CSV, JSON 데이터 처리 - lambda, assert, map, filter 등
728x90
반응형
파이썬 데이터 분석을 하는 많은 경우에 주어지는 데이터들은 대부분 CSV, JSON 형태가 많습니다. 간단한 텍스트가 아닌 복잡한 형태로 된 데이터들을 어떻게 효율적으로 처리하고 분석하는지 기초부터 실습을 통해 학습합니다. 파이썬 데이터를 다룰 때 꼭 알아야 하는 함수나 문법은 아니지만, 알고 있다면 매우 유용하게 사용할 수 있는 것들을 배워보자.
이번 게시물을 통해 학습한 내용을 바탕으로, 다음 게시물에서는 테드(Ted) 강연에서 지금껏 가장 인기 있는 동영상과 Hot한 주제는 무엇인지 분석하는 미션을 수행해봅시다.
CSV, JSON 형태의 데이터들을 다룰 때
효율적으로 분석하고 처리할 수 있는 Tip들과 고급 함수들을 학습합니다.

1. CSV
'CSV'란, JSON과 비슷하게 자료의 형식 중 하나로 'Comma Separated Value'의 줄임말이다.
→ 각 열이 특정한 의미를 가지고, 존재하는 값들이 콤마( , )로 분리되어있다.
→ ex) 'name, age, address, gender' 정보가 있는 csv 자료가 있다면, 각 열마다 '이름, 나이, 주소, 성별' 순서로 독립적인 데이터를 가지게 된다. (쉼표로 구분)
→ CSV 파일은 본인이 데이터의 순서가 어떤 의미순으로 되어있는지 알아야 한다. 해석하기 어려움
1) CSV 자료 형식의 이해와 읽어오기
# csv 예시 - movies.csv
# 국문 제목, 영문 제목, 개봉 연도 (콤마(comma)로 구분)
다크나이트, The Dark Knight, 2008
겨울왕국, Frozen, 2013
슈렉, Shrek, 2001
슈퍼맨, Superman, 1978
# 다른 구분 문자(delimiter)로도 사용 가능
다크나이트|The Dark Knight|2008
겨울왕국|Frozen|2013
슈렉|Shrek|2001
슈퍼맨|Superman|1978
# csv 파일의 장점
1) 엑셀 파일에서는 csv 형태의 파일을 그대로 불러와서 열 수 있다.
→ 모든 행은 특정한 갯수의 데이터로 이루어져 있다
→ 각 열에는 독립적인 데이터를 가지고 있다.
2) 용량이 작다.
→ 데이터의 Key와 Value 중에 Value들만 저장하기 때문에 용량이 작다
→ 동일한 데이터를 저장하는 데 용량을 적게 소모
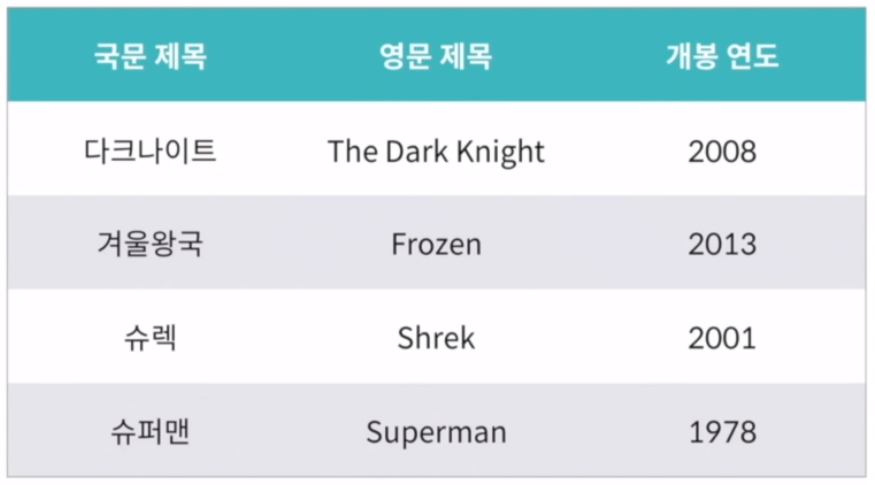
# 데이터에 '콤마( , )'가 포함된 경우
csv 파일은 콤마( , )를 기준으로 데이터를 분리하는데, 데이터 자체에 콤마가 포함된 경우라면 혼선이 있을 수 있기 때문에 위와 같이 큰 따옴표(" ")를 이용하여 각 데이터를 감싸야 한다.
→ 하지만, 데이터 분리하면서 콤마 하나라도 잘못 들어가면 전체 데이터가 오염될 수 있는 단점이 있다.
# 데이터에 콤마(,)가 포함된 경우
먹고 기도하고 사랑하라, "Eat, Pray, Love", 2010
"헬로우, 뉴욕", "Hello, New York", 2013
# CSV 파일 읽어오기
csv 파일을 읽어오기 위해서는 'csv' 라이브러리를 import 해야 한다.
→ reader() 를 통해 csv 파일의 내용을 먼저 줄 별로 나눠서 구분자를 인자로 넣어주면 된다.
ex) reader(읽어올 파일, delimiter = ? )
→ delimiter란, 구분자로 어떤 구호로 데이터를 구분되어 있는지 지정할 수 있다.
# csv 파일 불러오기
import csv
with open('movies.csv') as file:
reader = csv.reader(file, delimiter = ',')
for row in reader:
print(row[0])reader() 를 통해 데이터를 읽어오면, 각 열에 대한 데이터를 가져오게 된다.
→ 첫번째 열을 데이터를 출력하고자 한다면, row[0]
→ 리스트의 원소들을 불러오듯이 for 문을 순회하면서 데이터를 읽어올 수 있다.
# 실습1 - csv 데이터 읽고 처리하기
csv 데이터를 분석하기 위해 먼저 각 열의 데이터를 분리해야 한다. 책 정보가 담긴 주어진 csv 파일을 열고, 데이터를 ' , '를 기준으로 분리하여 "제목 (저자): 페이지 수p" 형식으로 출력하는 함수를 생성해보자.
ex) On the Origin of Species (Charles Darwin): 502p
- books.csv : '제목, 저자, 장르, 페이지 수, 출판사' 순서로 나열된 데이터

# csv 모듈 import
import csv
# 함수 생성
def print_book_info(filename):
with open(filename) as file:
# ',' 기호로 분리된 csv 데이터 분리
reader = csv.reader(file, delimiter = ',')
# 처리된 파일의 각 row 불러오기
for row in reader:
title = row[0]
author = row[1]
pages = row[3]
print("{} ({}): {}p".format(title, author, pages))
# 함수 실행
filename = 'books.csv'
print_book_info(filename)
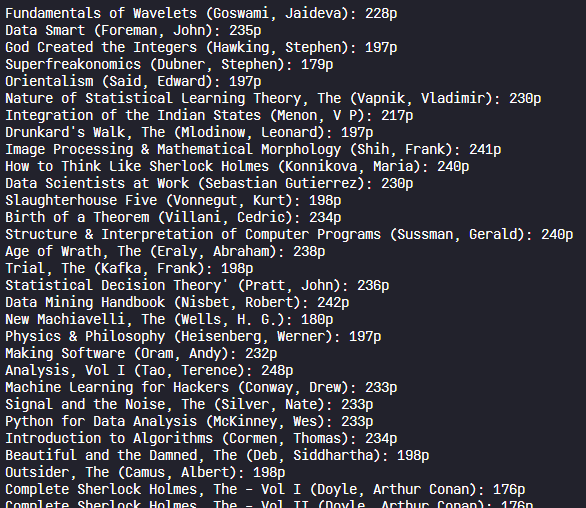
위의 books.csv 에 있는 데이터를 바탕으로 원하는 데이터들을 원하는 형식으로 잘 출력됨을 확인할 수 있다.
# 실습2 - csv 데이터 변환하기
csv는 파일의 크기가 작다는 장점이 있지만, 상황에 따라서 JSON 같은 다른 형식으로 변환하는 경우가 많다. 주어진 책 데이터(book.csv)를 JSON 형식으로 변환하여 저장하는 'books_to_json()' 함수를 생성해보자.
→ books.csv 파일을 입력 받고 books.json 파일에 저장하여 return 하는 함수
→ 페이지의 수는 문자열이 아닌 정수 값
- books.csv : '책의 제목, 작가의 이름, 장르, 페이지 수, 출판사' 순으로 데이터가 저장되어 있음(1열부터)
# CSV, JSON 모듈 import
import csv
import json
# 함수 생성 (csv파일을 입력 받고, json 파일로 return)
def books_to_json(src_file, dst_file):
books = []
with open(src_file) as src:
reader = csv.reader(src, delimiter= ',')
# 각 줄 별로 대응되는 book 딕셔너리를 만든다
for row in reader:
# 책 정보를 저장하는 딕셔너리를 생성
book = {
'title': row[0],
'author': row[1],
'genre': row[2],
'pages': int(row[3]), # 페이지 수는 정수형으로 변환처리
'publisher': row[4]
}
books.append(book)
with open(dst_file, 'w') as dst:
# dictionary 데이터를 JSON 형식으로 dst_file에 저장
book_json = json.dumps(books)
# dst_file에 입력
dst.write(book_json)
return book_json
# 함수 테스트
src_file = 'books.csv'
dst_file = 'books.json'
books_to_json(src_file, dst_file)

위의 실행 결과를 보면 books.json 안에 지정한 key값(title, author, genre 등)에 대해 해당하는 데이터들이 value로 잘 들어간 것을 확인할 수 있다.
반응형
2. lambda() - 코드를 한줄로 간단하게
lambda() 함수는 코드를 한줄로 간결하게 작성할 수 있는 유용한 함수이다. 어떤 값을 인자로 받아서 어떤 값을 return 할지 정의해주는 기능이 있다.
단, 함수가 이름을 갖지 않고 특정 범위에서만 적용되기 때문에 한 번만 사용되거나 아주 간단한 함수를 선언할 때 주로 사용된다.
1) lambda 함수 사용 예시
# Example 1
# 제곱시키는 함수
def square(x):
return x * x
# lambda 적용
square = lambda x: x * x- lambda (입력받을 인자) : (return할 값)
# Example 2
# 영화의 정보가 든 movies list가 주어지고
movies = [
"다크나이트, The Dark Knight, 2008",
"겨울왕국, Frozen, 2013",
"슈렉, Shrek, 2001",
"슈퍼맨, Superman, 1978"
}
# 위의 리스트 중 영어제목만 뽑아오고 싶다면?
# 1) 함수 사용
def get_eng_title(row):
split = row.split(',')
return split[1]
# 영문제목 순서대로 데이터들을 정렬
sorted(movies, key=get_eng_title)
# 2-1) lambda() 사용
get_eng_title = lambda row: row.split(',')[1]
sorted(movies, key=get_eng_title)
# 2-2) lambda() 사용(간결하게)
sorted(movies, key=lambda row: row.split(',')[1])만약 내가 영어제목만 뽑아오는 작업을 꽤 많이 반복을 할거라면 위에 'get_eng_title()'와 같이 함수를 생성해서 사용할 수 있다. 하지만, 한두번만 사용할거라면(?) lambda 함수를 이용하는 것이 효율적이다.
→ " sorted(movies, key=lambda row: row.split(',')[1]) "
2) assert()
assert()는 True 혹은 False에 따른 조건부 실행이 가능한 함수이다.
assert 구문 안에는 T/F 값을 내보내고, True면 아무 실행 없이 pass하지만 False라면 실행 중단하고 Error을 발생시킨다. 그래서 테스트 용도로 많이 사용된다. 2개의 함수나 수식이 있을 때 결과값이 동일한지 True인지 확인하는 용도로 사용된다.
# Example
# 함수로 구현한 sqaure
def square1(x):
return x * x
# lambda로 구현한 square
square2 = lambda x: x * x
# 두 값이 같으면 통과, 아니면 에러
assert(square1(3) == square2(3))# 실습1 - 한 줄 함수 작성하기
아래의 2가지 조건에 대해 'def'로 선언된 함수를 동일한 기능을 가진 'lambda' 함수로 선언해보자. 함수로 정의한 것과 lambda로 선언한 함수식을 '_'로 구분하고, 마지막에 assert() 함수를 통해서 값이 동일한지 테스트해보자.
1) square (=제곱)
2) string 빈 문자열이면 빈 문자열, 아니면 첫 번째 글자 리턴
- 문자열이 Boolean의 자리, 즉 if나 while의 뒤에 들어갈 때 string이 빈 문자열이면 False, 아니면 True를 갖는다.
- "A if B else C" : B를 만족할 경우 A, 아니면 C의 값을 가진다.
# 1) square - 제곱한 값 리턴
# def로 선언
def _square(num):
return num * num
# lambda로 선언
square = lambda num: num * num
# 2) string이 빈 문자열이면 빈 문자열, 아니면 첫번째 글자 리턴
# def로 선언
def _first_letter(string):
return string[0] if string else ''
# lambda로 선언
fisrt_letter = lambda string: string[0] if string else ''
# assert()를 이용하여 두 함수의 기능 테스트
testcase1 = [3, 10, 4, 1, -5]
for num in testcase1:
assert(_square(num) == square(num))
testcase2 = ['', 'hello', 'gildong', 'abcdefg', 'hijklmn']
for string in testcase2:
assert(_first_letter(string) == first_letter(string))
# 위의 assert 테스트를 모두 통과하면 아래의 print 실행
print("일치합니다.") # 일치합니다.# 실습2 - 함수를 리턴하는 함수 ★★★
파이썬의 함수는 함수를 리턴값으로 가질 수도 있다. 대표적인 예로, 'itemgetter()' 함수가 있고 itemgetter의 return값은 데이터의 모음을 받아 n번째 원소를 리턴하는 함수이다.
이를 바탕으로 데이터가 특정 범위에 속하는 유효한 값인지 검증하는 함수를 'Validator' 함수라고 불리고, 아래 조건에 맞는 Validator 함수를 생성해보자
1) 주어진 값이 정수가 아니거나 최솟갓(minimum)보다 작으면 False를 return 하는 함수를 return
→ min_validator()
2) 주어진 값이 정수가 아니거나 최댓값(maximum)보다 크면 False를 return하는 함수를 return
→ max_validator()
# 함수를 return하는 itemgetter() 예시
from operator import itemgetter
get_zeroth = itemgetter(0)
numbers = [1, 2, 3]
print(get_zeroth(numbers)) # 1
# 함수 내 def를 사용해서 함수 return
def adder(n):
def helper(x):
return x + n
return helper
add_three = adder(3) # 'x + 3' 값을 return하는 함수 처리
print(add_three(6)) # 9
# 1) 주어진 값이 정수가 아니거나 minimum보다 작으면 False를 리턴하는 함수 리턴
def min_validator(minimum):
def helper(n):
# n은 실제로 넣어줄(입력할 데이터)
# n의 타입이 정수가 아니면 False
if type(n) is not int:
return False
# 최솟값 minimum 보다 크면 True, 작으면 False
return minimum <= n
return helper
# 2) 주어진 값이 정수가 아니거나 maximum보다 크면 False를 리턴하는 함수 리턴
def max_validator(maximum):
def helper(n):
# 정수가 아니면 False
if type(n) is not int:
return False
# 최댓값(maximum) 보다 작으면 True, 크면 False
return maximum >= n
return helper
# Validator 함수 생성
def validate(n, validators):
# validator(min or ma) 중 하나라도 pass 못하면 False 리턴
for validator in validators:
if not validator(n):
return False
return True
# 선언한 함수 테스트
# 나이 데이터를 검증하는 validator 선언 (나이는 최소 0살부터 최대 120살 설정)
age_validators = [min_validator(0), max_validator(120)]
ages = [9, -3, 7, 33, 18, 1999, 287, 0, 13]
print("검증 결과")
for age in ages:
result = "유효함" if validate(age, age_validators) else "유효하지 않음"
print("{}세 : {}".format(age, result))

- return minimum <= n
: 주어진 값(n)이 minimum값보다 크면 True, 작으면 False값을 return
# 아래 4줄의 코드와 동일한 의미를 갖는다
if mimimum <= n:
return True
else:
return False
3. map() - 각 원소에 동일한 함수 적용
map() 함수는 파이썬의 기본 함수로 어떤 리스트(List)와 같은 데이터집합이 주어졌을 때, 그 데이터의 원소들에 대해서 동일한 함수를 취해주는 함수이다. ex) 주어진 리스트에 속해 있는 모든 원소들을 각각 인자로 입력한 함수를 씌운 결과값으로 출력한다. 아래 실습을 통해서 쉽게 익혀보자!
→ map(적용시킬 함수, 함수를 반영할 리스트나 데이터집합)
1) map() 함수의 사용 예시 - List에서 원하는 정보만 추출
# 영화 데이터가 포함된 'movies'라는 리스트로부터 영화제목만 포함된 'eng_titles' 리스트를 새롭게 생성할려면?
# '영화제목, 영문제목, 개봉연도'로 이루어진 String List
movies = [
"다크나이트, The Dark Knight, 2008",
"겨울왕국, Frozen, 2013",
"슈렉, Shrek, 2001",
"슈퍼맨, Superman, 1978"
]
# 위의 movies 리스트에서 원하는 정보만 취하기
eng_titles = [
"The Dark Knight",
"Frozen",
"Shrek",
"Superman"
]
def get_eng_title(row):
split = row.split(',')
return split[1]
eng_titles = \
[get_eng_title(row) for row in movies]
# map() 함수 적용
eng_titles = map(get_eng_title, movies)1)
def get_eng_title(row):
split = row.split(',')
return split[1]
→ 'movies' 리스트에 원소 하나(ex, "다크나이트, The Dark Knight, 2008")을 인자를 'row'로 받고
→ ' , ' (쉼표, 콤마)를 기준으로 쪼개서 'split'에 저장
→ 그리고 저장한 index 1번째 컬럼인 영문제목만 return 시킴
2)
eng_titles = \
[get_eng_title(row) for row in movies]
→ list comprehension을 이용해서 새로운 리스트를 생성할 수 있다.
3)
# map() 함수적용
eng_titles = map(get_eng_title, movies)
→ 함수(get_eng_title)를 1번째 인자로 받고, 리스트(movies)를 2번째 인자로 받는다.
→ 입력받은 각 리스트에 함수를 동일하게 적용시킨다.
ex)
list = [x, y, z]
f() = ~~
map(f, list) = [f(x), f(y), f(z)]
→ 따라서 위의 경우, 'movies' list 안에 있는 모든 원소에 대해 get_eng_title() 함수가 모두 적용되어 결과값이 출력된다.
2) map() 함수의 응용 예시 - lambda
위에서 선언한 리스트에서 map() 함수에 lambda 함수를 넣어서 아래와 같이 동일한 결과값을 도출할 수도 있다.
eng_titles = map(
lambda row: row.split(',')[1],
movies
)
# 따라서 'movies' 리스트에서 영문제목만 추출한 리스트를 생성하는데 총 4가지 방법이다.
# 1) def로 함수를 선언 + List comprehension
[get_eng_title(row) for row in movies]
# 2) 1줄 코드 + List comprehension
[row.split(',')[1] for row in movies]
# 3) def 함수 선언 + map()
map(get_eng_title, movies)
# 4) lambda() + map()
map(lambda row: row.split(',')[1], movies)3) map의 type은?
map() 함수가 적용된 리스트를 출력하면 리스트가 아닌 다른 결과값이 도출된다. (map과 list는 다른 type)
→ map() 함수는 리스트를 바로 생성해주지 않는다.
→ 'map'이라는 type을 가지는 새로운 데이터구조를 생성한다.
eng_titles = map(get_eng_title, movies)
print(eng_titles) # <map object at 0x104154f98>'print(eng_titles[0])' 과 같이 사용자가 map() 함수가 적용된 리스트에서 필요한 정보를 추출하는 형식으로 사용
→ 리스트 내 데이터들이 굉장히 많을 경우, 코드 실행이 효율적이다.
→ 사용자가 사용하고자 하는 원소에 대해서만 코드 실행하게 됨. List보다 더 빠르다. 필요한 연산만 진행
# map() 함수로 적용된 결과를 모두 리스트로 확인해야한다면..?
→ 결과물을 List 형식으로 바꿔서 확인하면 된다!
→ 'list(eng_titles)' 로 바꿔서 출력하면 모든 원소들을 연산하게 된다.
4) map() vs List comprehension
map()은 데이터 구조의 각 원소들에 동일한 함수를 적용하여 새로운 데이터를 생성하는 파이썬의 기본함수이다.
예시로 'data'라는 리스트가 주어졌을 때, 아래의 두 코드는 유사한 연산을 한다.
[func(x) for x in data]
map(func, data)List comprehension과 map()의 가장 큰 차이점은 연산을 진행하는 시점이다. map()의 경우 데이터를 'map'이라는 클래스로 저장하고, 데이터가 필요해질 때 주어진 연산을 수행하게 된다.
# 실습 - 리스트에 함수 적용하기
'books.csv'라는 자료가 주어지고, 해당 자료에 포함된 데이터들 중 '제목의 리스트'만 return하는 'get_titles()' 함수를 생성해서 실행해보자
import csv
def get_titles(books_csv):
with open(books_csv) as books:
reader = csv.reader(books, delimiter=',')
# 영화제목 추출
get_title = lambda row: row[0]
# reader list 내 'get_title' 함수 적용 - map()
titles = map(get_title, reader)
# map을 list 형식으로 변환하여 return
return list(titles)
# 함수 테스트
books = 'books.csv'
titles = get_titles(books)
for title in titles:
print(title)

- return list(titles)
: map 타입을 list로 변환해서 return 시키기
→ 'with open ~' 구문으로 파일을 열면, 자동으로 파일을 닫아준다.
→ 하지만, map() 은 연산을 사용자가 필요할 때(출력할 때) 이루어지는데 그 시점에는 이미 파일은 닫힌 상태(with 구문 이후)이기 때문에 Error가 발생할 수 있다. (즉, 연산을 하려는 시점에 닫힌 파일로 접근할려고 하기 때문에 Error 발생)
→ 따라서 with 구문 안에서 List 형식으로 return 시켜줘야 한다.
- get_title = lambda row: row[0]
: 영화의 제목은 1열(=index 0번째)에 해당하므로 1줄씩 읽으면서 1열에 있는 데이터를 추출
- titles = map(get_title, reader)
: 'reader'라는 books.csv 파일에서 데이터를 불러온 리스트에 대해서 lambda 함수가 포함된 'get_title'를 적용
4. filter() - 특정 조건을 만족하는 원소만 추출
filter() 함수도 map()과 유사하게 어떤 리스트(데이터 집합)에 대해서 사용하는 함수이다.
→ filter(조건이 포함된 함수, 적용시킬 List)
1) filter() 함수의 예시 - List에 조건 설정
# 영단어가 포함된 'words'라는 리스트로부터 'r'로 시작하는 리스트를 새롭게 생성하려면?
아래와 같이 주어진 리스트와 얻고자 하는 리스트를 먼저 확인하고 filter()를 통해 어떻게 얻을 수 있는지 학습해보자!
# 영단어 리스트
words = ['real', 'man', 'rhythm', ...]
# 얻고자 하는 리스트 ('r'로 시작)
r_words = ['real', 'rhythm', 'right', ...]
# 함수 적용 (for in if문 사용)
r_words = [word for word in words if word.startswith('r')]
# filter 함수를 사용해서 더욱 간단하게 작성
def starts_with_r(word):
return word.startswith('r')
words = ['real', 'man', 'rhythm', ...]
r_words = filter(starts_with_r, words)- r_words = [word for word in words if word.startswith('r')]
: 'words' 리스트를 돌면서 'r'로 시작하는 단어만 추출하여 리스트 생성 (list comprehension)
- def starts_with_r(word): return word.startswith('r')
→ word가 'r'로 시작하면 True, 아니라면 False값 return
- r_words = filter(starts_with_r, words)
: filter(함수, 리스트) 형식으로 함수의 return값이 True라면 해당 원소들을 추출한다. (r_words에 저장)
2) filter() 함수의 응용 - lambda
map() 함수에서와 동일하게 filter()도 lambda 함수를 통해 코드를 더욱 간결하게 작성할 수 있다.
starts_with_r = lambda w: w.startswith('r')
words = ['real', 'man', 'rhythm', ...]
r_words = filter(starts_with_r, words)3) filter의 type은?
filter()도 map()과 동일하게 리스트 형식이 아닌 filter 타입을 가지고 연산을 나중으로 미룬다.
즉, 사용자가 출력하거나 원소를 추출/호출하는 시점에 연산이 이루어진다.
r_words = filter(starts_with_r, words)
print(r_words) # <filter object at 0x104154f98>
Q) 만약 어떤 원소들이 있는지 모두 보고 싶다면?
→ List로 변환해주면 된다!
→ print(list(r_words))
filter()도 연산을 필요할 때 이루어지기 때문에 사용자가 데이터를 사용하지 않는다면 연산을 진행하지 않는다.
4) filter() vs map() vs List comprehension
filter()는 주어진 데이터 구조에서 특정 조건을 만족(True)하는 원소만 골라내는 파이썬 기본 함수이다.
data라는 리스트가 주어졌을 때, 아래의 두 코드는 유사한 연산을 수행한다.
[x for x in data if func(x)]
filter(func, data)filter()도 map()과 동일하게 즉시 연산되지 않고, filter 타입의 데이터 구조를 생성한다. 유지가 출력/호출할 때 연산을 수행한다.
filter()의 경우, map()과 다르게 인자로 가지는 함수의 결과가 참(True) 혹은 거짓(False)에 따라 해당 요소가 포함 여부가 결정된다.
# 실습 - 리스트에 filter() 함수 적용하기
books.csv 파일을 읽어서 페이지 수가 '250'가 넘는 책들의 제목을 리스트로 return하는 'get_titles_of_long_books()' 함수를 완성해보자
# 함수 실행 순서
1) books.csv 파일 읽어오기
2) 250장이 넘는 데이터들만 추출하는 함수 선언 (is_long)
3) 영화제목만 추출하는 함수 선언 (get_title)
4) 전체 row들 중에서 250 page만 넘는 데이터들만 추출 (filter 함수)
5) filtering된 데이터들에 대한 영화제목만 추출
import csv
def get_titles_of_long_books(books_csv):
with open(books_csv) as books:
reader = csv.reader(books, delimiter=',')
# 250 page가 넘는 데이터만 추출하는 함수
is_long = lambda row: int(row[3]) > 250
# 영화제목만 추출하는 함수 (row[0] : 제목)
get_title = lambda row: row[0]
# 전체 row들 사이에서 250 page가 넘는 데이터 추출
long_books = filter(is_long, reader)
# filtering된 데이터들의 영화제목만 추출
long_book_titles = map(get_title, long_books)
return list(long_book_titles)
# 작성한 함수 테스트
books = 'books.csv'
titles = get_titiles_of_long_books(books)
for title in titles:
print(title)

- is_long = lambda row: int(row[3]) > 250
: 대소관계를 비교하기 위해 int 형식으로 변환해주기. 안하면 String 형식
'Data Analyst > Project & Practice' 카테고리의 다른 글
| TED 강연 데이터 분석하기! 가장 인기 있는 강의 유형은? (1) | 2024.01.21 |
|---|---|
| 넷플릭스 영화 추천 알고리즘 파이썬 코드로 구현하기! 시청데이터로 예상 선호도 산출! (2) | 2023.12.04 |
| JSON 형식을 dictionary로 변환할때 알아야 할 이론과 실습! (w/넷플릭스 시청데이터) (1) | 2023.12.04 |
| [파이썬 데이터분석] 가장 많이 사용하는 '영어 단어'는? 코드 구현! (2) | 2023.11.20 |
| 데이터 분석 - 파일/데이터의 구조/그래프 다루기 기초 정리! (1) | 2023.11.18 |




댓글