(파이썬) DataHandling 기초 & 실습(2) - 데이터 슬라이싱, 필터링
데이터 다루는 실습(1)에 이어서
데이터를 불러와서 슬라이싱과 필터링을 통해
실제로 어떻게 활용될 수 있는지 학습해보자

# Data handling 기초 & 실습(1) 첨부
2024.03.29 - [Machine Learning/Basic of Python (Colab)] - (sklearn) DataHandling 기초 & 실습 - 결측치 처리
(sklearn) DataHandling 기초 & 실습 - 결측치 처리
# 결측치 처리 - 일반적인 처리 방법 - sklearn을 이용한 처리 방법 - pandas를 이용한 처리 방법 파이썬 기본 함수와 특성을 이용해서 데이터를 다루는 실습을 해보자 1. Import & DataFrame 생성 결측치를
derrick.tistory.com
# 실습 파일 첨부 #
1. 데이터 불러오기
1) Google Drive Mount 하기 (Colab)
구글 드라이브에 있는 데이터를 마운트할 곳을 정하는 코드
from google.colab import drive
import pandas as pd
drive.mount('/content/test')
# 데이터 불러오기
위와 같이 Mount된 파일들은 Local 환경과 동일하게 사용이 가능하다.
sales_df = pd.read_csv('test/MyDrive/data/data_handling/sales_data.csv')
social1_df = pd.read_csv('test/MyDrive/data/data_handling/social1.csv')
social2_df = pd.read_csv('test/MyDrive/data/data_handling/social2.csv')
social3_df = pd.read_csv('test/MyDrive/data/data_handling/social3.csv')
2) Local 환경에서 불러오기 (Jupyter)
Local 환경에서도 불러오는 연습을 해보고 실제로 잘 읽어왔는지 확인해보자
import pandas as pd
# 데이터 불러오기
sales_df = pd.read_csv('C:/Users/Desktop/test/50개 프로젝트로 머신러닝_패캠/수강생 강의자료_1/Part 1. 실무 중심의 데이터 분석 방법/Chapter 03. Basic of Python/Data/sales_data.csv')
social1_df = pd.read_csv('C:/Users/Desktop/test/50개 프로젝트로 머신러닝_패캠/수강생 강의자료_1/Part 1. 실무 중심의 데이터 분석 방법/Chapter 03. Basic of Python/Data/social1.csv')
social2_df = pd.read_csv('C:/Users/Desktop/test/50개 프로젝트로 머신러닝_패캠/수강생 강의자료_1/Part 1. 실무 중심의 데이터 분석 방법/Chapter 03. Basic of Python/Data/social2.csv')
social3_df = pd.read_csv('C:/Users/Desktop/test/50개 프로젝트로 머신러닝_패캠/수강생 강의자료_1/Part 1. 실무 중심의 데이터 분석 방법/Chapter 03. Basic of Python/Data/social3.csv')


# 데이터별 설명
- sales_df : 주단위로 판매되는 물건의 갯수
- social1~3_df : 판매량과 연관이 있는 데이터들
2. 데이터 다루기
1) 데이터 컬럼명 변경하기
데이터의 컬럼명이 한글로 되어있는 경우가 많기 때문에 이를 영문으로 변경
sales_df.columns = ['date', 'sum']
sales_df.head(10)
# 소셜미디어(sns)에서 언급된 비율(ratio)
social1_df.columns = ['date', 'ratio1']
social1_df.head(10)

# 해당 아이템들이 검색 채널별로 얼마나 검색되었는지
social2_df.columns = ['date', 'key1', 'key2', 'key3', 'key4']
social2_df
# social1_df 와는 다른 채널에서 언급된 비율
social3_df.columns = ['date', 'ratio2']
social3_df
2) 데이터들 합치기
Inner Merge(Join)을 통해 데이터 합쳐보자
→ 동일하게 있는 데이터(date)에 대해서 합치는 원리
→ 이 경우, 모든 데이터들이 동일하게 가지고 있는 데이터들만 남게 됨.
즉, inner merge를 할 경우 merge 시키는 데이터들이 공통으로 가지고 있는 데이터들만 합쳐서 남겨된다.
(on = 'date')
# Inner Merge(Join)을 통해 데이터 합치기
result_df = sales_df.merge(social1_df, on='date', how='inner')
result_df = result_df.merge(social2_df, on='date', how='inner')
result_df = result_df.merge(social3_df, on='date', how='inner')
result_df
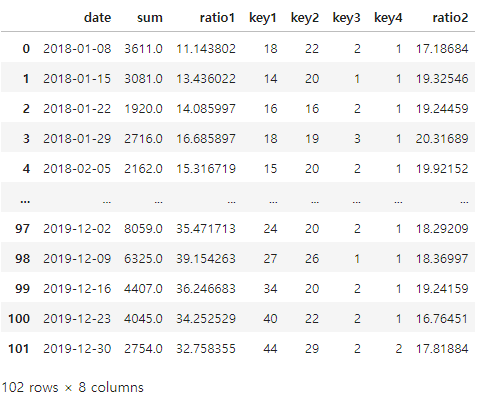
위의 작업을 1줄로 처리할 수도 있지만, 가독성을 위해서는 따로따로 하는게 좋을 수 있다.
→ 아래 코드는 한 줄로 작업하는 방법. merge 함수를 계속 붙이면서 늘릴 수 있다.
test_df = sales_df.merge(social1_df, on='date', how='inner').merge(social2_df, on='date', how='inner').merge(social3_df, on='date', how='inner')
test_df3) iloc를 이용하여 원하는 데이터만 불러오기
feature selection 등의 feature에 대해서 어떠한 작업을 할 때, column들 중 선택적으로 수행하는 경우가 많다.
→ 아래 데이터에서는 날짜를 제외한 모든 feature, 그리고 모든 행에 대해서
# 2번째 컬럼부터 마지막 컬럼까지의 데이터만 불러오기
test_df.iloc[:,1:]
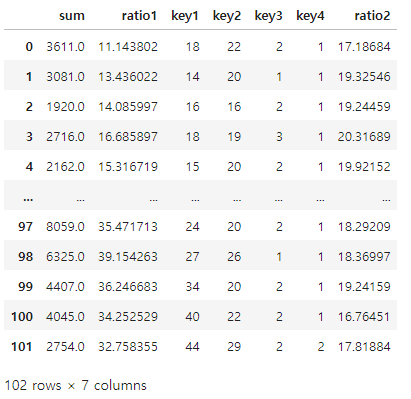
# 2번째 컬럼부터 마지막 이전까지의 컬럼
test_df.iloc[:,1:-1]

# 슬라이싱 응용 - target 데이터만 추출하기 (열 분리)
모든 행과 2번째와 마지막 열에 해당하는 데이터만 불러오고자 한다면?
→ target인 데이터가 포함된 경우, 학습할 때 제외하는 용도로 활용할 수 있다.
test_df.iloc[:, [2,-1]]
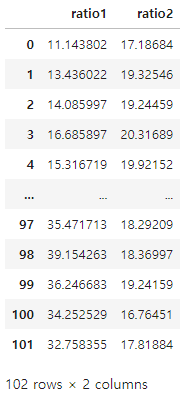
위와 같이 불러올 데이터의 열을 지정할 수 있다.
# Training과 Test 데이터를 나누기 (행 분리)
Training과 Test 데이터셋을 나눌때는 슬라이싱으로 행을 구분해서 불러오면 간단히 할 수 있다.
→ 아래는 traing dataset을 전체 데이터의 60%를 분배하고, 그 외는 test dataset으로 했을 때의 코드
test_df.iloc[0:int(len(test_df) * 0.6), :]
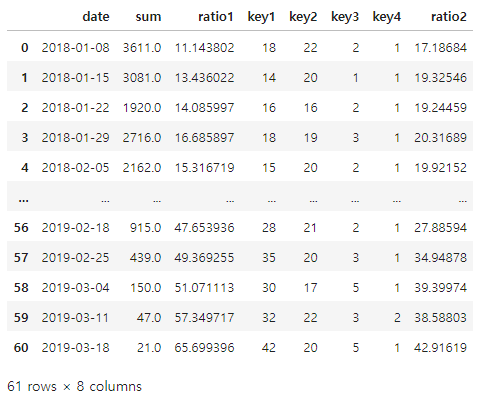
test_df.iloc[int(len(test_df) * 0.6):, :]
3. 데이터 필터링하기 (loc 활용)
loc를 이용하여 특정 컬럼의 조건으로 걸어서 데이터 필터링해서 추출
test_df.loc[(test_df['ratio1'] > 40.0) & (test_df['ratio2'] > 30.0)]
ratio1이 40 초과, ratio2가 30을 초과한 데이터들만 추출
→ & 연산자를 이용해야 한다.
→ 'and'를 사용하면, 에러가 나온다. return되는 값이 다르다.
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE (패스트캠퍼스)
'Machine Learning > Basic of Python (Colab)' 카테고리의 다른 글
| (파이썬) 쉽게 이해하고 써먹는 matplotlib로 시각화하기 (0) | 2024.04.02 |
|---|---|
| (sklearn) DataHandling 기초 & 실습 - 결측치 처리 (1) | 2024.03.29 |
| 쉽게 이해하는 파이썬 numpy, pandas 정리 & 예제! (0) | 2024.03.24 |
| (파이썬 기초) if, for, while, try, except 쉽게 비교 정리 (0) | 2024.03.13 |
| 데이터 분석할 때 꼭 알아야 하는 Python 기본 함수 총정리! (0) | 2024.03.11 |




댓글