(Regression) 모델의 에러를 가장 낮출 수 있는 'β(계수) 추정법' p-value란?
728x90
반응형
모델의 에러(Error) 수식('E(Y) = β(0) +β(1)X')를 바탕으로 가장 낮은 에러를 취하기 위한 β(계수)의 값은 무엇인지 추정하는 법에 대해 학습해보자
모델의 Error를 가장 낮추기 위한
'β (계수) 추정법'
1. Mathematical Expression
1) Simple & Multi-Linear Regression
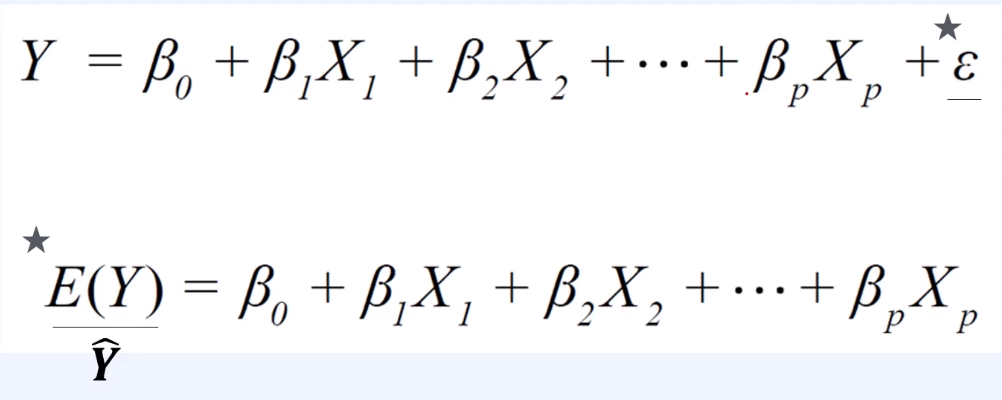
위의 수식처럼 참값(Y)에 불가피하게 붙는 Error(ε)를 가장 낮출 수 있는 추정값(E(Y), y^) β값을 찾아내는 것이 목표이다.
위의 수식과 같이 Error(ε)는 참값과 추정값(E(y))의 차이로 볼 수 있다.
'β0'은 y절편으로 x가 0일때의 값이고, 'β1'의 값은 추정한 모델의 기울기이다.
→ Multi-linear regression의 경우, 독립 변수(X)가 2개 이상일 때는 2차원이 아닌 평면으로 확장된다.
2) β 추정법
- 각 β에 대해 편미분을 사용하여 추정을 수행
- Linear regression의 Loss function은 'Closed Form Quadratic'이기 때문에 미분만으로 쉽게 추정이 가능하다.
- β가 여러 개일 때는 똑같이 각 β에 대해 미분을 수행한 후에 추정
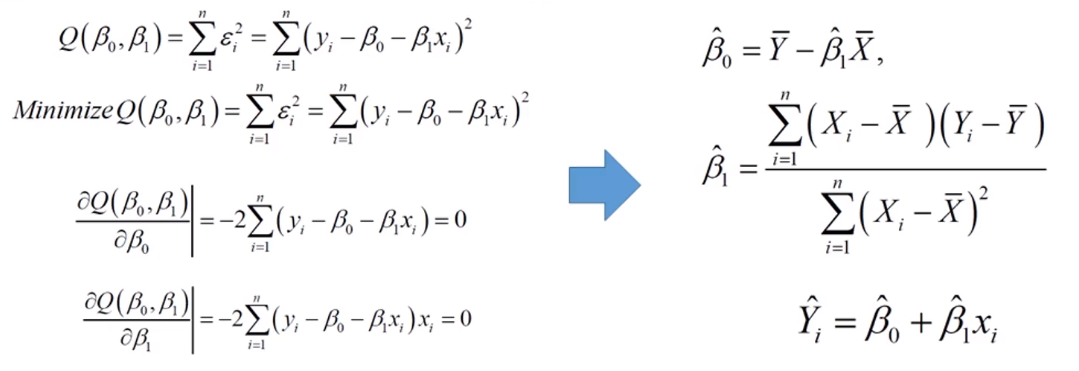
편미분을 한 결과값이 '0'일 때가 에러가 가장 낮은 값을 갖기 때문에 위의 수식을 '0'으로 세팅하고 β값들을 추정하면 된다.
→ 수식을 통해서 먼저 'β1'을 계산한 이후에 'β0'을 추정할 수 있다.
2. β 검증 : p-value
1) 추정한 β에 대한 검증 (귀무가설 vs 대립가설)
추정한 β에 대해 검증 수행 - 귀무가설 vs 대립가설
- β에 대한 p-value가 낮으면 기울기가 0이 아닌 것으로 판명하고, 반대로 높다면 귀무가설일 가능성 ↑
→ 통상적으로 p-value가 0.05 이하면, 의미 있다고 판단
→ β의 기울기가 0일 확률이 0.05 이하라고 해석
- 즉, p-value가 0.05 이하면 H0 (귀무가설)은 기각되며, H1이 채택됨.
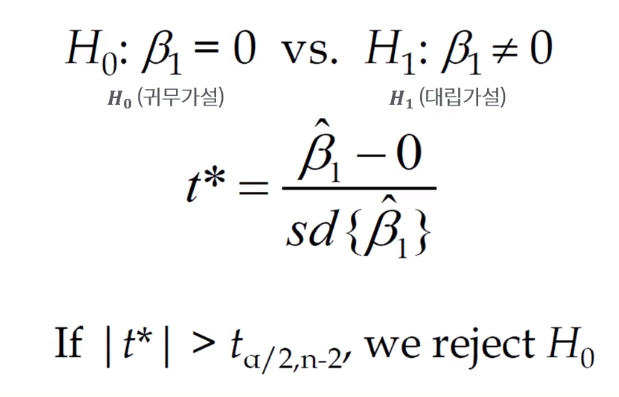
위와 같이 귀무가설과 대립가설은 β1의 값이 '0일 것이다' vs '0이 아닐 것이다'로 대립된다.
→ 'β1 = 0'이라면, 평균으로 예측하는 것과 동일하다. 사실상 모델이 필요 없다는 의미 (x값이 증가함에 따라 y값에 영향을 미치지 않는다는 뜻)
→ 'β1 ≠ 0'이라면, 계수가 y값에 얼마나 영향을 미치는 지에 대한 검증이 되었다고 볼 수 있다.
위의 검증을 판단할 수 있는 factor를 'p-value'라고 한다.
2) Model Output 해석 방법
# Factor1 : β1 (β0 제외)
- X가 1단위 증가 시, Y에 영향을 미치는 정도
: β1이 10인 경우, X1이 1 증가했을 때 Y에 10의 영향을 미침
- βi의 값이 크면 Y에 영향을 크게 미친다고 판단할 수 있다.
→ 하지만, X's 간 Scale이 다를 수 있기 때문에 X's 간 상대적인 비교는 불가
ex) 키와 몸무게는 기본적으로 Scale이 다름
# Factor2 : p-value
- βi 값이 크지만, p-value 값이 높으면 의미가 없다.
→ 통상적으로 p-value는 0.05 이하여야 유의미하다.
★ 따라서, βi값과 p-value값, 2가지 조건이 맞아야 유의미하다고 판단할 수 있다.
그렇다면, X's 간 중요한 변수를
Ranking 하고 싶은 경우에는 다른 방법이 없을까?
X's 간 중요한 변수를 ranking하고 싶다면, 'X's Scaling'을 수행하면 된다.
→ X들의 평균값으로 동일하게 맞춰주면 된다. (Scaling)
이와같이 데이터들을 preprocessing한 이후에 모델을 통해 β를 추정하게 되면, 어떤 X가 더 중요한 변수인지 추론할 수 있게 된다. Scaling을 통해서 X의 평균치가 동일한 상황에서 β값이 가장 높은 변수가 y값에 가장 많은 영향을 미친다는 것을 알 수 있다.
→ 그러나, 여기서 β값이 높지만 p-value값이 0.05 이하가 아닐 경우 유효성은 떨어진다.
그럼 factor1과 factor2의 중요도는?
뭐가 더 중요한 것일까?
1. p-value를 먼저 확인하고, 0.05보다 낮은 경우의 변수 select
2. 그 변수의 β값을 비교한다.
→ X's scaling을 했다면, 변수간 중요도를 볼 수 있다.
3. 만약 β의 값이 같다면, 그 중 p-value가 낮은 변수가 가장 중요한 변수이다.
→ p-value가 낮을수록 검증이 잘 되었다는 의미로 볼 수 있다.
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE
'Machine Learning > Regression Problem' 카테고리의 다른 글
| (Regression) Ridge regression 쉬운 풀이! (Regularized Model) (0) | 2024.07.02 |
|---|---|
| (Regression) Feature selection을 보완한 기법, 'Penalty Term'이란? (0) | 2024.04.10 |
| (Regression) Overfitting 방지하는 Feature Selection 기법의 종류 정리 (0) | 2024.04.07 |
| (Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리 (0) | 2024.04.05 |
| (Regression) 쉽게 이해하는 Loss Function - Error, Variance, Bias 관계는? (0) | 2024.04.05 |




댓글