Data Analyst/Basic Python
[python] 데이터 분석의 기초! Numpy의 간단 총정리+실습!
Derrick
2023. 8. 30. 20:21
728x90
반응형
데이터셋(DataSet)을 효과적으로 다루기 위한
Numpy 라이브러리를 이론과 실습을 통해 학습하자

1. Numpy?
Numerical Python의 약자로, 파이썬에서 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리
Q) 그럼 왜 대규모 다차원의 배열일까?
A) 데이터들의 대부분은 숫자 배열로 볼 수 있다.
ex) 흑백 이미지는 해당 픽셀에 대한 명암으로 2차원의 배열로 표현이 가능하다
사운드 데이터는 시간에 따른 음향을 나타내는 1차언의 배열로 표현 가능하다
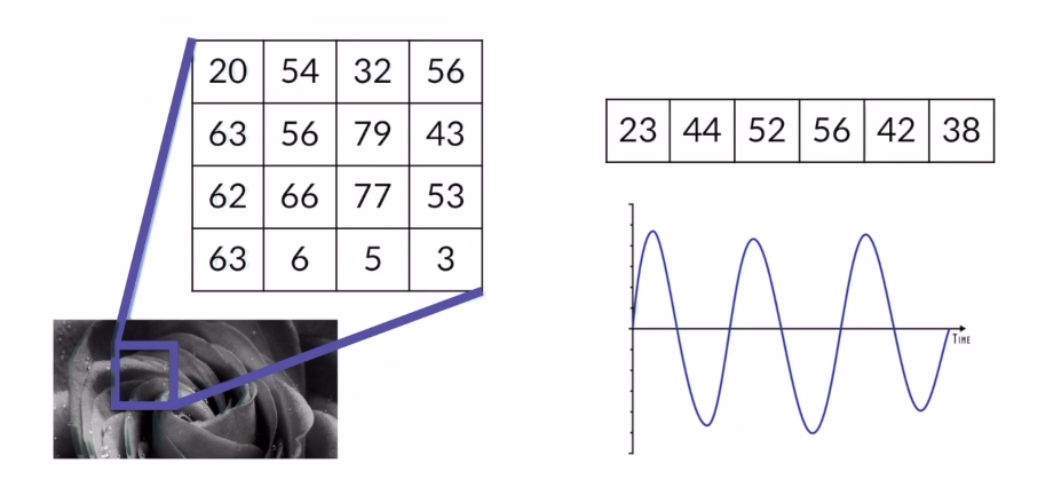
이처럼 실생활에서 사용되는 많은 데이터들이 배열로 표현될 수 있기 때문에 데이터를 처리하기 위해서는 결국 배열(array)을 효과적으로 저장하고 가공하는 절차가 필수적이다.
그리고 numpy는 list에 비해 빠른 연산을 지원하고 메모리를 효율적으로 사용한다.
2. 배열(array) 만들기
1) 다양한 형태의 array 만들기
# 리스트로 표현
list(range(5)) # [ 0 1 2 3 4 ]
# numpy 사용 (1차원, 정수형)
import numpy as np
np.array([1,2,3,4,5]) # array([1,2,3,4,5])
# list로부터 다양한 형태의 array를 만들 수 있다.
np.array([3, 1.4, 2, 3, 4]) # array([3. , 1.4, 2. , 3. , 4. ])
# 2차원 데이터
np.array([[1, 2],
[3, 4]])
# 실수형
np.array([1,2,3,4], dtype='float') # array([1., 2., 3., 4.])
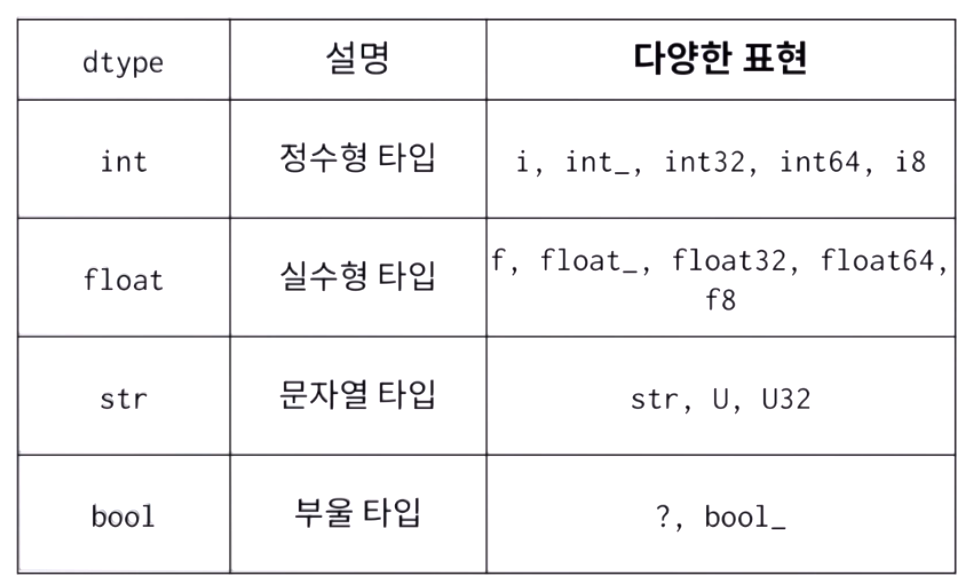
# 배열 데이터 타입 (dtype)
: Python List와 다르게 array는 단일타입으로 구성됨
→ 리스트의 경우, [ 정수형, Boolean(T/F), 실수형, 문자형 ] 다같이 들어갈 수 있지만
→ Array의 경우, 데이터타입을 하나로 지정해서 들어가게 된다.
2) numpy의 내장함수를 통한 생성
np.zeros(5, dtype=int)
# array([0, 0, 0, 0, 0])
np.ones((3,5), dtype=float)
# array([[1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1.]])
np.arrange(0,20,2) # (start, end, step)
# array([0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
np.linspace(0, 1, 5)
# array([0., 0.25, 0.5, 0.75, 1.])# Numpy library
- np.array : 배열 생성
- np.zeros : 0이 들어있는 배열 생성
- np.ones : 1이 들어있는 배열 생성
- np.empty : 초기화가 없는 값으로 배열 반환
- np.arrange(n) : 배열 버전의 range 함수
- np.random : 다양한 난수가 들어있는 배열 생성
3) 난수로 채워진 배열 만들기 - .random
np.random.random((2,2))
# array([[0.30986539, 0.85893508],
# [0.8915012, 0.19304196]])
np.random.normal(0, 1, (2,2)) # mean=0, str=1인 정규분포 데이터 (2,2)
# array([[ 0.44050683, 0.04912487],
# [-1.67023947, -0.70982067]])
np.random.randint(0, 10, (2,2)) # randint(a,b) : a~b까지 random하게
# array([[3, 9],
# [3,2]])
3. 배열(array)의 속성
아래 코드를 통해서 array의 출력해보고 그 속성을 파악해보자.
1) ndim, shape, size, dtype
# (3,4) size의 array 생성
x2 = np.random.randint(10, size=(3,4))
# array([[2, 2, 9, 0],
# [4, 2, 1, 0],
# [1, 8, 7, 3]])
# array의 차원(dimension)
x2.ndim # 2
# array의 shape(모양)
x2.shape # (3,4)
# array 내 원소가 얼마만큼 들어있는지(size)
x2.size # 12
# array의 dtype
x2.dtype # dtype('int64')2) 인덱싱(Indexing)
# 인덱스로 값을 찾아낼 수 있다.
x = np.arange(7) # x = [0 1 2 3 4 5 6]
x[3] # 3
x[7] # IndexError : index 7 is out of bounds
# array 내 값 변경
x[0] = 10 # array([10, 1, 2, 3, 4, 5, 6]3) 슬라이싱(Slicing)
x = np.arange(7) # x = [ 0 1 2 3 4 5 6 ]
# [start, end] : start부터 end-1까지 추출
x[1:4] # array([1, 2, 3])
# start부터 뒤로 모든 원소
x[1:] # array([1, 2, 3, 4, 5, 6]
# end 이전의 모든 원소
x[:4] # array([0, 1, 2, 3])
# [, , step]
x[::2] # array([0, 2, 4, 6])4) array 생성 예제
import numpy as np
print("2차원 array")
matrix = np.arrange(1,16).reshape(3,5) # 1부터 15까지 들어오는 (3,5) size array
print(matrix) # [[ 1 2 3 4 5]
# [ 6 7 8 9 10]
# [11 12 13 14 15]]
# Q1. matrix의 자료형을 출력해보세요.
print(type(matrix)) # <class 'numpy.ndarray'>
# Q2. matrix의 차원을 출력해보세요.
print(matrix.ndim) # 2
# Q3. matrix의 모양을 출력해보세요.
print(matrix.shape) # (3, 5)
# Q4. matrix의 크기를 출력해보세요.
print(matrix.size) # 15
# Q5. matrix의 dtype(data type)을 출력해보세요.
print(matrix.dtype) # int64
# Q6. matrix의 (2,3) 인덱스의 요소를 출력해보세요.
print(matrix[2,3]) # 14
# Q7. matrix의 행은 인덱스 0부터 인덱스 1까지, 열은 인덱스 1부터 인덱스 3까지 출력해보세요.
print(matrix[0:2,1:4]) # [[2 3 4]
# [7 8 9]]
반응형
4) Reshape (array의 shape 변경)
array에는 reshape(=shape를 변경)할 수 있는 특성이 있으며, 예제를 통해 학습하자
# 0 ~ 7까지의 숫자로 이루어진 배열 생성
x = np.arange(8)
x.shape # (8,)
# x의 shape 변경
x2 = x.reshape((2,4)) # array([[0, 1, 2, 3],
# [4, 5, 6, 7]])
x2.shape # (2, 4)5) concatenate (=array를 이어 붙인고 분리)
concatenate() 함수를 이용해서 array를 이어 붙일 수 있다.
# x, y라는 array 생성하고 concatenate
x = np.array([0, 1, 2])
y = np.array([3, 4, 5])
np.concatenate([x, y]) # array([0, 1, 2, 3, 4, 5])
np.concatenate()는 axis 축을 기준으로 이어붙일 수도 있다.
# matrix를 생성하고 'x=0' 축을 기준으로 세로로 이어 붙인다. (axis = 0)
matrix = np.arange(4).reshape(2, 2) # [[ 0, 1 ]
# [ 2, 3 ]
np.concatenate([matrix, matrix], axis=0) # [[ 0, 1 ]
# [ 2, 3 ]
# [ 0, 1 ]
# [ 2, 3 ]]
# 'y=o' 축을 기준으로 가로로 이어 붙일 수 있다. (axis = 1)
np.concatenate([matrix, matrix], axis=1) # [[ 0, 1, 0, 1 ]]
# [ 2, 3, 2, 3 ]]
np.split()를 통해 axis 축을 기준으로 array를 나눌 수도 있다.
# matrix를 생성하고 'axis=0'을 기준으로 array를 나눈다
matrix = np.arrage(16).reshape(4, 4) # [[ 0, 1, 2, 3 ]
# [ 4, 5, 6, 7 ]
# [ 8, 9, 10, 11 ]
# [ 12, 13, 14, 15 ]
# matrix를 index 3을 기준으로 나누고 위는 upper, 아래는 lower
upper, lower = np.split(matrix, [3], axis=0) # [[ 0, 1, 2, 3 ]
# [ 4, 5, 6, 7 ]
# [ 8, 9, 10, 11 ]] → upper
# [[ 12, 13, 14, 15 ]] → lower
4. Numpy 연산 & Broadcasting
1) Numpy 연산
Python에서의 몇가지 연산은 느리게 수행된다. 하지만, 연산을 수행하는 array의 크기가 커질수록 수행시간이 꽤 느려진다.
Numpy는 이러한 고차원의 연산을 compile된 루틴으로 수행하여 훨씬 더 빠른 속도로 연산이 가능하다. 따라서 array는 기본 연산( +, -, *, / )를 지원한다.
# numpy 기본 연산 (1차원 array)
x = np.arrage(4) # array([0, 1, 2, 3])
x + 5 # array([5, 6, 7, 8])
x - 5 # array([-5, -4, -3, -2])
x * 5 # array([0, 5, 10, 15])
x / 5 # array([0, 0.2, 0.4, 0.6])
# 다차원 행렬에서도 연산 가능
x = np.arange(4).reshape((2, 2)) # [[0, 1]
# [2, 3]]
y = np.random.randint(10, size=(2, 2)) # [[1, 6]
# [4, 2]]
x + y # array([[1, 7],
# [6, 5]])
x - y # array([[-1, -5],
# [-2, 1]])2) Broadcasting (브로드캐스팅)
array의 shape이 다른 array끼리의 연산하는 것을 Broadcasting(브로드캐스팅)이라고 하며, 이는 Numpy로 생성한 배열의 크기가 다를 경우 사용된다.

3) Numpy 연산의 통계를 볼 수 있는 집계함수
집계란, 데이터에 대한 요약 통계를 의미하며 Numpy 연산의 결과를 확인할 수 있다.
→ sum, min, max, mean, std
→ 마스킹 연산 : True, False array를 통해 특정 값을 뽑아내는 방법
x = np.arange(8).reshape((2, 4)) # [ 0 1 2 3 ]
# [ 4 5 6 7 ]
# 합계
np.sum(x) # 28
# axix=0(가로)을 기준으로 합계
np.sum(x, axis=0) # array([4, 6, 8, 10])
# axis=1(세로)를 기준으로 합계
np.sum(x, axis=1) # array([6, 22])
# 최솟값
np.min(x) # 0
# 최댓값
np.max(x) # 7
# 평균값
np.mean(x) # 3.5
# 표준편차
np.std(x)
# 마스킹 연산
x = np.arange(5) # array([0, 1, 2, 3, 4])
x < 3 # array([True, True, True, False, False])
x > 5 # array([False, False, False, False, False])
x[x < 3] # array([0, 1, 2])
→ x[ x < 3 ]
: 인덱스 안에 T/F가 담겨있는 Array를 넣으면, True인 값들만 출력된다.
위에서는 x가 3보다 작은 값들만 출력됨
4) numpy library에서 자주 사용되는 함수
- np.array : 배열 생성
- np.zeros : 0이 들어있는 배열 생성
- np.ones : 1이 들어있는 배열 생성
- np.empty : 초기화되어 있지 않은 값이 들어있는 배열 반환
- np.arange(n) : 배열 버전의 range 함수
5. Numpy 예제 - 양치기소년이 거짓말한 횟수는?
오늘로 일한지 100일이 된 양치기 소년이 100일동안 거짓말을 했는지 안 했는지 기록한 데이터(daily_liar_data)가 주어지고, 이를 기반으로 양치기 소년이 100일간 얼마나 거짓말을 했는지 출력하시오.
(진실 : 1, 거짓 : 0)
import numpy as np
daily_liar_data = [0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1,
0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1,
0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0,
0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0]
# 주어진 데이터(리스트형식)을 array 형식으로 변환
x = np.array(daily_liar_data)
# x < 1 조건을 주어 거짓말(0)한 횟수를 len()를 통해 출력
print(len(x[x<1])) # 72