
Machine Learning/Basic of Python (Colab)
쉽게 이해하는 파이썬 numpy, pandas 정리 & 예제!
Derrick
2024. 3. 24. 22:37
728x90
반응형
파이썬/데이터분석에서 꼭 알아야 하는
numpy, pandas 패키지에 대해 쉽게 이해해보자

1. Numpy
- C로 구현된 숫자 관련된 자료형을 처리할 수 있는 함수의 집합
- python의 성능 문제를 대부분 상쇄해줄 수 있는 패키지
1) 배열 기초
- numpy.array(list.dtype)의 구조로 배열을 만들 수 있음
→ 파이썬으로 list를 먼저 만들고, numpy.array를 통해서 변환해주는 개념
- 함수를 이용하여 배열 만들기
→ 규모가 큰 배열의 경우에는 numpy에 내장된 함수를 사용하여 처음부터 배열을 생성하는 것이 효율적
- 대표적인 함수
→ zeros, ones, full, arrange, linspace, rando.random, random.normal 등
2차원의 배열인 경우, X[i, j]는 i행 j열에 있는 요소를 나타낸다.
- 슬라이싱은 X[start:stop:step]의 방식으로 수행하며, 값이 입력되지 않으면 start=0, stop=차원크기, step=1로 설정됨
- copy() 함수를 활용하면 배열의 사본을 생성할 수 있다.
2) numpy 사용법 (1)
numpy의 기본 사용법으로 먼저 [1,2,3,4,5] 라는 리스트를 넣고, 뒤에 데이터타입(dtype)은 float 32bit으로 설정
numpy에서 integer는 다양한 형태로 쓰일 수 있다. int8(8bit), int32, 64 등이고 해당 수치만큼 메모리에서 차지하는 bit수가 된다. 하지만, 위의 예시와 같이 int8의 경우는 표현범위가 128까지이므로 500의 수를 넣으면 Overflow 현상이 발생하여, '-12'가 저장된 것을 알 수 있다. → 이때 500을 저장할려면 적어도 int16은 되어야 한다.
이 경우는 반대로, 64bit의 표현 범위보다 상대적으로 너무 작은 수(1)만 저장한다면 공간 낭비가 발생할 수 있다.
List는 [i][j] 형식으로만 접근이 가능하지만,
Numpy array는 [i][j] 또는 [i, j]로 접근이 가능하다.
3) numpy 사용법 (2)
# 원소를 모두 0으로 초기화된 배열 생성
# 1로 초기화된 배열 생성법
# Range와 Step을 넣어서 배열 생성
# Range와 Size를 넣어서 배열 생성
0~5 사이의 수를 size(30)만큼 쪼개기
# 행열의 형태를 바꾸는 법 (.reshape)

주의할 것은 reshape의 곱셈 결과가 arrange의 크기와 동일해야 한다!
4) numpy 특징 - 유니버셜
기본적으로 Python은 수많은 연산을 처리하기에 적절한 언어는 아니지만, numpy의 유니버셜 함수를 사용하면 더 빨리 연산을 수행할 수 있다.

위와 같이, 1억 개의 element로 구성된 두 배열의 합을 구하는 문제가 있다면, for문을 통해서 구하는 것과 numpy 유니버셜 함수를 통해서 연산을 하면 훨씬 더 빠르게 수행이 가능하다는 것을 알 수 있다.
5) numpy 특징 - broadcasting
numpy의 또다른 특징인 브로드캐스팅(broadcasting)은 다른 크기의 배열에 이항 연산 함수를 적용할 수 있다. (원래는 연산이 안되는 것이 정상) 동일한 크기의 배열에서 이항 연산은 요소 단위로 수행되며, 큰 차원의 벡터 크기에 맞게 작은 차원의 벡터가 확장된다.

1) 두 배열의 차원 수가 다르면 더 작은 수의 차원을 가진 배열 앞쪽을 1로 채움
2) 두 배열의 형상이 어떠한 차원에서도 일치하지 않으면, 해당 차원의 형상이 1인 배열이 다른 형상과 일치하도록 늘림
3) 임의의 차원에서 크기가 일치하지 않고 1도 아니라면 오류 발생!
반응형
2. Pandas
- 데이터분석에서 가장 많이 사용되는 필터, 병합, 슬라이싱 등의 기능 제공!
- 대부분의 python을 이용한 데이터 분석 프로젝트에서 사용
Pandas에는 2가지 개념이 있다. Series와 DataFrame.

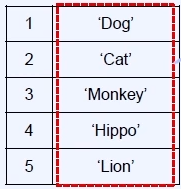
위에 생성된 Series는 딕셔너리로 생성하거나 index를 포함한 list를 2개를 넣어서 만들 수 있고, Series는 벡터에 대응한다.
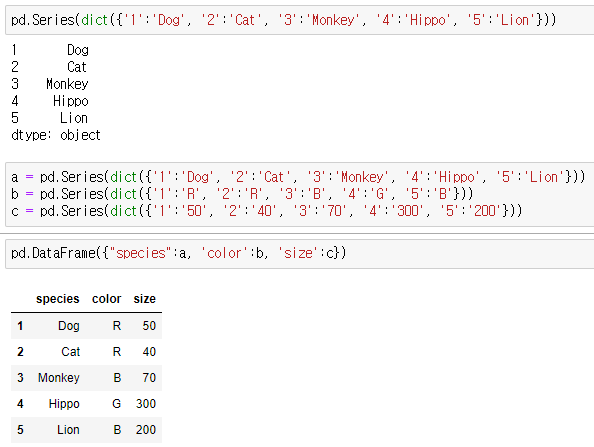
위와 같이 DataFrame은 Series의 집합인 행렬에 대응한다.
1) Indexer
DataFrame에 index로 접근하는 방법은 'iloc' 와 'loc' 로 2가지 방법이 있다.
- loc : 명시적인 인덱스를 참조하여 인덱싱과 슬라이싱
→ 조건을 주거나 정확한 index명을 참고
- iloc : 묵시적인 인덱스를 참조하는 인덱싱과 슬라이싱
→ index 수치로 참조
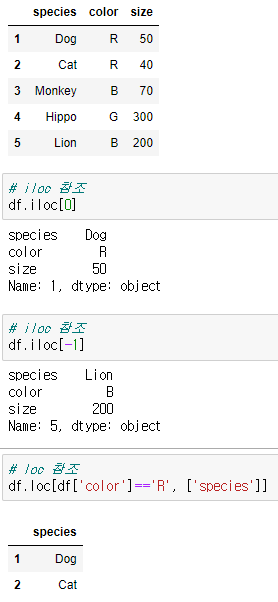
df.iloc[0] : df 내 0번째 index에 해당하는 데이터 출력
df.loc[df['color']=='R', ['species']] : color가 'R'인 데이터 중, 'species'에 해당되는 데이터
2) Column 선택
- DataFrame은 Key로도 접근 가능하고, 속성으로도 접근이 가능하다.
- Data의 속성으로 보는 경우, 속성이 다른 메서드와 이름이 겹치는 경우 사용이 불가하다.
→ 아래의 예제에서는 df 내 'size'라는 feature가 있기 때문에 df.size으로 속성에 접근되는 것이 아니라, df의 size를 구하는 메서드로 수행된다.

- data['column']은 data를 딕셔너리로 보고 Key로 접근
- data.column은 column을 dataframe(df)의 속성으로 보고 접근
3) 자료형 다루기 (series 형태반환)
- series.values : Series의 값을 반환(ndarray)
- series.to_list() : Series를 List 형태로 반환
- series.to_dict() : Series를 Dict 형태로 반환

4) 중복 제거 및 카운트 함수
- drop_duplicates(column, keep)
→ column : 중복을 제거하고자 하는 기준 컬럼
→ keep : 중복을 제거한 뒤 남길 행의 위치
- series.unique() : series 내의 유일한 값만 남김
- series.value_counts() : series 내의 유일한 값의 빈도
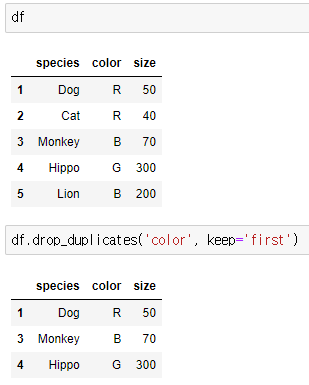
위의 예시에서는 df 내 'color'이 중복되는 데이터 중, 첫번째(first) 데이터만 남기고 중복 데이터는 제거
5) merge (병합)
SQL의 JOIN과 유사한 기능을 하는 함수
→ Inner, Left, Outer 등 지원

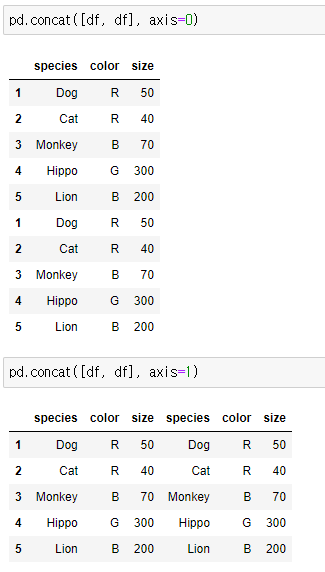
6) concat (이어붙이기)
'concat'은 2개의 DataFrame을 이어 붙이는 함수로, 행 단위 결합과 열 단위 결합이 가능하다.
→ 'axis = 0'이면, x축(column)을 기준으로 아래로 이어붙이고
→ 'axis = 1'이면, y축(row)을 기준으로 오른쪽으로 이어붙인다.
학습 참고 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE