넷플릭스 영화 추천 알고리즘 파이썬 코드로 구현하기! 시청데이터로 예상 선호도 산출!
728x90
반응형
타이타닉, 쥬라기공원, 스타워즈를 본 나와 비슷한 유저는?
실제 넷플릭스 데이터 대회에 사용된 데이터의 일부를 JSON, 사전형(Dictionary)로 변환하고 재정렬해보며 비슷한 성향의 유저를 찾을 수 있다. 그리고 사람들에게 작품을 추천해주거나 A작품과 B작품이 얼마나 비슷한지 분석할 수 있는 코드를 한번 생성하는 실습을 진행해보자.
- 회원별로 시청한 작품 정리하기
- 두 작품의 유사도 비교하기
- 예상 선호도 점수 구하기
- 사용자(User)가 시청한 영화들을 기반으로 선호할만한 영화 Top 10 추천받기
이전 게시물(JSON을 Dictionary로 변환할때 ~)을 공부하면서 기본적인 이론과 코드 원리를 공부하고 실습하면 더 쉽게 할 수 있을 것 같다.
# 이전 게시물
JSON 형식을 dictionary로 변환할때 알아야 할 이론과 실습! (w/넷플릭스 시청데이터)
JSON 데이터 형식을 배우고 파이썬의 딕셔너리, 집합 등의 데이터 구조로 변환하여 주어진 데이터를 분석하는 법에 대해 학습합니다. 이후 실제로 넷플릭스 데이터 경진대회에서 사용되었던 JSON
derrick.tistory.com
# 크게 아래 2가지 목표에 대해 어떤 식으로 개발할지 구상하고 수행해보자
## 주어진 데이터
- movies.py : 'titles' 딕셔너리로 숫자 key값에 대한 실제 영화 제목이 value로 지정됨
→ key : index / value : 영화 제목
- netflix.json : JSON 형태로 각 영화를 시청한 사용자들이 담긴 리스트 형식으로 구성
→ key : 영화 id(코드) / value : 해당 영화를 시청한 users 리스트 형식
목표1) 두 작품 간 장르/성향의 유사도 산출
- 유사도 = (두 작품을 모두 본 사람의 수) / (두 작품 중 하나라도 본 사람의 수)
- 작품별 시청한 유저(title_to_user) 데이터로 return될 필요가 있음
→ len()을 통해서 유저의 수를 파악하고 유사도 산출 - get_closeness() 생성
- 주어진 데이터(netflix.json)은 JSON 형태로 dictionary로 변환 - preprocess_data() 생성
목표2) 특정 유저가 선호할만한 영화 Top 10 추천
- 유저별 시청한 작품(user_to_titles)의 딕셔너리인 새로운 데이터 형식으로 정제
→ reformat_data() 생성
- 해당 유저가 시청한 작품들을 추출하고, 이와 titles 내 다른 영화와의 유사도를 바탕으로 선호도 수치가 높은 순으로 영화 List-up
- 특정 작품에 대한 사용자의 예상 선호도 산출
→ user와 영화를 입력 받고, 해당 user가 시청한 영화와 입력 받은 영화와의 선호도 산출
→ predict_preference() 생성
넷플릭스 시청 데이터 분석해보기!
작품 간 유사도 / 선호도 / 회원별 시청한 작품 정리 등

1. 필요한 라이브러리 import
실습을 진행하기 위해 필요한 파이썬 라이브러리를 import 합니다.
import matplotlib.pyplot as plt
import json
from operator import itemgetter
from movies import titles- import matplotlib.pyplot as plt
: pyplot을 이용해서 마지막에 차트를 그리기 위한 라이브러리
- import json
: 입력방르 JSON 타입의 파일을 불러와서 dictionary로 변환하기 위한 라이브러리
- from operator import itemgetter
: itemgetter 함수는 주로 데이터 정렬 혹은 특정 데이터 추출하는 역할로 사용되는 것으로, 호출함수인 caller를 return하고 caller는 실제로 iterable한 값에 대해 인자로 지정된 n번째 원소를 최종적으로 return 하게 된다.
# ex1) 원소 추출
from operator import itemgetter
a = [1, 3, 5]
func = itemgetter(2)
print(func(a)) # 5
# ex2) 데이터 정렬
from operator import itemgetter
dots = [(1, 2), (1, 3), (-1, 7), (-1, 4)]
dots = sorted(dots, key = itemgetter(1))
print(dots) # [(1, 2), (1, 3), (-1, 4), (-1, 7)]
→ dots 리스트의 1번째 index에 해당하는 값을 기준으로 정렬
- from movies import titles
: movies.py 파일 내 영화들의 제목이 담긴 titles import 하기 위한 코드
→ 딕셔너리 형태로 정수형(int)인 key값에 따라 영화 title이 저장된 데이터모음
2. JSON 데이터를 Dictionary 형태로 저장하기
입력받은 JSON 형식의 데이터(netflix.json)을 딕셔너리 형태로 변환하여 return 하는 함수 생성
→ 이때 int() 를 이용해서 'key'는 정수형으로 설정하기
→ preprocess_data(filename)
# netflix.json 데이터의 key는 '영화 id', value는 '유저 id'가 담긴 리스트로 구성되어있다. (아래 사진 첨부)

# 1) JSON 데이터를 dictionary 형태로 return 하기
def preprocess_data(filename):
# JSON 데이터를 저장할 빈 딕셔너리 생성
processed = {}
with open(filename) as file:
# 입력 받은 JSON 파일을 불러와서 'loaded'에 저장
loaded = json.loads(file.read())
# JSON 형식의 데이터에서 영화와 사용자 정보 하나씩 가져오기
for title, users in loaded.items():
# 'processed' 딕셔너리에 title을 key로, users를 value로 저장
processed[int(title)] = users
return processed위에 생성한 함수(preprocess_data())을 통해서 'netflix.json' 데이터가 입력되면 각 영화 id에 대해 해당 영화를 시청한 user들의 id를 담고 있는 리스트로 매칭되는 dictionary로 return할 수 있다.
즉, (영화 id : users id) 형태의 json 데이터들을 dictionary 형태로 변환시키는 함수 생성 완료
→ return 예시 : {영화 id : [user id1, user id2, ...], [...], ...}
3. reformat : 작품별 시청한 User → User별 시청한 작품
작품별 시청한 사용자가 정보가 담긴 dictionary 형태의 데이터인 'title_to_users'가 주어진다. 이 데이터를 통해서 사용자별 시청 작품이 각각 key와 value로 담긴 dictionary로 return 될 수 있는 함수를 생성하시오
→ 즉, "작품별 시청한 사용자 → 사용자별 시청한 작품"들의 조합(key, value)로 reformat 하시오
→ title_to_users : 위의 preprocess_data() 의 return 값 (JSON → Dictionary로 변환된 데이터)
# 2) Dictionary의 reformat
def reformat_data(title_to_users):
# 작품별 시청한 사용자 → 사용자별 시청한 작품
# 사용자별 시청한 작품 데이터를 넣을 새로운 dictionary 생성
user_to_titles = {}
for title, users in title_to_users.items():
for user in users:
# user가 '사용자별 시청한 작품데이터' 안에 있다면, 해당 user의 작품리스트에 title 추가
if user in user_to_titles:
user_to_titles[user].append(title)
# 없다면, 딕셔너리에 새로운 user와 영화 title 추가
else:
user_to_titles[user] = [title]
return user_to_titles위 함수를 통해 '사용자별 시청한 작품'이 각각 key와 value로 저장된 dictionary 형태로 return 될 수 있도록 한다.
→ return 예시 : {user id : [영화 id1, 영화 id2, ...], [.....], ... }
반응형
4. 두 영화 작품의 유사도 산출
두 개의 영화 title을 입력받으면, 두 작품에 대한 유사도를 구하는 함수를 생성해보자.
이 때, '(유사도) = (두 작품을 모두 본 사람) / (두 작품 중 하나라도 본 사람)' 으로 구해보자.
→ get_closeness(title_to_users, title1, title2)
입력받은 title1과 title2를 시청한 사람들의 집합(set)을 구한 후에 유사도를 구하면 된다.
→ 순서와 중복에 영향을 받지 않으므로 집합으로 구하는 것이 수월하다.
# 3) 작품 간의 유사도 산출
def get_closeness(title_to_users, title1, title2):
# title1과 title2의 영화를 시청한 사람들의 집합 생성
title1_users = set(title_to_users[title1])
title2_users = set(title_to_users[title2])
# 유사도 = (두 작품을 모두 본 사람) / (두 작품 중 하나라도 본 사람)
both = len(title1_users & title2_users)
either = len(title1_users | title2_users)
return both / either
# 함수 테스트
filename = 'netflix.json'
title_to_users = preprocess_data(filename)
# 2개의 임의의 영화 id 입력
title1 = 2452 # 반지의 제왕 - 반지 원정대
title2 = 11521 # 반지의 제왕 - 두 개의 탑
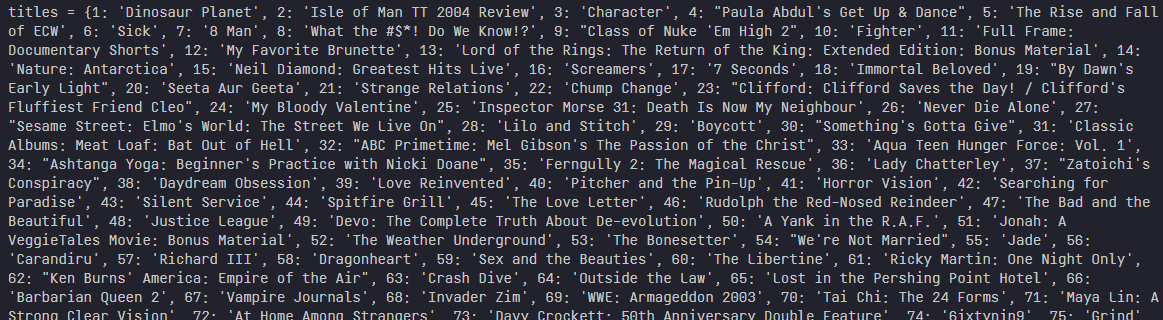
print(get_closeness(title_to_users, title1, title2))
위와 같이 입력받은 두 작품에 대한 유사도를 산출할 수 있는 함수를 생성하였고, 임의의 영화 id를 인자로 넣어주면 결과를 확인할 수 있다.
→ '반지의 제왕 - 반지원정대(id : 2452)'와 '반지의 제왕 - 두 개의 탑(id : 11521)'은 서로 유사도가 0.8966 로 산출되어 꽤 유사도가 높다고 해석할 수 있다.
5. 임의의 영화 작품에 대한 사용자의 '예상 선호도' 출력
임의의 작품과 사용자(user)가 주어졌을 때, user가 그 작품을 선호할 "예상 선호도"를 계산하는 함수를 만들어보자. 이때, '예상 선호도'란 사용자(user)가 시청한 모든 작품과 입력된 작품(title) 간 유사도의 평균값이 된다.
→ ex) 사용자(user) A가 총 시청한 3개의 작품과 작품1의 유사도가 0.6, 0.4, 0.5일 때 선호도 점수는 평균값은 '0.5'로 산출된다.
→ predict_preference(title_to_users, usr_to_titles, user, title)
# 4) 작품과 사용자에 대한 예상 선호도 측정
def predict_preference(title_to_users, user_to_titles, user, title):
# 입력받은 user가 시청한 영화 작품들(영화 id)
titles = user_to_titles[user]
# user가 시청한 작품리스트를 돌면서 입력받은 title의 영화 간 유사도 측정
closeness = [get_closeness(title_to_users, title, title2) for title2 in titles]
# 예상 선호도 = 계산된 선호도들의 평균값
return sum(closeness) / len(closeness)
# 함수 테스트
filename = 'netflix.json'
title_to_users = preprocess_data(filename)
user_to_titles = reformat_data(title_to_users)
# 임의의 영화와 사용자의 id 입력
title = 11521 # 반지의 제왕 - 두 개의 탑
user = 1048579 # 임의의 사용자 id 지정
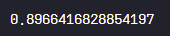
print(predict_preference(title_to_users, user_to_titles, user, title))
임의의 작품과 사용자를 입력받고 그에 대한 '예상 선호도'를 수치화하는 함수가 잘 실행됨을 확인할 수 있다.
# 결과 해석
예시로로 '1048579'의 user-id를 가진 사용자가 '11521' 값을 가지는 '반지의 제왕 - 두 개의 탑'인 영화를 선호할 수치(=예상 선호도)는 대략 '0.624'로 산출되어 선호할 가능성이 있다고 판단할 수 있다.
6. 사용자를 위한 영화 추천 Top 10 생성 & main 함수로 통합
지금까지 데이터 분석을 통해 생성한 함수들을 main 함수 안에 통합 실행될 수 있도록 생성해보자. 그리고 영화 작품A와 작품B가 주어졌을 때 작품성향(or 장르)의 유사도를 산출하고, 가상의 user와 시청한 작품들을 임의로 생성해서 영화를 추천받을 수 있는 코드를 만들어보자.
1) 두 영화 작품 간 유사도 산출
2) 가상의 user(=minsu)와 시청한 작품을 바탕으로, 선호할만한 영화 Top 10 추천받기
# 5) 영화 추천 Top 10 & main 함수 통합
def main():
filename = 'netflix.json'
# json 데이터를 dictionary 형태로 변환
title_to_users = preprocess_data(filename)
# user별 시청한 데이터로 전환
user_to_titles = reformat_data(title_to_users)
# 임의의 영화 id 지정
movieid1 = 2452 # 반지의 제왕 - 반지 원정대
movieid2 = 11521 # 반지의 제왕 - 두 개의 탑
movieid3 = 14240 # 반지의 제왕 - 왕의 귀환
killbill1 = 14454 # 킬빌 - 1부
killbill2 = 457 # 킬빌 - 2부
jurassic_park = 14312 # 쥬라기 공원
shawshank = 14550 # 쇼생크의 탈출
print("[유사도 측정]")
title1 = movieid1
title2 = killbill1
# 두 영화에 대한 작품 성향 유사도
description = "'{}'와 '{}'의 작품 성향 유사도".format(titles[title1], titles[title2])
# 유사도(closeness)를 round()로 반올림 처리
closeness = round(get_closeness(title_to_users, title1, title2) * 100)
print("{}: {}%".format(description, closeness))
# 임시테스트를 위한 가상의 user(minsu)와 시청한 작품을 생성
username = 'minsu'
new_utt = user_to_titiles.copy()
new_utt[username] = [movieid1, movieid2, movieid3]
# 가상의 user(minsu)를 위한 작품 추천
print("\n")
print("['{}' 유저를 위한 작품 추천]".format(username))
# 작품리스트와 해당 작품에 대한 가상 user의 예상선호도 계산
preferences = [(title, predict_preference(title_to_users, new_utt, username, title)) for title in title_to_users]
# key값인 예상선호도(index=1)를 기준으로 내림차순 정렬(reverse=True)
preferences.sort(key=itemgetter(1), reverse=True)
# 예상선호도 Top10에 대해 영화 title(p[0])과 예상선호도(p[1]) 출력
for p in preferences[:10]:
print("{} ({}%)".format(titles[p[0]], round(p[1] * 100)))
if __name__ == "__main__":
main()

- preferences = [(title, predict_preference(title_to_users, new_utt, username, title)) for title in title_to_users]
: 작품별 시청한 사용자 데이터(dictionary)를 순회하면서 가상의 user(minsu)의 예상선호도 계산하여 저장
→ preferences = (순회한 title, 해당 title에 대한 예상선호도) - tuple 구조
- preferences.sort(key=itemgetter(1), reverse=True)
: key값인 예상선호도(index = 1)를 기준으로 내림차순 정렬 (reverse = True)
- for p in preferences[:10]:
print("{} ({}%)".format(titles[p[0]], round(p[1] * 100)))
→ titles[p[0]] : 전체 영화 작품리스트(titles)에서 가상 user가 선호할만한 영화 id값(p[0])을 입력받아서 출력
→ round(p[1] * 100) : 해당 작품에 대한 예상선호도를 반올림해서 백분율로 표현(%)
7. 최종 코드 및 테스트
최종 코드를 정리해보고, 마지막 main() 함수를 실행할 때 아래의 문항들을 고려 및 수정해서 성능을 테스트해보자.
1. 두 작품의 유사도를 측정할 때, 비교 작품 변경 후 유사도 산출
→ 반지의 제왕(반지 원정대, 2452) vs 반지의 제왕(두 개의 탑, 11521)
2. 시청한 작품의 수가 작은 user 추출
→ 작품의 수가 많은 user에게 영화 추천코드를 돌리면 계산식이 길어져서 실행시간 길어짐
→ netflix.json 내 user들 중, 작품의 수가 10~15개 정도의 user로 설정하는 걸 추천
3. 선택한 user가 시청한 영화 작품코드 출력
→ 영화 추천을 받기 위해 user가 시청했던 영화가 무엇인지 확인
4. user를 위한 영화 작품 추천
→ '영화 이름 (예상선호도(%))' 형태로 예상선호도가 높은 순으로 산출
→ movies.py 내 import 한 title 데이터에서 작품 코드(id)에 따른 영화 제목 끌어오기
import matplotlib.pyplot as plt
import json
from operator import itemgetter
from movies import titles
# 1) JSON 데이터를 Dictionary 형태로 return 하기
def preprocess_data(filename):
# JSON 데이터를 저장할 빈 딕셔너리 생성
processed = {}
with open(filename) as file:
# 입력 받은 JSON 파일을 불러와 loaded에 저장
loaded = json.loads(file.read())
# JSON 형식의 데이터에서 영화와 사용자 정보를 하나씩 가져오기
for title, users in loaded.items():
# processed 딕셔너리에 title을 key로, users를 value으로 저장합니다.
processed[int(title)] = users
return processed
# 2) Dictionary의 reformat
def reformat_data(title_to_users):
# 작품별 시청한 사용자 → 사용자별 시청한 작품
# 사용자별 시청한 작품 데이터를 넣을 새로운 dictionary 생성
user_to_titles = {}
for title, users in title_to_users.items():
for user in users:
# 사용자가 사용자별 시청한 작품데이터 안에 있다면, 해당 user의 작품리스트에 영화 title 추가
if user in user_to_titles:
user_to_titles[user].append(title)
# 없다면, 딕셔너리에 새로운 user와 영화 title 추가
else:
user_to_titles[user] = [title]
return user_to_titles
# 3) 작품 간의 유사도 산출
def get_closeness(title_to_users, title1, title2):
# title1과 title2의 영화를 시청한 사람들의 집합 생성
title1_users = set(title_to_users[title1])
title2_users = set(title_to_users[title2])
# 유사도 = (두 작품을 모두 본 사람) / (두 작품 중 하나라도 본 사람)
both = len(title1_users & title2_users)
either = len(title1_users | title2_users)
return both / either
# 함수 테스트
# filename = 'netflix.json'
# title_to_users = preprocess_data(filename)
# 2개의 임의의 영화 id 입력
# title1 = 2452 # 반지의 제왕 - 반지 원정대
# title2 = 11521 # 반지의 제왕 - 두 개의 탑
# print(get_closeness(title_to_users, title1, title2))
# 4) 작품과 사용자에 대한 예상 선호도 측정
def predict_preference(title_to_users, user_to_titles, user, title):
# 입력받은 user가 시청한 영화 작품들
titles = user_to_titles[user]
# user가 시청한 작품리스트를 돌면서 입력받은 title의 영화 간의 유사도 측정
closeness = [get_closeness(title_to_users, title, title2) for title2 in titles]
return sum(closeness) / len(closeness)
#filename = 'netflix.json'
#title_to_users = preprocess_data(filename)
#user_to_titles = reformat_data(title_to_users)
#title = 11521 # 반지의 제왕 - 두 개의 탑
#user = 1048579 # 임의의 사용자 id
#print(predict_preference(title_to_users, user_to_titles, user, title))
# 5) main 함수 통합
def main():
filename = 'netflix.json'
# json 데이터를 dictionary 형태로 변환
title_to_users = preprocess_data(filename)
# user별 시청한 데이터로 전환
user_to_titles = reformat_data(title_to_users)
# 임의의 영화 id 지정
movieid1 = 2452 # 반지의 제왕 - 반지 원정대
movieid2 = 11521 # 반지의 제왕 - 두 개의 탑
movieid3 = 14240 # 반지의 제왕 - 왕의 귀환
killbill1 = 14454 # 킬 빌 - 1부
killbill2 = 457 # 킬 빌 - 2부
jurassic_park = 14312 # 쥬라기 공원
shawshank = 14550 # 쇼생크 탈출
print("\n")
print("[유사도 측정]")
title1 = movieid1
title2 = movieid2
# titles : 영화 id를 key값으로 가지는 영화 작품리스트
description = "'{}'와 '{}'의 작품 성향 유사도".format(titles[title1], titles[title2])
# 유사도(closeness)를 round()로 반올림
closeness = round(get_closeness(title_to_users, title1, title2) * 100)
print("{}: {}%".format(description, closeness))
# 임시테스트를 위해 가상의 user(minsu)와 시청한 작품을 입력 ---------------------------------------
# username ='minsu'
# new_utt = user_to_titles.copy()
# new_utt[username] = [movieid1, movieid2, movieid3]
# 5-1) 가상의 user(minsu)를 위한 작품 추천
# print("\n")
# print("['{}' 유저를 위한 작품 추천]".format(username))
# 작품리스트와 해당 작품에 대한 가상 user의 예상선호도 계산
# preferences = [(title, predict_preference(title_to_users, new_utt, username, title)) for title in title_to_users]
# 작품별 시청한 사용자 데이터(dictionary)를 순회하면서 가상의 user(minsu)의 예상선호도 계산하고
# preferences = (순회한 title, 해당 title에 대한 예상선호도) - tuple 구조
# key값인 예상선호도(index = 1)를 기준으로 내림차순 정렬(reverse = True)
# preferences.sort(key=itemgetter(1), reverse=True)
# 예상선호도 Top 10에 대해 영화 title(p[0])과 예상선호도(p[1]) 출력
# for p in preferences[:10]:
# titles[p[0]] : 전체 영화 작품리스트(titles)에서 가상 user이 선호할 만한 영화 id값(p[0])을 입력받아서 출력
# round(p[1] * 100) : 해당 작품에 대한 예상선호도를 반올림해서 백분율로 표현(%)
# print("{} ({}%)".format(titles[p[0]], round(p[1] * 100)))
# 임시테스트 끝 ---------------------------------------------------------------------------------------
# 5-2) netflix.json 내 실제 user에 대해 분석
# 시청한 작품 수가 작은 user 순위
print("\n")
print("[시청한 작품 수가 작은 user]")
new_tuple = [(user, len(user_to_titles[user])) for user in user_to_titles]
new_tuple.sort(key=itemgetter(1))
for t in new_tuple[:10]:
print(t)
# 실제 인물(id : 2310820)을 위한 작품 추천 코드 ---
username = 2310820
print("\n")
print("['{}' 유저가 시청한 작품코드]".format(username))
print(user_to_titles[username])
print("\n")
print("['{}' 유저를 위한 영화 추천]".format(username))
preferences = [(title, predict_preference(title_to_users, user_to_titles, username, title)) for title in title_to_users]
preferences.sort(key=itemgetter(1), reverse=True)
for p in preferences[:10]:
print("{} ({}%)".format(titles[p[0]], round(p[1] * 100)))
if __name__ == "__main__":
main()
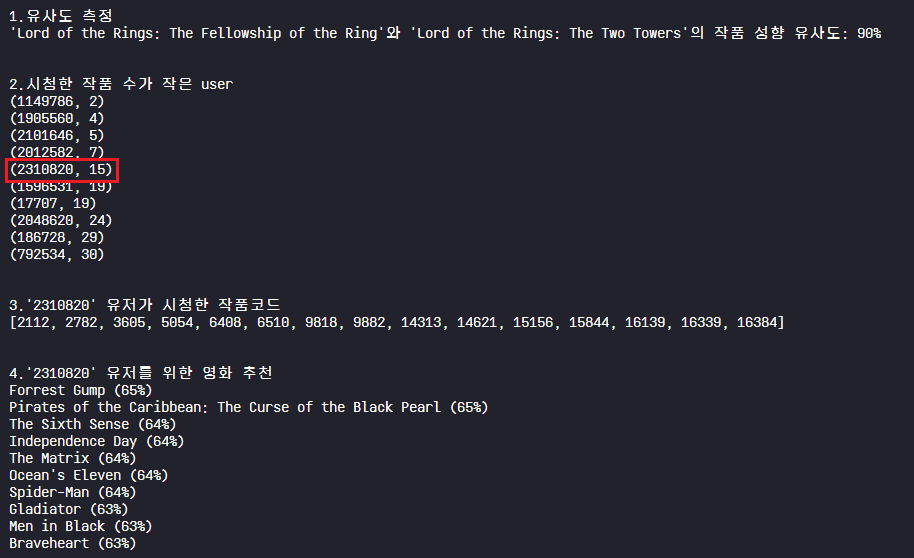
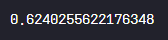
결과)
1. 반지의 제왕 영화의 '반지 원정대'와 '두 개의 탑' 의 작품 유사도는 '90%'로 꽤 유사하다
2. 시청한 작품 수가 작은 user는 '1149786' 이지만, 어느 정도의 높은 예상선호도를 갖는 결과를 얻기 위해서 적정 수준인 시청한 작품 수가 15개인 '2310820' user로 선택
3. 선택한 유저('2310820')가 시청한 영화 작품 코드(id) 출력
→ 시청한 영화들을 기반으로 유사도 높은 순으로 산출하기 위한 단계. 총 15개의 작품으로 확인
4. 유저('2310820')를 위한 영화 Top 10 추천
→ 예상선호도(%)가 높은 순으로 영화의 제목(title)과 선호도가 잘 출력됨
'Data Analyst > Project & Practice' 카테고리의 다른 글
| TED 강연 데이터 분석하기! 가장 인기 있는 강의 유형은? (1) | 2024.01.21 |
|---|---|
| CSV, JSON 데이터 처리 - lambda, assert, map, filter 등 (4) | 2024.01.11 |
| JSON 형식을 dictionary로 변환할때 알아야 할 이론과 실습! (w/넷플릭스 시청데이터) (1) | 2023.12.04 |
| [파이썬 데이터분석] 가장 많이 사용하는 '영어 단어'는? 코드 구현! (2) | 2023.11.20 |
| 데이터 분석 - 파일/데이터의 구조/그래프 다루기 기초 정리! (1) | 2023.11.18 |




댓글