(파이썬) 쉽게 이해하고 써먹는 matplotlib로 시각화하기
728x90
반응형
Github에서 데이터를 불러와서 다양한 상황에 대해 matplotlib를 어떻게 활용할 수 있는지 학습해보자
# 다룰 데이터 리스트
1) 인구에 대한 정보를 시각화
→ 인구밀집도 분석(scatter, encircle)
2) 자동차 연비, 실린더 갯수, 배기량 등의 상관관계
→ 배기량에 따른 고속도로 연비 변화량 (histogram)
→ 각 자동차 feature 간 상관관계 분석 (heatmap)
→ 자동차 모델별 차량 주행거리 분석
→ 실린더 갯수에 따른 도심 연비 시각화
→ 차급에 따른 도심 연비 비교
→ 자동차의 종류별 비율
→ 자동차 회사별 시장 점유율
파이썬에서 데이터 분석을 할 때
중요한 시각화 과정!
matplotlib를 활용하여 직접 실습해보자

1. 인구 데이터 시각화 & 분석
1) Import & 차트 사이즈 지정
Github에 있는 코드나 데이터를 받아서 바로 이용
시각화 Tool 중에서 matplotlib은 데이터 표현에 집중했다면, seaborn은 표현 방법에 집중된 패키지라고 볼 수 있다. seaborn이 조금 더 화려(?!)한 interface를 제공하고 있다.
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings; warnings.filterwarnings(action='once')
large = 22
med = 16
small = 12
params = {
'axes.titlesize' : large,
'legend.fontsize' : med,
'figure.figsize' : (16, 10),
'axes.labelsize' : med,
'axes.titlesize' : med,
'xtick.labelsize' : med,
'ytick.labelsize' : med,
'figure.titlesize' : large
}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
%matplotlib inline시각화시킬 차트의 사이즈를 default로 설정하고 가야 조금 더 정확하고 원하는 그래프를 그리기 쉽다.
→ 위에서 설정하면 아래도 동일하게 적용될 수 있어서 사전에 세팅해두면 좋다!
→ 굳이 변수로 지정하지 않는다면, 매번 그릴때마다 수동으로 설정해도 된다.
- plt.rcParams.update(params)
: 'rcParams' 이라고 하는 변수를 사이즈를 재설정한 'params'으로 업데이트
- %matplotlib inline
: 이러한 매직키워드를 사용해야 작동한 큰 착오와 문제없이 matplotlib을 사용할 수 있다.
2) Github에서 데이터 가져오기
Github에서 데이터를 불러와서 보면, 인구(pop) 밀집도, 흑인/백인 분포 등을 확인할 수 있다.
midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")
print(midwest.head(10))

3) Scatter 그래프 시각화 & 차트 분석
Area(=사이즈)마다 몇명의 사람들이 사는지 카테고리별로 Scatter 그래프로 시각화해보자
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
plt.figure(figsize=(16, 10), dpi=80, facecolor='w', edgecolor='k')
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal',
data=midwest.loc[midwest.category==category, :],
s=20, c=[colors[i]], label=str(category))
plt.gca().set(xlim=(0.0,0.1), ylim=(0, 90000), xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.title("Test", fontsize=22)
plt.legend(fontsize=12)
plt.show()
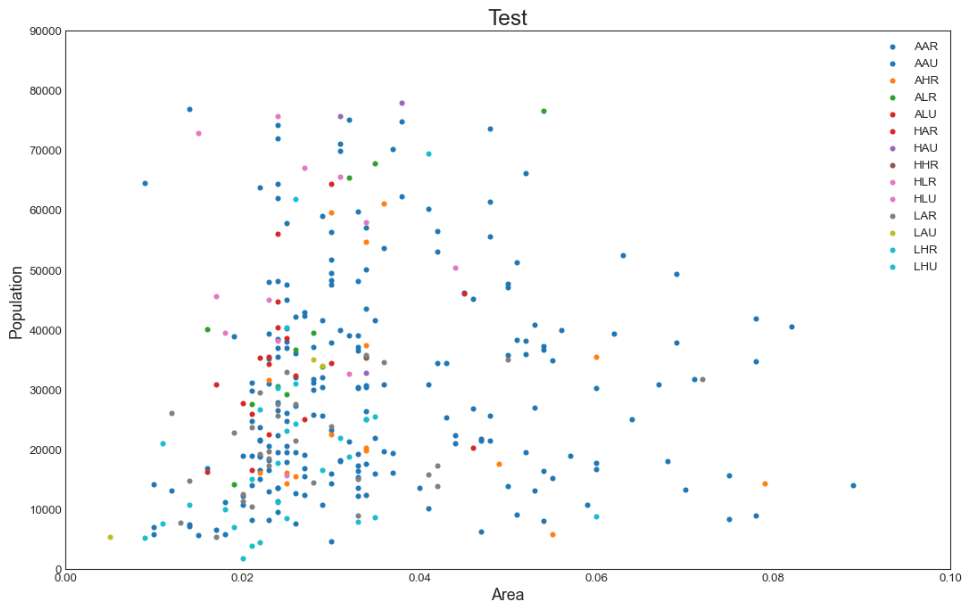
- enumerate
: enumerate() 함수는 인자로 넘어온 목록을 기준으로 인덱스와 원소를 차례대로 접근할 수 있는 반복자(iterator) 객체를 반환해주는 역할을 한다.
→ 위에서는 category를 돌면서 서로 다른 색깔로 출력되도록 활용
4) scatter 위에 다른 분포 그리기 (encircle)
위에서 Area 사이즈별로 그래프를 그려봤다면, 그 위에 'India(=IN)'에 사는 사람들의 분포를 확인해보자
→ encircle() 함수를 선언해서 그리기
→ alpha : 그래프의 투명도 조절
from matplotlib import patches
from scipy.spatial import ConvexHull
import warnings; warnings.simplefilter('ignore')
sns.set_style("white")
midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")
categories = np.unique(midwest['category'])
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
fig = plt.figure(figsize=(16, 10), dpi=80, facecolor='w', edgecolor='k')
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal', data=midwest.loc[midwest.category==category, :], s = 'dot_size', c=[colors[i]],
label=str(category), edgecolors='black', linewidths=.5)
def encircle(x, y, ax=None, **kw):
if not ax: ax=plt.gca()
p = np.c_[x,y]
hull = ConvexHull(p)
poly = plt.Polygon(p[hull.vertices, :], **kw)
ax.add_patch(poly)
midwest_encircle_data = midwest.loc[midwest.state=='IN', :]
encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="k", fc="gold", alpha=0.1)
encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="firebrick", fc="none", linewidth=1.5)
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Test2", fontsize=22)
plt.legend(fontsize=12)
plt.show()
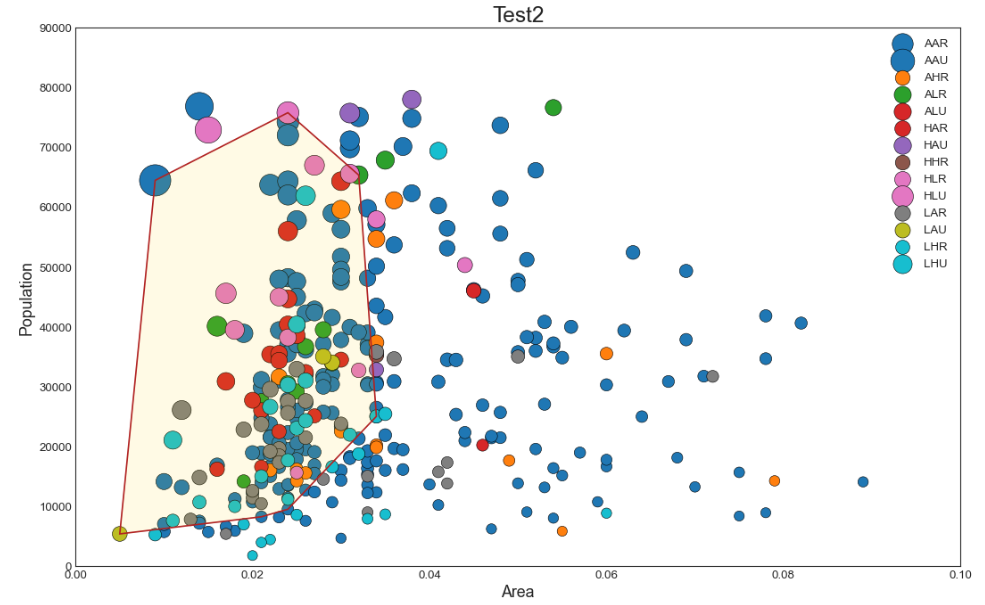
반응형
2. 자동차 데이터 분석 & 시각화
자동차의 배기량, 연비, 구동 방식 등의 정보를 활용하여 각 Feature별 상관관계와 차트를 통해 분석을 해보자.
# 데이터의 변수 설명
- displ : 배기량
- yeal : 제조년도
- cyl : 실린더 수
- trans : 변속기
- drv : 구동 방식 (f= 전륜구동, r= 후륜구동, 4 = 사륜구동)
- city : 도시 연비
- hwy : 고속도로 연비
- fl : 연료 종류
- class : 자동차 종류
1) 배기량에 따른 고속도로 연비 변화량
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_select = df.loc[df.cyl.isin([4,8]), :]
sns.set_style("white")
gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select,
height=7, aspect=1.6, robust=True, palette='tab10',
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
plt.title("Test3", fontsize=20)
plt.show()

위의 그래프는 배기량(displ)에 따른 고속도로 연비(hwy)에 변화를 나타낸 것이다.
→ 실린더 갯수(=cyl)에 따라 그래프 색깔을 분리(hue 지정)
→ 실린더가 4개인 차량은 실린더의 갯수가 증가할수록 고속도로 연비는 점점 줄어들지만, 실린더가 8개인 차량은 실린더의 갯수가 증가할수록 고속도로 연비가 조금씩 증가하는 것을 확인할 수 있다.
# 배기량에 따른 연비 변화량에 대한 분포(histogram) 시각화
바로 위에서는 '배기량에 다른 연비 변화량'에 대해 시각화를 했다면, 이번에는 그 데이터에 대해 x축과 y축 기준으로 분포를 히스토그램으로 확인해보자.
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
fig = plt.figure(figsize=(16, 10), dpi = 80)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)
ax_main = fig.add_subplot(grid[:-1, :-1])
ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])
ax_main.scatter('displ', 'hwy', s=df.cty*4, c=df.manufacturer.astype('category').cat.codes, alpha=.9,
data=df, cmap="tab10", edgecolors='gray', linewidths=.5)
ax_bottom.hist(df.displ, 40, histtype='stepfilled', orientation='vertical', color='deeppink')
ax_bottom.invert_yaxis()
ax_right.hist(df.hwy, 40, histtype='stepfilled', orientation='horizontal', color='deeppink')
ax_main.set(title='Test4', xlabel='displ', ylabel='hwy')
ax_main.title.set_fontsize(20)
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()):
item.set_fontsize(14)
xlabels = ax_main.get_xticks().tolist()
ax_main.set_xticklabels(xlabels)
plt.show()

위의 그래프를 통해 배기량에 따른 연비의 분포가 어디에 많이 몰려있는지 한 눈에 확인할 수 있다.
2) 각 Feature별 상관관계 분석 (heatmap)
heatmap은 대표적인 데이터 분석 Tool로, 자기 자신을 빼고 값이 마이너스(-)일 경우에는 두 관계가 음의 관계이고 플러스(+)인 경우는 양의 관계를 가진다는 의미이다.
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
plt.figure(figsize=(12, 10), dpi = 80)
sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True)
plt.title('Test5', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
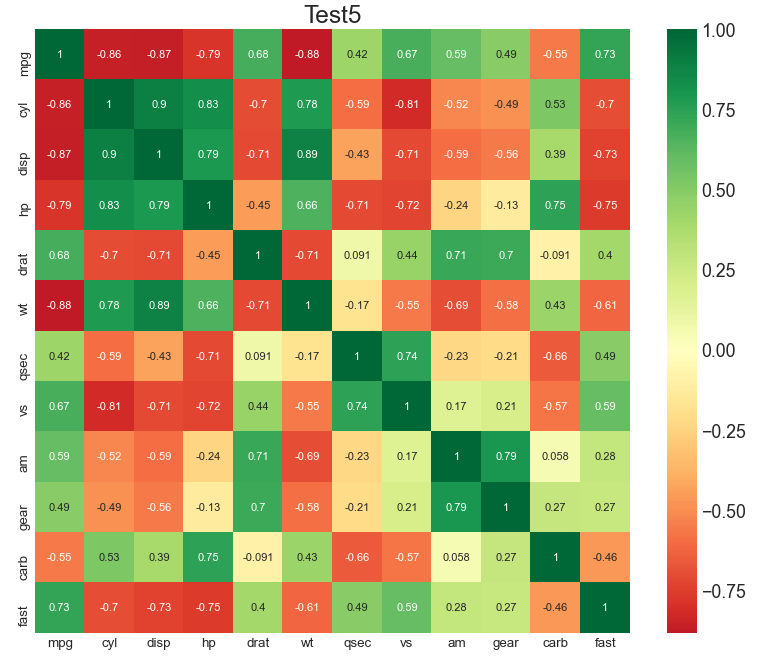
우리가 예측하고자 하는 Target에 따라서 위의 Feature(변수)들 중에서 사용할 것과 사용할 수 없는 것이 나누어진다. 그래서 heatmap을 출력해서 해석하는 법을 숙지해야 한다.
3) 자동차 모델별 차량의 주행거리 분석
자동차의 모델에 따른 차량 주행거리를 시각화해보자
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
plt.figure(figsize=(14, 10), dpi = 80)
plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z, color=df.colors, alpha=0.4, linewidth=5)
plt.gca().set(ylabel='$Model$', xlabel='$Mileage$')
plt.yticks(df.index, df.cars, fontsize=12)
plt.title('Test6', fontdict = {'size':20})
plt.grid(linestyle='--', alpha=0.5)
plt.show()
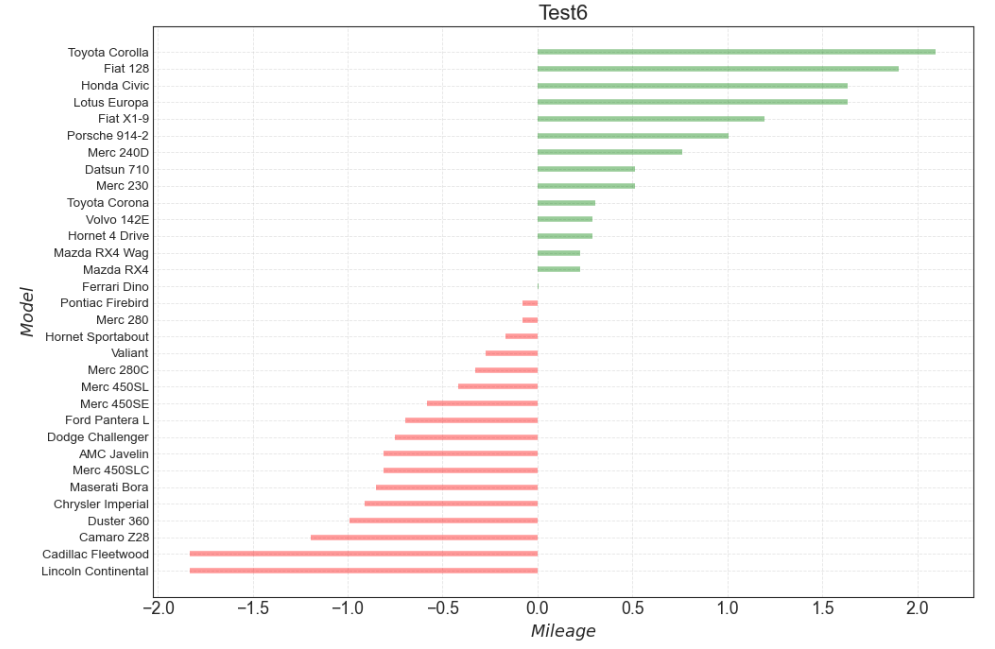
4) 차량 실린더 갯수에 따른 도심 연비 시각화
실린더 갯수(Cyl)에 따른 도심 연비(cty)에 분석
→ 실린더 갯수(Cyl)는 서로 다른 색상으로 구분해보자 (hue)
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
plt.figure(figsize=(16, 10), dpi=80)
sns.kdeplot(df.loc[df['cyl'] == 4, "cty"], shade=True, color="g", label="Cyl=4", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 5, "cty"], shade=True, color="deeppink", label="Cyl=5", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 6, "cty"], shade=True, color="dodgerblue", label="Cyl=6", alpha=.7)
sns.kdeplot(df.loc[df['cyl'] == 8, "cty"], shade=True, color="orange", label="Cyl=8", alpha=.7)
plt.title('Test7', fontsize=22)
plt.legend()
plt.show()

위의 그래프를 보면, 실린더가 4개인 차량들이 5개인 차량보다 도심연비가 월등히 좋은 것을 확인할 수 있다.
5) 차급에 따른 도심 연비 비교 분석
자동차 차급에 따라 도심 연비를 비교할 수 있도록 그래프로 시각화해보자
→ 차급은 Compact, SUV, minivan으로 설정!
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
plt.figure(figsize=(13, 10), dpi=80)
sns.distplot(df.loc[df['class'] == 'compact', "cty"], color="dodgerblue", label="Compact", hist_kws={'alpha': .7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'suv', "cty"], color="orange", label="SUV", hist_kws={'alpha': .7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'minivan', "cty"], color="g", label="minivan", hist_kws={'alpha': .7}, kde_kws={'linewidth':3})
plt.ylim(0, 0.35)
plt.title('Test8', fontsize=22)
plt.legend()
plt.show()
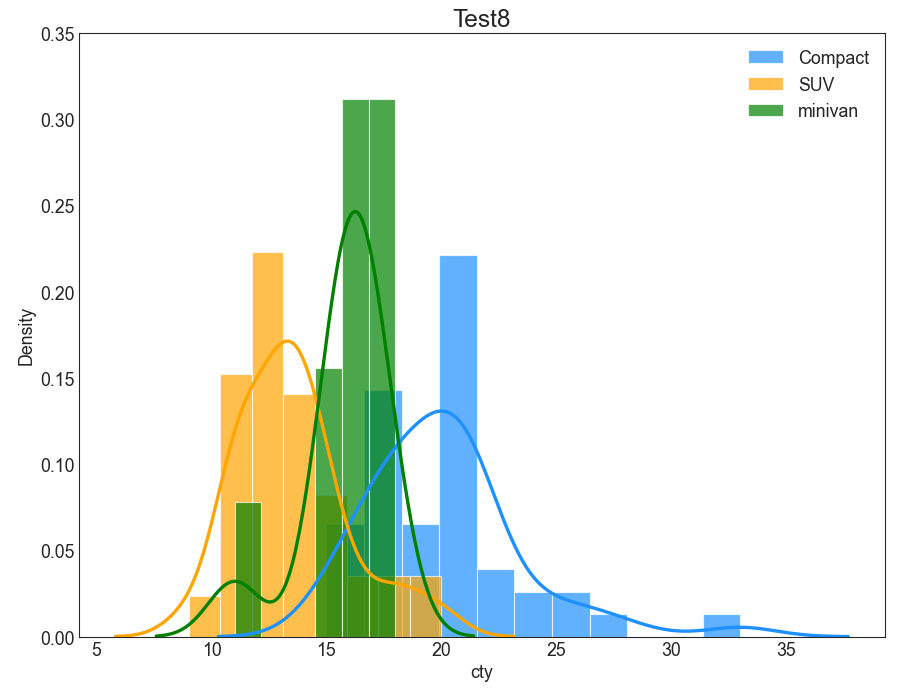
이렇게 Bar 차트뿐 아니라 선형(line) 그래프도 함께 그려주면, x축(cty)의 변화에 따른 양상/변화를 쉽게 파악하기 쉽다.
→ Bar 차트에 Line 그래프를 Overlap
6) 자동차의 종류별 비율 시각화 (pie chart)
자동차의 종류별 댓수의 비율을 pie 차트를 통해 시각화 해보자
→ 2-seater, compact, midsize, minivan, pickup, subcompact, suv
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw.groupby('class').size().reset_index(name='counts')
fig, ax = plt.subplots(figsize=(12, 7), subplot_kw=dict(aspect="equal"), dpi=80)
data = df['counts']
categories = df['class']
explode = [0, 0, 0, 0, 0, 0.1, 0]
def func(pct, allvals):
absolute = int(pct/100.*np.sum(allvals))
return "{:.1f}% ({:d} )".format(pct, absolute)
wedges, texts, autotexts = ax.pie(data,
autopct = lambda pct: func(pct, data),
textprops=dict(color="w"),
colors=plt.cm.Dark2.colors,
startangle=140,
explode=explode)
ax.legend(wedges, categories, title="Vehicle Class", loc="center left", bbox_to_anchor=(1, 0, 0.5, 1))
plt.setp(autotexts, size=10, weight=700)
ax.set_title("Test9")
plt.show()
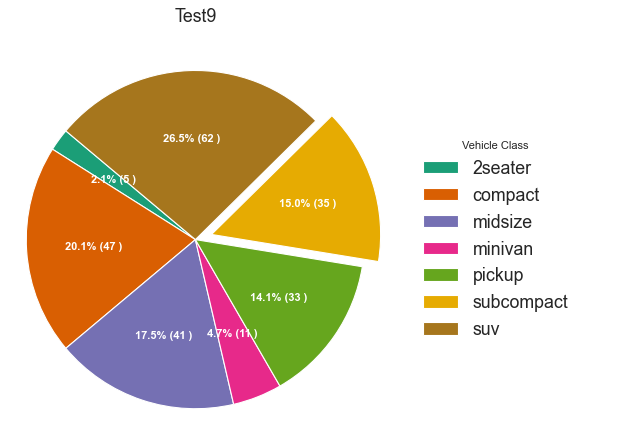
미국의 차량 데이터인 점을 고려했을 때와 위의 차트를 보더라도 'suv' 차종이 제일 비중이 크다는 것을 알 수 있다.
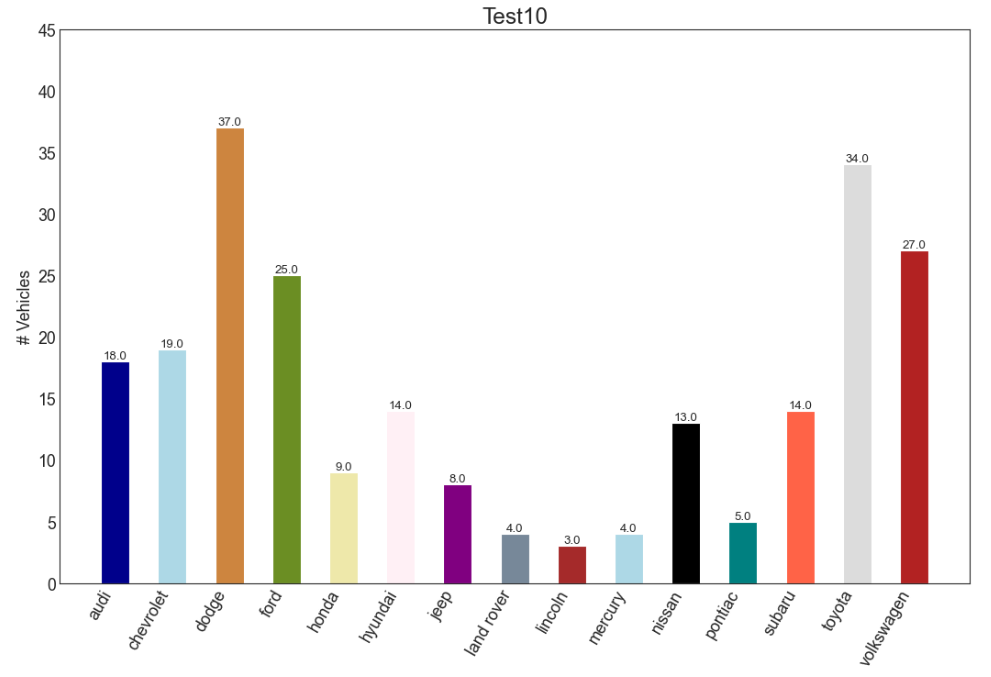
7) 자동차 회사별 시장 점유율 시각화
주어진 데이터 내 자동차 회사의 비율을 시각화해보자
→ 만약 해당 데이터가 미국 내 전체 자동차 회사에 대한 데이터라면, 결과는 '시장 점유율'이 될 수 있다.
import random
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
df = df_raw.groupby('manufacturer').size().reset_index(name='counts')
n = df['manufacturer'].unique().__len__()+1
all_colors = list(plt.cm.colors.cnames.keys())
random.seed(100)
c = random.choices(all_colors, k=n)
plt.figure(figsize=(16, 10), dpi=80)
plt.bar(df['manufacturer'], df['counts'], color=c, width=.5)
for i, val in enumerate(df['counts'].values):
plt.text(i, val, float(val), horizontalalignment='center', verticalalignment='bottom', fontdict={'fontweight':500, 'size':12})
plt.gca().set_xticklabels(df['manufacturer'], rotation=60, horizontalalignment='right')
plt.title("Test10", fontsize=22)
plt.ylabel('# Vehicles')
plt.ylim(0, 45)
plt.show()
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNAUTRE
'Machine Learning > Basic of Python (Colab)' 카테고리의 다른 글
| (파이썬) DataHandling 기초 & 실습(2) - 데이터 슬라이싱, 필터링 (0) | 2024.04.01 |
|---|---|
| (sklearn) DataHandling 기초 & 실습 - 결측치 처리 (1) | 2024.03.29 |
| 쉽게 이해하는 파이썬 numpy, pandas 정리 & 예제! (0) | 2024.03.24 |
| (파이썬 기초) if, for, while, try, except 쉽게 비교 정리 (0) | 2024.03.13 |
| 데이터 분석할 때 꼭 알아야 하는 Python 기본 함수 총정리! (0) | 2024.03.11 |




댓글