데이터 분석 - 파일/데이터의 구조/그래프 다루기 기초 정리!
728x90
반응형
데이터 분석을 하는데 있어 "다룰 줄 알아야 하는 기초적인 3가지"를 학습하자!
이번에 학습한 내용과 코드를 바탕으로 다음 게시물에서는 "대략 1억 개의 영문단어들 중 가장 많이 사용되는 단어 10,000개를 추출하고 시각화"해보자.
"파일, 데이터의 구조, 그래프를 다루는 방법" 학습하고
다음 게시물을 통해 영어 단어의 사용 빈도수를 분석하는 실습을 진행하자

1. 파일 다루기 (open, close, read, write 등)
파일 다루기는 파일을 열고 닫는 함수부터 읽고 쓰는 함수까지 있다. 아래 코드로 확인해보자.
→ open() 함수를 통해 지정한 파일 이름에 해당하는 파일을 열고, 읽거나 수정할 수 있다.
→ 'with ~ as' 구문을 이용하면 파일을 자동으로 닫을 수 있고, for문을 통해 파일 내용을 한 줄씩 읽을 수 있다.
1) 파일을 열기 / 닫기
# 파일 열기/닫기
file = open('data.txt') # 열기
content = file.read() # 읽어오기
content = file.write() # 쓰기
file.close() # 닫기
# 파일 자동으로 닫기
with open('data.txt') as file:
content = file.read()
# file.close() - 필요 없음- with ~ as 구문을 통해 특정 파일을 불러오고 자동으로 닫을 수도 있다.
→ 위의 코드들은 서로 동일한 역할을 한다. 코드의 줄만 다름
→ 'data.txt' 파일을 불러와서 file 이라고 지정하고, 들여쓰기 한 with 구문 안에서만 적용된다.
→ 들여쓰기 내 마지막 코드까지 실행되고, 파일은 자동으로 close 된다.
2) 파일 읽기 (줄 단위로 읽기)
파일을 읽기 위해서는 .read() 함수도 있지만, 보통은 줄 단위로 읽게 된다.
→ 이 때, for문을 이용해서 줄마다 특정 데이터를 순서대로 읽게 된다.
# 파일 읽기
contents = [] # 저장하고 싶은(?) 빈 리스트 생성
with open('data.txt') as file:
for line in file:
content.append(line)- for line in file :
content.append(line)
→ file 내 각 줄의 내용이 'line' 이라는 변수에 담기게 되고
→ file에 포함된 각 line에 대해서 빈 리스트인 'content'에 추가된다.
3) 파일의 모드
파일을 열때(open), 존재하는 다양한 모드가 있다.
→ 파일을 열때 읽기 or 쓰기 or 읽고 쓰기가 모두 가능한 모드로 할지 정할 수 있다.
→ 아무런 모드를 설정하지 않으면, 자동으로 읽기 모드로 open 된다.
# 쓰기(Write) 모드로 파일을 열대
with open('data.txt', 'w') as file:
file.write('Hello')파일에 새로운 내용을 작성(write)하고자 한다면, 'w' 키워드를 추가해주면 된다.
→ 위에서는 file에 'Hello'가 입력되어 저장된다.
# 실습 (파일 열고 읽기)
데이터가 저장된 파일을 읽어오는 실습을 해보자. 아래 파일의 내용을 각 줄의 번호와 함께 출력하는 'print_lines()' 함수를 완성하시오.
# 텍스트 파일 불러오기 (동일 디렉토리에 파일 존재)
filename = 'corpus.txt'
# 각 줄의 번호와 내용을 함께 출력하는 함수
def print_lines(filename):
with open(filename) as file:
line_number = 1
for line in file:
print(line_number, line)
line_number += 1
# 함수 실행
print_lines(filename)

위의 코드를 실행한 일부분의 결과를 보면, 주어진 'corpus.txt' 파일 내 각 줄의 번호와 내용을 함께 출력된 것을 확인할 수 있지만 출력될 때마다 한 줄씩 띄어져서 나온다. 그 이유는 아래에 '데이터 구조 다루기'에서 확인해보자.
2. 데이터 구조 다루기 (튜플, 형태 변환)
파이썬에서의 '데이터 구조'란 리스트, 문자열 그리고 튜플(Tuple)이 있다.
이번에는 튜플의 형태 변환에 대해 조금 더 복습하면서 코드에 적용하는 연습을 해보자
# 튜플(Tuple) 연습
hello = ('안녕하세요', 'hello', 'bonjour')
apple = ('사과', 'apple', 'pomme')
red = ('빨갛다', 'red', 'rouge')
# 튜플(Tuple) vs 리스트(List)
- 공통점 : 순서가 있는 원소들의 집합
- 차이점
→ 각 원소의 값을 수정할 수 없음 (Tuple)
→ 원소의 개수를 바꿀 수 없음 (Tuple)
# 리스트의 변형
hello = ['안녕하세요', 'hello', 'bonjour']
hello[0] = ['안녕']
print(hello) # ['안녕', 'hello', 'bonjour']
hello.append('ni hao')
print(hello) # ['안녕', 'hello', 'bonjour', 'ni hao']위의 코드와 같이 리스트는 특정 원소를 수정하거나 원소들을 제거 혹은 추가할 수 있지만, 튜플(Tuple)은 그렇지 않다.
즉, 리스트와 다르게 () 안에 요소가 한번 생성한 튜플은 그 값을 변경할 수 없게 된다.
# 튜플의 변형(?)
hello = ('안녕하세요', 'hello', 'bonjour')
hello[0] = '안녕' # 에러
hello.append('ni hao') # 함수 적용 불가능튜플의 원소들을 바꾸는 유일한 방법은, 새로운 튜플을 다시 정의하는 것
ex) hello = ('안녕', 'hello', ...)
# 실습 (데이터 형태 변환하기)
아래와 같이 주어진 주어진 'corpus.txt'의 내용을 읽고 (단어, 빈도수) 튜플로 구성된 리스트를 리턴하는 'import_as_tuple()' 함수를 완성하시오
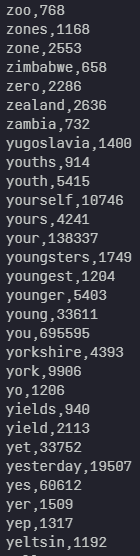
위의 'corpus.txt' 파일을 보면 각 단어의 빈도 수가 표시된 것을 확인할 수 있다.
→ (단어, 빈도 수) 형태
# 데이터 형태 변환하기
def import_as_tuple(filename):
tuples = []
with open(filename) as file:
for line in file:
# 쉼표(,)를 기준으로 단어(앞)와 빈도수(뒤)를 분리
split = line.strip().split(',')
word = split[0]
freq = split[1]
new_tuple = (word, freq)
# 생성한 튜플을 리스트에 넣기
tuples.append(new_tuple)
return tuples
# 함수 실행
print(import_as_tuple(filename))


# 주의사항
: file에서 line별로 읽어올 때 줄바꿈도 같이 읽어오기 때문에 줄바꿈(\n)이 함께 출력되거나 적용된다.
맨 마지막 튜플 혹은 결과에는 줄바꿈(\n)이 없음
→ .strip() 함수를 사용하면 해결 가능!
: 어떤 문자열(요소)의 앞/뒤에 있는 모든 공백문자들을 제거하는 역할을 하는 함수로써, 튜플뿐 아니라 문자열에도 적용할 수 있고, 가공하기 더 깔끔한 형태로 바꿀 수 있다.
3. 리스트로 새로운 리스트 만들기
작성할 코드를 더욱 짧게 만들어줄 수 있다.
→ ex) 어떤 리스트를 이용해서 다른 리스트를 만들때 더욱 간결하게 만드는 법
1) List comprehension
# 리스트로 다른 새로운 리스트 만들기(1)
words = ['life', 'love', 'faith']
first_letters = []
for word i words:
first_letters.append(word[0]) # ['l', 'l', 'f']
# 위의 코드를 더 간결하게 만들기
words = ['life', 'love', 'faith']
first_letters = [word[0] for word in words] # ['l', 'l', 'f']새롭게 만든 리스트(first_letters) 안에 for문이 들어가는 방식!
→ words 리스트에 들어있는 모든 원소(word)에 대해서 각 원소의 0번째(=index(0))를 리스트로 만든다.
# 리스트로 다른 새로운 리스트 만들기(2)
numbers = [1, 3, 5, 7]
new_numbers = []
for n in numbers:
new_numbers.append(n + 1)
# 위의 코드를 간결하게 (list comprehension)
numbers = [1, 3, 5, 7]
new_numbers = [(n + 1) for n in numbers]2) 특정 원소 걸러내기
이전까지 List 안에 for 문을 넣어서 코드를 더 간결하게 작성하는 법을 배웠다면, 이번에는 for문 외 다른 구문(ex, if 조건문 등)을 넣어서 표현할 수도 있다.
# 주어진 List에서 짝수만 골라서 새로운 리스트에 저장
numbers = [1, 3, 4, 5, 6, 7]
even = []
for n in numbers:
if n % 2 == 0: # 나머지(%)가 0 인 경우
even.append(n)
# 위의 코드를 더 간결하게 작성
numbers = [1, 3, 4, 5, 6, 7]
even = [n for n in numbers if n % 2 == 0]새로운 List 안에 for 문을 처음처럼 작성하고, 조건을 추가하면 코드가 훨씬 간결해진다.
+) 리스트 내에서 조건문, for 문, 그리고 for문에 의해 원소를 수정할 수도 있다.
ex) odd = [n + 1 for n in numbers if n % 2 == 0]
: numbers 리스트에 속해있는 원소(n)에 대해서 n이 짝수(n%2=0)라면, (n + 1)을 'odd'라는 새로운 리스트에 넣어라
→ odd = [ 5, 7 ]
# 실습 (한 줄로 코드 짧게 쓰기)
아래 주어진 단어 모음(words)에서 'prefix'로 시작하는 단어로만 이루어진 리스트를 리턴하는 'filter_by_prefix' 함수를 완성하시오. (prefix는 사용자가 임의로 바꾸거나 설정할 수 있다.)
→ 함수는 단어 모음(리스트)와 시작하는 모음(단어)를 입력받으면, 해당 리스트에서 조건을 만족하는 원소로만 이루어진 리스트가 생성
# 단어 모음 선언
words = [
'apple',
'banana',
'alpha',
'bravo',
'cherry',
'charlie',
]
# 특정 모음/단어로 시작하는 리스트로 추출함수
def filter_by_prefix(words, prefix):
filtered_words = [word for word in words if word.startswith(prefix)]
# filtered_words = [word for word in words if word[0] == prefix]
return filtered_words
# 함수 실행
filtered_word_a = filter_by_prefix(words, 'a')
filtered_word_b = filter_by_prefix(words, 'b')
print(filtered_word_a)
print(filtered_word_b)
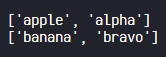
위와 같이 처음 시작하는 특정 영어모음에 해당하는 단어들만 잘 추출된 것을 확인할 수 있다.
- filtered_words = [word for word in words if word.startswith(prefix)]
1) filtered_words = [word for word in words if word[0] == prefix]
2) filtered_words = []
for word in words:
if word.startswith(prefix):
filtered_words.append(word)
return filtered_words
: 위의 코드는 1번과 2번과 같이 동일하게 작성할 수 있고, line comprehension으로 간략하게 list 안에 for문과 if 조건문을 넣은 형태이다. (startswith() : 특정 문자의 가장 앞에 있는 문자 혹은 단어 추출)
4. 데이터 정렬하기
리스트를 손쉽게 정렬하는 파이썬의 기본 함수에 대해 공부해보자.
이 때, 정렬한다는 의미는 원소들의 순서를 기호에 맞게 바꿔준다는 의미로 아래 코드를 보자
- sorted() 를 활용하여 리스트를 특정 기준에 맞춰 정렬할 수 있다. 이 때의 기준은 key에 저장된 함수를 따른다.
# 절대값으로 데이터 정렬하기
numbers = [-1, 3, -4, 5, 6, 100]
sort_by_abs = sorted(numbers, key=abs) # [1, 3, 4, 5, 6, 100]- sorted(정렬하고자 하는 리스트, key 인자)
: key값을 생략하면 오름차순으로 자동정렬됨
# 문자열이 포함된 리스트 정렬
fruits = ['cherry', 'apple', 'banana']
sort_by_alphabet = sorted(fruits) # ['apple', 'banana', 'cherry']- sorted(fruits)
: key 인자없이 정렬하고자하는 리스트만 넣어주면, 위와 같이 알파벳의 순서대로 정렬된다.
# 데이터 정렬
def reverse(word):
return str(list(reversed(word)))
fruits = ['cherry', 'apple', 'banana']
sort_by_last = sorted(fruits, key = reverse) # ['banana', 'apple', 'cherry']반대로 정렬될 수 있는 'reverse()' 함수를 생성하고 key의 인자로 넣어주면, 정렬이 반대로 된다. (값 기준)
→ reversed(word) 반영
# 실습 (단어의 빈도 순서대로 정렬)
단어의 사용 빈도를 쉽게 확인하기 위해서는 단어를 빈도 순서대로 정렬해야 한다. 아래의 안내로 작업에 필요한 함수('get_freq()')와 'sort_by_frequency()' 함수를 완성하시오.
# 단어어 해당 단어의 빈도수를 담은 리스트를 선언
pairs = [
('time', 8),
('the', 15),
('turbo', 1),
]
# (단어, 빈도수)로 이루어진 튜플(Tuple)을 받아서 빈도수를 return
def get_freq(pair):
return pair[1]
# (단어, 빈도수) 튜플의 리스트를 받아서, 빈도수가 낮은 순서대로 정렬하여 return
def sort_by_frequency(pairs):
for pair in pairs:
freq = sorted(pairs, key = get_freq)
return freq
# 결과 확인
print(sort_by_frequency(pairs))1) get_freq(pair):
: 각 튜플의 빈도수는 1번째 index에 해당하기 때문에, pair[1]를 return 해주면 된다.
2) sort_by_frequency(pairs):
: (단어, 빈도수)으로 이루어진 튜플을 받아 빈도수를 return하는 'get_freq()' 함수를 sorted 함수의 key 인자로 넣어주면 된다.
+) 간단하게 동일한 함수를 간단하게 작성할 수도 있다.
→ def sort_by_frequency(pairs):
return sorted(pairs, key = get_freq)

위 결과를 보면, 주어진 리스트에서 빈도수가 낮은 순서부터 오름차순으로 잘 정렬된 것을 확인할 수 있다.
5. 그래프 다루기
데이터를 알기 쉽게 분석하고 보기 좋게 시각화하는 것이 학습 목표이다.
따라서 그래프를 쉽게 다룰 수 있도록 matplotlib 라이브러리를 학습하고 실습해보자.
# matplotlib (Mathematical Plot Library)
: 파이썬에서 그래프를 그릴 수 있게 하는 라이브러리. 다양한 그래프를 지원
# 실습 (차트 그리기)
matplotlib의 bar() 메서드를 이용하여 최근 평균 기온 그래프를 간단히 그려보자.
아래를 학습하고 다음 게시물에서 영어 단어의 빈도수를 쉽게 비교하기 위한 그래프도 시각화해보자.
# matplotlib 라이브러리 import
import matplotlib.pyplot as plt
# 월별 평규 기온 선언 (예시)
years = [2013, 2014, 2015, 2016, 2017]
temperatures = [5, 10, 15, 20, 17]
# 막대 차트(bar) 출력
def draw_graph():
# 막대 그래프의 막대 위치를 결정하는 pos 선언
pos = range(len(years)) # [0, 1, 2, 3, 4]
# 높이값이 온도인 막대그래프 출력. (각 막대를 가운데 정렬)
plt.bar(pos, temperatures, align='center')
# 각 막대에 해당되는 연도 표기
plt.xticks(pos, years)
# 그래프 출력
draw_graph()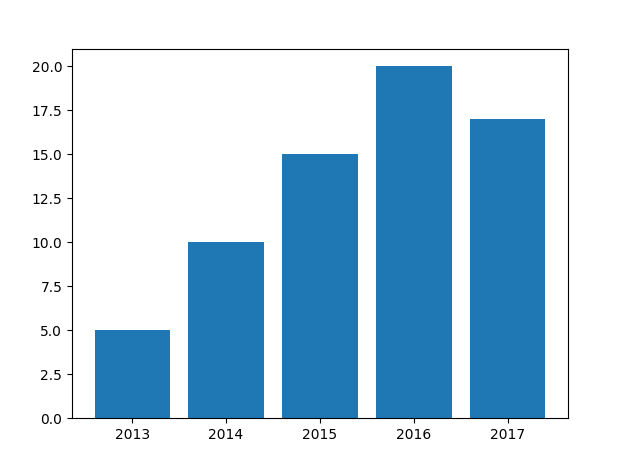
'Data Analyst > Project & Practice' 카테고리의 다른 글
| 넷플릭스 영화 추천 알고리즘 파이썬 코드로 구현하기! 시청데이터로 예상 선호도 산출! (2) | 2023.12.04 |
|---|---|
| JSON 형식을 dictionary로 변환할때 알아야 할 이론과 실습! (w/넷플릭스 시청데이터) (1) | 2023.12.04 |
| [파이썬 데이터분석] 가장 많이 사용하는 '영어 단어'는? 코드 구현! (2) | 2023.11.20 |
| [파이썬] 트럼프 대통령이 1년 동안 게시한 트위터 데이터 분석!! (0) | 2023.11.16 |
| [파이썬] 데이터 분석하기 위해 꼭 알아야 할 기초 7가지!! (이론+실습) (0) | 2023.11.14 |




댓글