(Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리
728x90
반응형
모델의 성능이 얼마나 잘 나왔는지 확인하고 위한
Model 평가와 지표들에 대해서 학습해보자
(지난 게시물 참고)
# 지난 게시물 (β(계수) 추정법 & p-value란?)
(Regression) 모델의 에러를 가장 낮출 수 있는 'β(계수) 추정법' p-value란?
모델의 에러(Error) 수식('E(Y) = β(0) +β(1)X')를 바탕으로 가장 낮은 에러를 취하기 위한 β(계수)의 값은 무엇인지 추정하는 법에 대해 학습해보자 모델의 Error를 가장 낮추기 위한 'β (계수) 추정법'
derrick.tistory.com
1. Model 성능에 대한 평가 기준
# Model의 평가 기준
다양한 알고리즘과 모델이 있는만큼 해당 Model를 평가하는 기준은 정말 다양하다.

모델을 평가하는데에는 정성적인 평가와 정량적인 평가가 있다.
- 정성적 평가 : 모델들 간 평가 기준이 동일하다.
- 정량적 평가 : 에러가 얼마만큼 된다
2. 정성적인 방법
1) R²
Regression Model에서 정성적인 평가를 할 때는 R²(R square)를 많이 사용한다.
- R²는 평균으로 예측한 것 대비 분산을 얼마나 축소시켰는지에 대한 판단
→ 보통은 아래의 수식과 달리 Correlation의 제곱으로 표현한다.

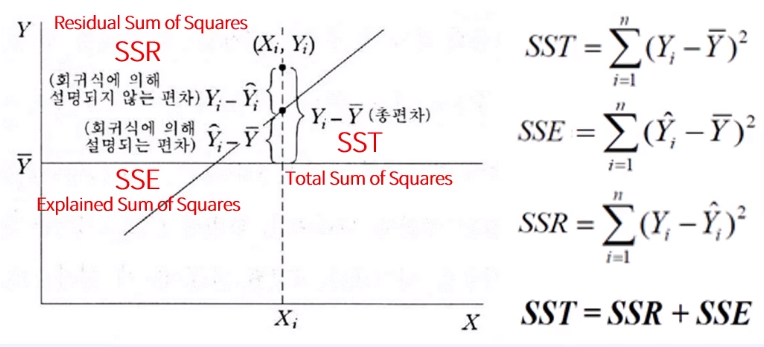
- 정성적인 판단이 필요한 이유는 통상적으로 Model의 예측력을 판단하기 위해서이다.
→ 0~1 사이의 값을 갖고 1에 가까울수록 좋은 모델
위의 차트 중, SSE가 평균값이라면 이와 실제값의 차이는 SST로 표현할 수 있게 된다.
2) R²가 어느 정도면 쓸만한가?
현업에서 R²가 0.3 이상인 경우는 찾기 힘들다
→ R²의 경우, 0.25 정도가 되어도 유의미하다고 판단할 수 있다.
→ 'R²=0.25' 라는 것은 y를 평균으로 예측한 것 대비 분산을 25% 정도 줄여준 것으로 해석할 수 있다.
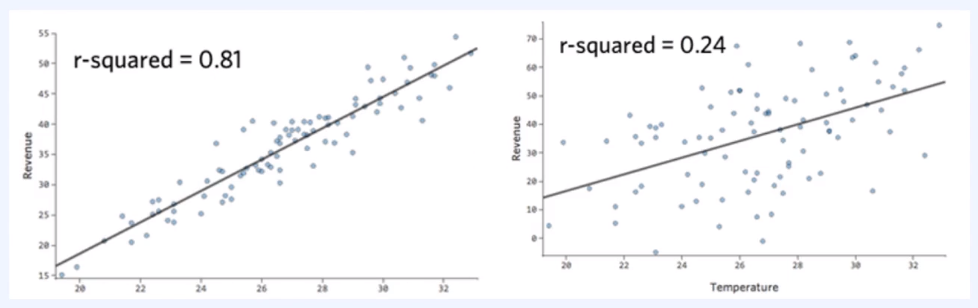
위의 왼쪽 그래프(r-squared = 0.81)는 y값을 잘 예측한 경우라고 볼 수 있다. 하지만, 현업에서는 0.4를 넘어가는 경우는 거의 없고 0.25 정도만 되어도 분석할만한 가치가 있다고 판단
반응형
3. 정량적인 방법
1) Average Error - 평균오차 (잘못된 방법)
- 실제 값에 비해 과대/과소 추정 여부를 판단
- 부호로 인해 잘못된 결론을 내릴 위험이 있다.
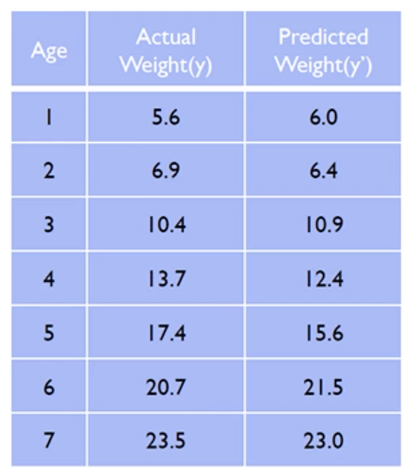

평균오차법은 성능 평가를 하는데 사용하지 않아야 하는 대표적인 예가 될 수 있다. 위의 경우, 실제 몸무게와 예상 몸무게의 차이가 (+) 혹은 (-)로 나오게 되는데, 그 부호에 의해 잘못된 추정값이 나올 수 있다.
2) Mean Absolute Error(MAE) - 평균 절대 오차
MAE는 실제값과 예측값 사이의 절대적인 오차의 평균을 이용한다.
→ 차이값에 절대값을 씌움
→ 미분이 불가능해서 잘 쓰이지 않는다. (치명적 단점)

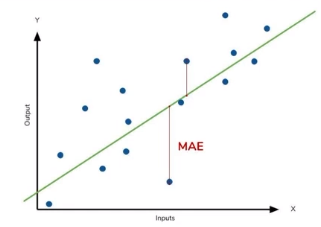
절대값을 씌움으로써 부호에 대한 불확실성을 해소했음에도 MAE를 잘 쓰지 않는 이유는, "미분이 불가능하다"
성능 지표를 활용할려면 loss function도 함께 가지고 가야 한다.
→ 성능지표에 맞게 loss function이 구성되어야만 모델이 잘 학습될 수 있다.
3) Mean Absolute Percentage Error(MAPE) - 평균 절대 비율 오차
MAPE는 현업에서 종종 쓰이는 기법으로 정량적/정성적인 해석이 모두 가능하다.
- 실제값 대비 얼마나 예측값이 차이가 있는지를 %로 표현
→ 정성적인 표현으로도 해석 가능
- 상대적인 오차를 추정하는데 주로 사용
- 미분은 불가능하지만, 정성적/정량적 해석이 모두 가능하기 때문에 종종 쓰인다.
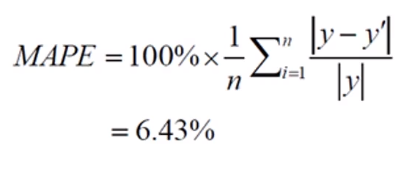

4) (Root) Mean Squared Error - (R)MSE
RMSE는 부호의 영향을 제거하기 위해 절대값이 아닌 제곱을 취한 지표이다.
→ MSE와 함께 많이 쓰이는 지표


Q) RMSE는 왜 루트를 씌운걸까?
→ MSE는 square(제곱)을 하기 때문에 에러가 점점 커질수록 MSE값도 제곱으로 커지게 되기 때문에 Root를 붙여서 이를 방지하는 용도이다.
4. Model 평가 및 해석 순서 (Regression) ★★★
1) Model 성능 체크 - 정성적, 정량적
Model의 성능이 잘 안 나온다면, Data Quality를 재검토하는 과정이 필요하다
→ 위에서 학습한 정성적/정략적인 지표를 통해 Model 성능을 1차적으로 평가
→ 성능이 잘 나오지 않았다면, 다른 모델을 사용할 수도 있지만 우선 Data Quality 체크부터!
데이터의 퀄리티가 높다면 Simple/Multi- Linear regression만으로 높은 성능을 낼 수 있다.
→ 그리고 Model Loss function은 평가지표로 하는 것이 좋다!
모델의 성능이 어느 정도 나왔다? → 정성적 지표의 경우, 'R²=0.25' 이상이면
→ 다음 단계인 p-value를 통해 의미 있는 변수 추출
→ 만약에 그렇지 않으면 Data Quality Check! → 데이터에 문제가 없다면 다른 모델 활용
2) P-value를 확인하여 의미 있는 변수 추출
P-value의 threshold가 0.05 보다 낮아야 되는 것이 핵심!
→ 0.05 보다 높은 변수들은 해석을 안해도 무방
3) β 활용, X 1단위 증가당 Y에 얼마만큼 영향을 미치는지 판단
가장 낮은 에러를 갖게 하는 β 값을 추정하고, X's 변수들 중 Ranking을 통해 어떤 변수가 X의 증가량에 따라 Y에 얼마나 많은 영향을 끼치는지 확인해보고 판단해야 한다.
X's scaling을 하고나면 X가 1단위 증가했을 때의 Y에 얼마만큼 영향을 미치는지 알 수 없기 때문에
→ Scale을 하지 않고 β에 대해서 X 1단위 증가에 따른 Y에 미치는 영향력을 해석하고
→ Scaling을 하고나서 β를 보고 X's ranking을 통해 X 변수들에 대한 중요도를 판단하는 flow가 이상적이다
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE
'Machine Learning > Regression Problem' 카테고리의 다른 글
| (Regression) Ridge regression 쉬운 풀이! (Regularized Model) (0) | 2024.07.02 |
|---|---|
| (Regression) Feature selection을 보완한 기법, 'Penalty Term'이란? (0) | 2024.04.10 |
| (Regression) Overfitting 방지하는 Feature Selection 기법의 종류 정리 (0) | 2024.04.07 |
| (Regression) 모델의 에러를 가장 낮출 수 있는 'β(계수) 추정법' p-value란? (0) | 2024.04.05 |
| (Regression) 쉽게 이해하는 Loss Function - Error, Variance, Bias 관계는? (0) | 2024.04.05 |




댓글