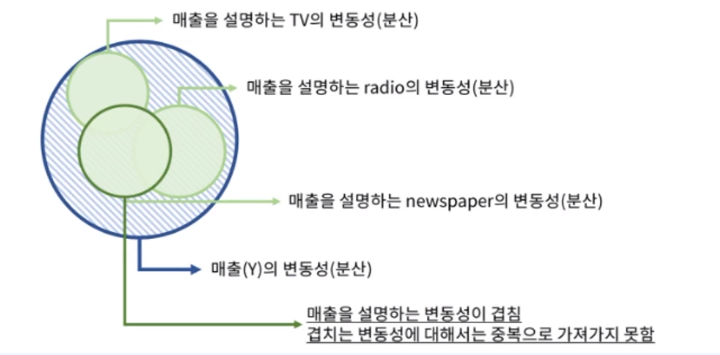
# 다중공선성(Multicollinearity) - 위의 그래프 참고
: 다중공선성은 Regression 문제에서 일부 예측 변수가 다른 예측 변수와 상관 정도가 높아서 데이터 분석 시 부정적인 영향을 미치는 현상을 의미한다.
위의 예시에서 TV와 radio가 겹치는 부분에 대해 매출을 설명하는 변동성이 겹치게 되는데, 이렇게 겹치는 변동성에 대해서는 중복으로 가져가지 못하는게 된다.
'Machine Learning > Regression Problem' 카테고리의 다른 글
| (Regression) LASSO 기초 정리 (Ridge와 차이점은?) (0) | 2024.07.04 |
|---|---|
| (Regression) Ridge Code 실습 및 예제 (Regularized Model) (1) | 2024.07.03 |
| (Regression) Feature selection을 보완한 기법, 'Penalty Term'이란? (0) | 2024.04.10 |
| (Regression) Overfitting 방지하는 Feature Selection 기법의 종류 정리 (0) | 2024.04.07 |
| (Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리 (0) | 2024.04.05 |




댓글