(Regression) Overfitting 방지하는 Feature Selection 기법의 종류 정리
728x90
반응형
Feature Selection을 왜 해야 하는지
어떤 종류들과 어떻게 사용하면 되는지 학습해보자

# 함께 보면 좋은 게시물 (모델 평가 및 지표)
2024.04.05 - [Machine Learning/Regression Problem] - (Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리
(Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리
모델의 성능이 얼마나 잘 나왔는지 확인하고 위한 Model 평가와 지표들에 대해서 학습해보자 (지난 게시물 참고) # 지난 게시물 (β(계수) 추정법 & p-value란?) 2024.04.05 - [Machine Learning/Regression Problem] -
derrick.tistory.com
1. Feature Selction을 하는 이유
Feature Selection은 'Overfitting을 방지하기 위해서 수행'한다.
- Feature의 수가 많아질수록 Model Complexity(복잡도)는 높아진다
- Model Complexity가 높아질수록 Bias는 낮아지는 반면 Variance가 높아지게 된다.

위의 그래프와 같이 Variance가 높아짐에 따라 결국 에러가 증가할 수 밖에 없다.
→ 따라서 우리는 Variance와 Bias가 적당한 값을 갖는 위치를 찾아야 한다.
→ 이때, Overfitting을 방지하는 'Feature Selection' 기법을 활용하여 Bias와 Variance의 Trade-off 최적점을 도출해야 한다.

# Underfitting
: Bias ↑, Variance ↓
# Ovefitting
: Bias ↓, Variance↑
→ Underfitting과 Overfitting 모두 잘못된 현 상이고, 적절하게 appropriate fitting이 되도록 해야 한다.
2. Feature Selection 기법 종류와 원리
1) Supervised Variable Selection - Exhaustive Search (완전 탐색)
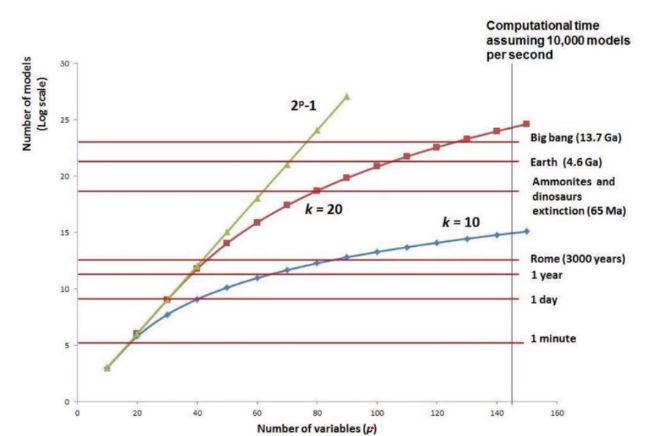
지도학습에서 Feature(=Variable) Selection의 경우, 첫번째로는 완전 탐색(Exhaustive Search)가 있다.
- 모든 경우의 수를 다 해봄으로써 Feature의 최적 조합을 찾아낸다.
- 경우의 수는 2ⁿ-1 (n은 Feature의 개수)

위의 예시에서는 총 7개의 Subsets의 정확도를 바탕으로 최적의 조합을 찾아낸다
→ Training Set의 정확도보다 Test Set의 정확도를 보는 편
하지만, 문제점은 Feature가 많아질수록 시간이 너무 오래 걸린다는 것
→ 시간이 Exponential 하게 증가한다.
→ Feature가 많으면 이 기법을 권장하지는 않지만, 아이러니하게 반대로 Feature가 적을 경우에는 Overfitting이 잘 일어나질 않는다. 그래서 거의 사용되지 않는 기법이다.
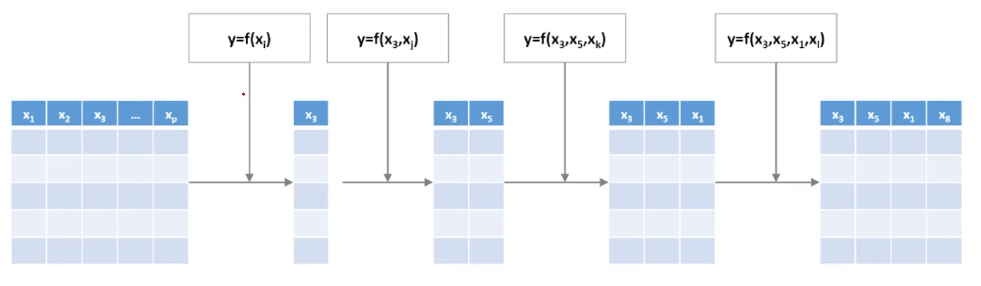
2) Forward Selection & 원리
첫번째였던 완전 탐색보다는 Rough하게 Selct하는 기법
- Multiple linear Regression에서의 Forward Selection가 유용하다
- 처음에는 Variable이 없이 시작해서 하나씩 중요한 변수들을 Sequentially하게 추가
→ 그리고 한번 선택된 variable은 절대 지우지 않는다.
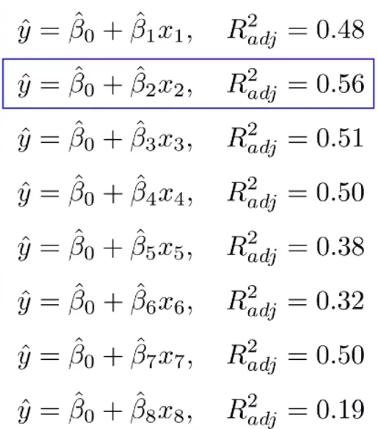

8개의 Variable로 예를 들어보면, 처음에는 모든 X에 대해 8번을 다 R-square를 모두 해보면 2번째 X의 값이 제일 높으므로 기록해두고
# R-square
: Regression Model에서 대표적으로 수행하는 정성적인 평가 기법으로 평균으로 예측한 것 대비 분산을 얼마나 축소시켰는지에 대한 판단을 할 수 있다. R-square값이 0.25 정도만 되어도 유의미하다고 해석할 수 있다.

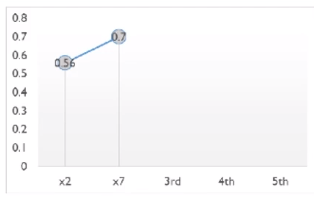
x2는 확정적으로 넣어두고, 다시 2를 제외한 1부터 8까지 R-square한 후 가장 높은 값을 갖는 x7의 값을 고정한다.
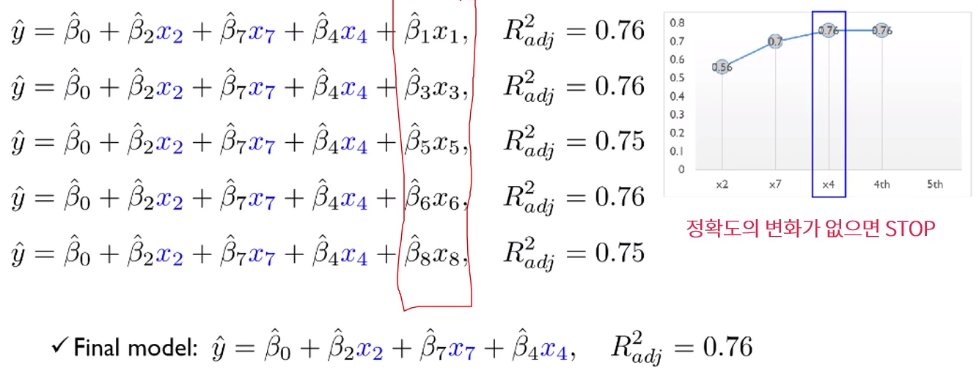
이와 같은 방법으로 반복적으로 수행하게 된다. 마지막에 정확도의 변화가 없으면(커지거나 작아지지 않을 경우) 수행 종료
3) Backward Elimination
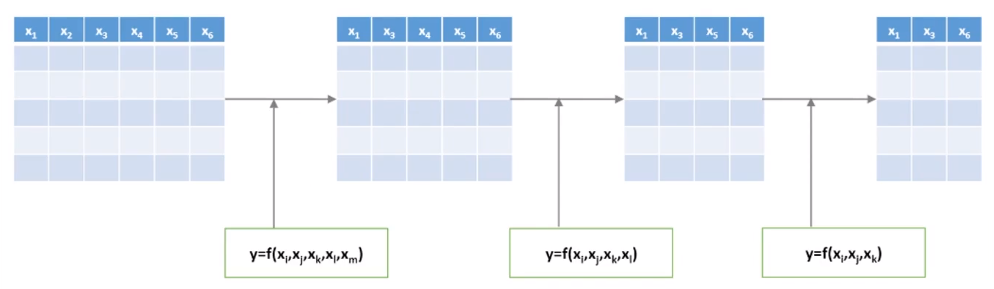
Forward와 다르게 'Backward Elimination' 기법에는 말 그대로 '뒤에서부터 제거'하는 방법을 추가된다.
- 처음에는 모든 variable을 사용하고, 정확도에 영향을 미치지 않는 불필요한 variable을 sequentially하게 제거
→ 한번 제거된 variable은 절대 다시 선택하지 않는다.

Forward Selection과 마찬가지로 처음부터 모든 변수(8개의 Variables)를 모두 넣고 시작한다.

그리고 변수 하나씩을 제거하면서 R-square를 돌리는데, R-square값이 가장 큰게 나온 변수는 제거한다. 그리고 하나씩 다시 해본다.

이 과정을 반복적으로 수행하다가 R-sqaure값이 낮아지는 시점에 Stop!
위의 예시에서는 x3과 x8를 제거했을 때, R-square값이 0.77 → 0.76으로 낮아졌으므로 Stop하게 되고, x3번째 변수만 제거했을 때 최적의 결과가 나온다고 해석할 수 있다.
4) Stepwise Selection
위의 Forward나 Backward 기법은 최적을 보장하지는 못한다. 따라서 어떤 sequence를 내포하고 있는 변수의 경우에 해당 기법을 사용하기에는 리스크가 있는데, 이를 보완하기 위한 기법이 바로 'Stepwise Selection'.
- Forward Selection과 Backward Elimination을 번갈아 가면서 수행
- Forward Selection과 Backward Elmination 각각의 기법보다 시간은 오래 걸릴 수 있지만, 최적의 Variable Subset을 찾을 가능성이 높다!

처음에 Forward Selction으로 시작해서 x2가 가장 높은 R-square값이 높다면, x2를 Select하고

그 다음에 다시 넣어봤을때 x7가 다음으로 높게 되면, 기존 수식에 x7 추가

그러다가 3~4개를 Select했다면, 반대로 Backward Elimination을 수행한다. 1개씩 제거함으로써 최적의 R-square값을 갖는 조합을 찾아낸다.
3. 한계점

이와 같은 Feature Selection은 최적화를 보장하지 않고, 변수들 간의 상관관계를 고려하지도 않은 채 Sequencial하게 나열되어있는 변수들에 대해서 최적의 변수들을 찾아가는 것이다.
→ 하지만, '만약 x2와 x5가 높은 상관관계가 있어서 항상 같이 묶여야 한다면?' 이러한 상호작용을 고려하지 않기 때문에 Forward, Backward, Stepwise 기법은 최적의 Subset을 보장할 수는 없다.
'Machine Learning > Regression Problem' 카테고리의 다른 글
| (Regression) Ridge regression 쉬운 풀이! (Regularized Model) (0) | 2024.07.02 |
|---|---|
| (Regression) Feature selection을 보완한 기법, 'Penalty Term'이란? (0) | 2024.04.10 |
| (Regression) Model 평가 및 지표 해석하는 방법! - 성능지표 총 정리 (0) | 2024.04.05 |
| (Regression) 모델의 에러를 가장 낮출 수 있는 'β(계수) 추정법' p-value란? (0) | 2024.04.05 |
| (Regression) 쉽게 이해하는 Loss Function - Error, Variance, Bias 관계는? (0) | 2024.04.05 |




댓글