(sklearn) DataHandling 기초 & 실습 - 결측치 처리
728x90
반응형
# 결측치 처리
- 일반적인 처리 방법
- sklearn을 이용한 처리 방법
- pandas를 이용한 처리 방법
파이썬 기본 함수와 특성을 이용해서
데이터를 다루는 실습을 해보자

1. Import & DataFrame 생성
결측치를 처리하는 다양한 방법에 대해 공부해보자
# 필요한 패키지 import
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer, KNNImputer, MissingIndicator
import warnings
warnings.filterwarnings('ignore')import warnings
warnings.filterwarnings('ignore')
: warning을 'ignore'로 해두면 무의미한 경고메시지를 무시할 수 있다.
data = {
'id': [1000, 1001, 1002, 1003, 1004, 1005, 1006],
'date': ['20230101','20230102','20230103','20230104','20230105','20230106','20230107'],
'age': [21, 56, 33, 48, 27, 42, 32],
'income': [67000, 220000, 97000, 166000, 81000, 157000, 96000],
'gender': ['Male', 'Female', 'Female', 'Male', 'Male', 'Female', 'Female'],
'education': ['Bachelors', 'PhD', 'Masters', 'Masters', 'Bachelors', 'Bachelors', 'Bachelors'],
'passed': [False, True, True, True, False, False, True],
'measurement': np.random.randn(7).round(2)
}
df = pd.DataFrame(data)
df
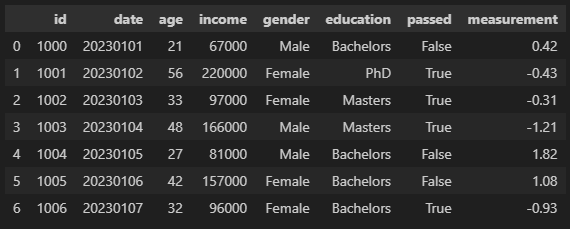
위와 같이 임의의 데이터를 만들어서 DataFrame(df) 생성
2. Column 분석하기
1) 칼럼간 상관계수 계산

상관계수는 쉽게 말해서 내가 변함에 따라 상대가 변하는 정도를 나타내는 지표로 볼 수 있다. 각 칼럼(Feature)끼리는 상관계수가 '1'인 것을 확인할 수 있 수 있다.
→ 위에서 age와 income의 관계를 보면, 나이가 증가할수록 income(수입)이 증가한다는 것을 유추할 수 있다.
2) 칼럼 정보 확인하기

info()를 통해 Column들을 보면, Null(결측치)인 값들은 하나도 없다.
date가 object로 문자열로 들어가있고, 대부분 int64로 비효율적으로 자료가 구성된 것을 확인할 수 있다.
→ 자료형이 적절하게 들어가있지 않다.
3) 데이터 값 살펴보기
'df.values'를 실행하면 아래와 같이 각 Series별 가지고 있는 값(Values)들을 확인할 수 있다.
→ 얻을 수 있는 insight는 크게 없다.

반응형
3. 결측치(missing value) 처리
1) 임의로 결측치(Null) 삽입하기
missing values를 처리하는 실습을 하기 위해서 임의로 결측치를 삽입해보자
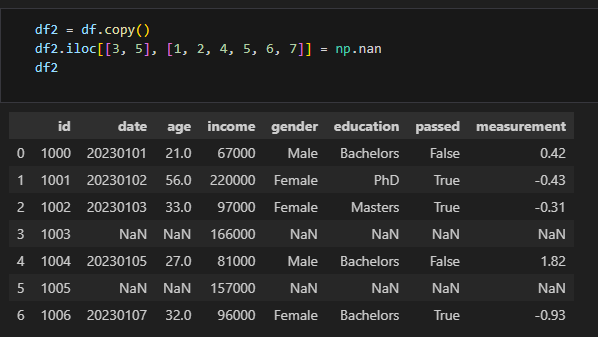
위에서는 3, 5번째 행에 대해서 1, 2, 4, 5, 6, 7번째 row에 해당되는 데이터들을 NaN 처리
2) 각 컬럼별 결측치 세어보기
'isnull().sum()'를 통해 각 Feature별로 결측치 현황을 파악할 수 있다.

3) 결측이 포함된 데이터만 보기
'isnull()' 함수를 통해 null이면 True를 반환하고, any()를 통해 True인 데이터만 출력
→ 즉, null값을 가지는 모든 데이터들을 볼 수 있도록

4) 결측치가 포함된 행 삭제
dropna() 를 통해 결측치를 삭제하는데, 'axis=0'을 기준으로 즉, 행을 기준으로 삭제한다.
→ 'axis = 0' : 행 기준으로 삭제
→ 'axis = 1' : 열 기준으로 삭제


5) 결측치를 특정값으로 치환하기
Null이 들어가면 에러가 많이 날 수 있으므로 특정한 값으로 치환하는 경우가 많다.
→ fillna() 함수를 통해 채워놓을 수 있다.

'age'와 'measurement'에서 null인 부분을 '-9999'로 채워넣기
# 결측치를 열 평균값으로 치환하기

열의 평균값으로 채워넣는다면?
4. 결측치 처리 (sklearn 패키지 사용)
1) imputer를 활용하여 결측값 처리
지금까지 일반적인 방법으로 결측값을 처리했다면, 이제부터 sklearn 패키지 - imputer를 활용한 방법을 학습해보자 (함수를 생성해서 사용하면 더 편리하게 사용 가능)
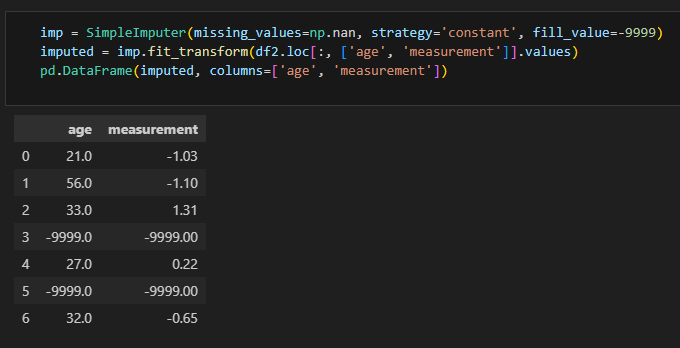
- SimpleImputer(missing_values=np.nan, strategy='constant', fill_value=9999)
: missing_value를 정의하고, 채워줄 값(fill_value)를 지정해주면 된다
- imp.fit_transform(df2.loc[:, ['age', 'measurement']].values)
: fit_transform을 통해서 value를 넣어주면 imputer 생성 완료
# 결측치 평균값으로 채우기 (imputer)
Imputer를 설정할 때, strategy를 'mean'으로 바꿔주면 평균값으로 치환된다!

5. 문자열에 대한 결측치 처리
이번엔 숫자가 아닌 문자열에 대한 결측치를 처리하는 것을 실습해보자
→ fillna() 함수를 통해 치환하기

1) mode(최빈값)을 활용하여 치환하기
결측값을 최빈값(=제일 많이 나온 값)으로 치환하는 경우

- fillna(df2.mode().iloc[0])
: mode() 함수를 통해서 가장 많이 나온 값으로 치환
2) sklearn을 활용하여 문자열 결측치 처리
imputer를 활용해서도 문자열 결측치를 처리할 수 있다.
→ 간단히 함수로만 생성하면 가독성도 좋다

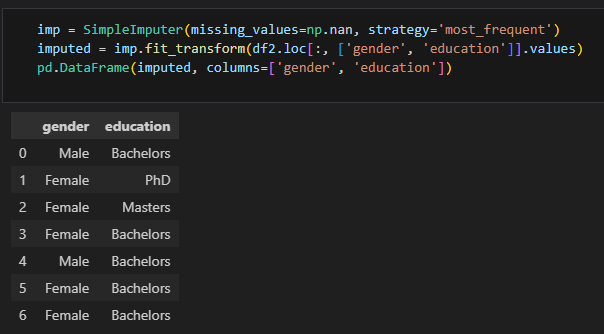
# imputer를 활용한 최빈값으로 치환
imputer 인자 중에서 strategy를 'most_frequent'로 설정하면 최빈값으로 치환된다.
6. 문자열 데이터를 날짜 데이터로 처리
문자열 데이터는 보통은 String 타입으로 들어오는 경우가 많다. 하지만, 아래와 같이 날짜 데이터는 그에 맞는 데이터타입을 가져야 한다. (dtype('O') : object 타입)
→ 문자열로 입력되었지만, 그 문자열을 가공해서 train할 때 유용한 변수로 활용할 수 있다!
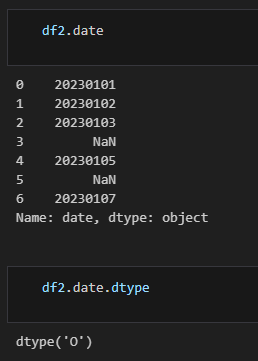
1) 날짜 데이터로 변환
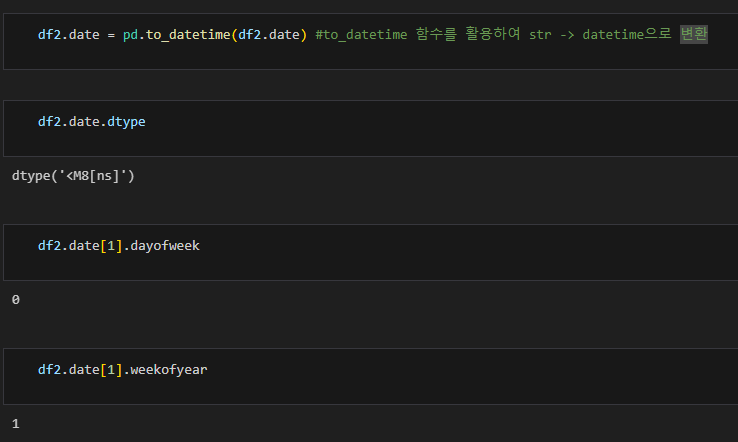
위와 같이 'to_datetime' 함수를 활용하여 타입을 변환할 수 있다.
날짜 데이터로 변환하면 그에 맞는 함수를 통해 정보를 취득하기 용이하다
→ dayofyear (무슨 요일인지), weekofyear(몇번째 주인지) 등의 다양한 변수를 뽑을 수 있다.
2) 날짜 함수를 통해 변수 뽑아내기

- pd.date_range(start=df2.date.min(), end=df2.date.max(), freq='D')
: df2 에서 날짜가 가장 빠른 날부터 마지막날까지 하루(freq='D')씩 증가된 데이터들이 채워지게 된다.
- df2['date'].apply(lambda x: x.dayofweek)
: dayofweek을 통해서 해당 날짜가 무슨 요일인지도 추출할 수 있다.
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE
'Machine Learning > Basic of Python (Colab)' 카테고리의 다른 글
| (파이썬) 쉽게 이해하고 써먹는 matplotlib로 시각화하기 (0) | 2024.04.02 |
|---|---|
| (파이썬) DataHandling 기초 & 실습(2) - 데이터 슬라이싱, 필터링 (0) | 2024.04.01 |
| 쉽게 이해하는 파이썬 numpy, pandas 정리 & 예제! (0) | 2024.03.24 |
| (파이썬 기초) if, for, while, try, except 쉽게 비교 정리 (0) | 2024.03.13 |
| 데이터 분석할 때 꼭 알아야 하는 Python 기본 함수 총정리! (0) | 2024.03.11 |




댓글