[Detection] Concept of Object Detection & 2-Stage Detector
728x90
반응형
1. Concept
Image Classification은 하나의 주요 대상을 식별하고 이미지 분류작업에 초점을 맞추었지만,
더 나아가 "물체의 위치를 탐지"하고 분류하는 모델을 객체 탐지(Object Detection)이라고 한다.
ex) 자율주행 자동차, 보안 분야에서의 효율적인 자원 관리 등

 0
0
2. Bounding box
객체 탐지 모델을 만들기 위해서는 물체를 사각형으로 표현하는 'Bounding box'를 생성해야 한다.
이는 (x, y) 좌표와 box의 너비, 높이를 이용해서 표현되며 박스를 통해서 객체를 올바르게 탐지하고, 학습 대상은 박스 영역에만 해당하기 때문에 효율적으로 수행이 가능하다.

- 바운딩 박스값은 (Xmin, Ymin, Xmax, Ymax)로 영역을 잡지만, 효율적인 연산을 위해서는 최대값을 1로 변환하여 산출하는 것이 좋다. (= normalization)
- Dataset에 따라 박스의 값이 메타데이터에 포함된 경우가 있지만, 없을 경우 코드 구현으로 지정!
# 메타데이터(metadata)
: 데이터에 관한 구조화된 데이터로, 다른 데이터를 설명해줄 수 있는 데이터.
→ 대량의 정보 가운데 찾고자 하는 정보를 효율적으로 찾아내기 위해 특정 규칙에 따라 부여된다.
ex) 콘텐츠의 위치, 내용 등의 정보의 index 역할도 수행
3. Model Architecture

→ 위 사진에서 볼 수 있듯이, Object detection 모델은 크게 2가지 분류로 나눌 수 있다.

# One-Stage Detector
: 객체의 Classification, Regional Proposal, 바운딩 regression을 한번에 수행하는 방식
→ 비교적 빠르지만, 정확도 ↓ ex) YOLO, SSD ...
# Two-Stage Detector
: Regional Proposal과 Classification을 순차적으로 수행하는 방식
→ 비교적 느리지만, 정확도 ↑ ex) R-CNN, Fast R-CNN ...
3-1. R-CNN

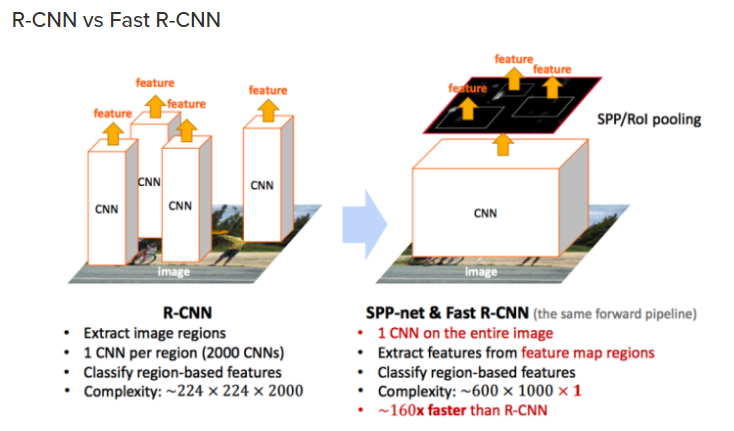
- R-CNN은 Selective Search(비신경망)을 이용하여 후보 영역(Region proposal) 생성하고, 생성된 각 영역을 고정된 크기로 wrapping 후, CNN을 통과한다.
→ 이후 CNN에서 나온 Feature map을 통해 Classification과 box regression 수행한다.
하지만, 강제로 이미지 크기를 맞추는 과정에서 이미지의 변형과 손실이 발생할 수 있으며,하나의 전체 이미지에 대한 수많은 후많은 Region proposal에 대해 모두 convolution 연산을 반복 수행한다는 것은 이로 인해 연산량이 너무 많아서 비효율적이며 느리다는 단점이 있다.
+) 이 때, 후보영역 검출을 위해 이미지 자르는 것을 "Sliding Window" 방식이라고 한다.
# 수행 순서 ( 아래의 과정을 모두 따로따로 수행한다 )
1) Region proposal 추출 -> 각 region proposal별 CNN 연산
2) Classification
3) Bounding box regression
3-2. Fast R-CNN
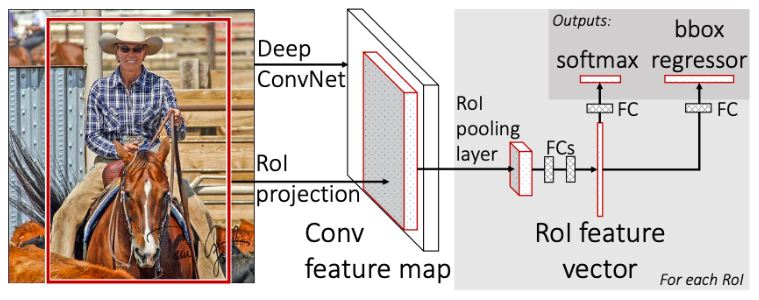
Fast R-CNN은 각 후보영역에 대해 모두 CNN을 적용하는 R-CNN과는 달리 이미지 전체에 대해 CNN을 한번 적용하고, 생성된 Feature map에서 후보영역(region proposal)을 생성한다.
→ 생성된 후보 영역을 Rol Pooling(= PoolRegion of Interest Pooling)을 통해 고정사이즈인 Feature vector로 추출 후, FC layer를 거치고 softmax와 regressor를 통해 각각 classification box 를 regression 한다.
여기서 CNN을 거친 후, Feature map의 영역에서는 다양한 모양과 크기를 가지므로 해당 영역이 어떤 class에 속하는 분류하기 위해서 사용하는 FC layer에 batch input으로 사용하려면 영역의 모양과 크기를 맞춰야 한다. 이 때, 사용되는 것이 'Rol Pooling'이다.
즉, 후보 영역에 해당하는 Feature를 원하는 크기가 될때까지 pooling 시키는 개념.
# 수행 순서
1) Region proposal 추출 -> 전체 image CNN 연산 -> Rol projection / Pooling
2) Classification & Bounding box regression
문제는..Region proposal 단계에서 Selective search 알고리즘이 CNN layer 밖에서 연산되기 때문에 'Rol 생성 단계가 병목(bottleneck) 현상'이 나타난다.
3-3. Faster R-CNN
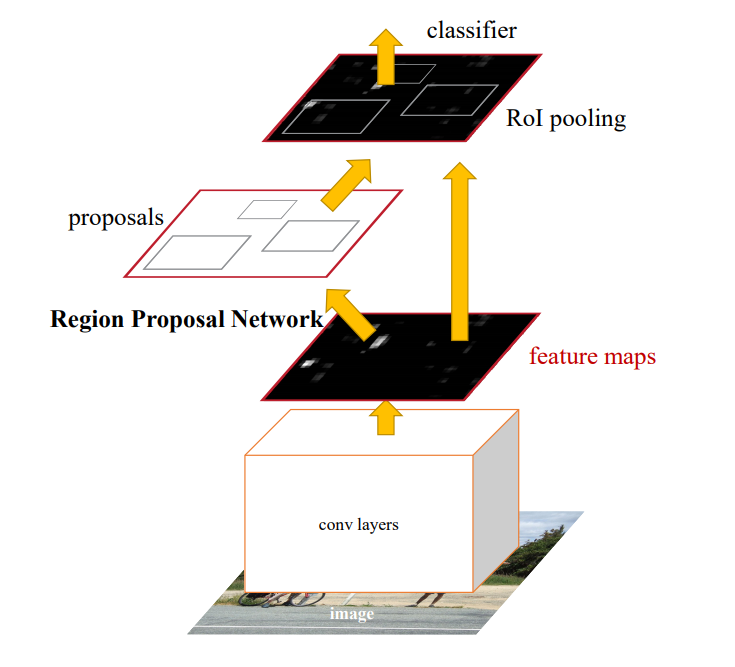
Fast R-CNN은 비효율적으로 반복되는 CNN 연산량을 크게 줄였지만, region proposal 알고리즘이 병목된다. 이를 더 빠르고 효율적으로 수행하기 위해 region proposal 과정에서 RPN (Region Proposal Network)라고 불리는 neural network를 사용한다.
기존의 후보영역을 산출할 때 쓰이는 방식인 Selective Search는 비신경망 알고리즘을 사용하여 느리지만, 이 때 Region proposal 생성하는 네트워크도 GPU에 넣어서 Convolution layer에서 생성하자는 것이 아이디어의 핵심이다.
→ 즉, detection에서 쓰이는 "Conv feature를 RPN에서 공유"하여 Rol pooling 생성 시, CNN level에서 수행하여 속도를 향상시킨다는 컨셉이다.
References>
- PseudoLab Tutorial(가짜연구소), Object Detection
- Sgrvinod Github(https://github.com/sgrvinod)
'AI |Computer Vision > Object Detection' 카테고리의 다른 글
| [Detection] Object detection 기본 용어 정리 및 성능 평가 지표 (0) | 2022.06.28 |
|---|

댓글