(머신러닝) Feature Engineering의 종류와 기법 기초 정리!
728x90
반응형
데이터 분석을 할 때, 다양하고 많은 Feature(독립 변수)에 대해 모델에 데이터를 넣기 전에 잘 학습되어서 성능이 잘 나오도록 하는 작업을 'Feature Engineering'이라고 한다. 원하는 Feature를 데이터 input으로 사용할 수 있는 형태로 바꾸는 작업부터 종류가 여러가지 있고 해당 목적에 맞는 기법도 다양하다.
이번 게시물을 통해서 특정 기법에 대해 자세히 학습하는 것보다 'Feature Engineering'에 대한 전반적인 이해와 그 종류를 살펴보자.
Feature Engineering은 왜 필요한가?
어떤 종류의 도구들과 기법들이 있을까?

1. 인코딩 (Encoding)
- 컴퓨터는 정보에 대한 개념이 없기 때문에 각 데이터를 컴퓨터가 인식할 수 있도록 해줘야 한다.
- 문자를 숫자로 변환하고, 카테고리의 경우에도 모두 숫자로 바꿔줘야 한다.
- 인코딩에는 다양한 방법이 있지만, 가장 흔히 사용되는 방법은 'Label Encoding'과 'One-hot Encoding'이다.
# Label Encoding
: 알파벳(한글) 순서대로 숫자(Index) 할당하여 그 정렬된 순서 기준으로 번호를 매긴다는 의미
→ Label Encoding은 문자열값을 간단히 숫자형 카테고리값으로 변환하기 때문에 몇가지 ML알고리즘에 이를 적용하면 예측 성능이 떨어지는 경우가 종종 있다. 따라서 Label encoding은 선형 회귀나 ML알고리즘에는 적용하지 않는다.
→ 주로 트리 계열의 ML 알고리즘에서 사용됨
# One-hot Encoding
: 등장하는 데이터의 사전을 만들고, 이진수와 유사하게 표현
즉, Feature 값의 유형에 따라 새로운 Feature를 추가해서 고유 값에 해당하는 칼럼에만 '1'을 표시하고 나머지 칼럼에는 '0'을 표시하는 방식이다.
→ One-hot 인코딩은 sklearn에서 'OneHotEncoder' 클래스, pandas에서 'get_dummies()'로 생성할 수 있다.
→ 이 때, 모든 문자열 값이 숫자형 값으로 변환되므로, 입력값으로 2차원 데이터가 필요하다
2. 이산화 (Discrete)
- 연속형 변수들은 왜도가 높거나 정규분포가 아닐 가능성이 높다
→ 왜도가 높다는 의미는 데이터가 한쪽에 치우져있다는 의미 (음수는 왼쪽, 양수면 오른쪽으로)
- 데이터에 따라 변수의 값들을 단순한 몇 개의 그룹(Bin)으로 나누는게 효율적
- 이산화를 적용하기 위해서는 변수에 결측치가 존재하지 않아야 한다
- 왜도가 작은 경우, '|왜도| < 1'의 경우 Equal Width Binning(동일 너비 분할) 사용
→ 왜도가 작다 = 데이터 쏠림이 작은 경우
- 왜도가 큰 경우, '|왜도| > 1'의 경우 Equal Frequency Binning(동일 빈도 분할) 사용
→ 왜도가 크다 = 데이터 쏠림이 큰 경우. 데이터의 분포를 평평하게 만들 수 있다.
3. Scaling (스케일링)
- 확률에서의 연산은 곱셈 연산이 많기 때문에 값의 범위가 클 경우(ex, -10000~100000000), 값이 너무 커져서 무슨 연산을 해도 연산 결과가 발산하게 된다.
- 더불어 연산속도도 느려지고 메모리를 많이 차지하게 된다.
- 다양한 문제가 있지만, 주된 목적은 연산 결과가 발산하는 것을 방지하기 위해 scaling을 한다.
# 대표적인 Scaling 기법
: MinMax Scaler, MaxABS Scaler, Standard Scaler, Robust Scaler
→ 각 용도에 맞게 Scaling을 할 수 있어야 한다.
반응형
4. Transforming (변환)
Transforming(변환)은 가지고 있는 데이터셋의 분포를 변화시키는 작업을 말한다.
- Linear regression 또는 Gaussian Naive Bayes와 같은 ML 알고리즘들은 연속형 변수에 대해 정규 분포를 가정하는 경우가 많다.
- 정규분포가 아닌 변수들을 Power Transforming을 사용하여 정규분포 또는 정규분포에 가까운 데이터로 변환이 가능하다.
- 변수에 0과 음수가 없는 경우 → Box-Cox Transforming 적용
- 변수에 0과 음수가 포함된 경우 → YeoJohnson Transforming 적용
5. Extracting (추출) ***
Feature Engineering의 꽃인 'Extracting(추출)'은 시계열 데이터에서 특징을 뽑아내는데 필수적!
- 시계열 데이터에서 특징 변수 추출
→ 날짜형 데이터에서 문자열데이터로 이루어진 년, 월, 일, 요일, 주말여부, 휴일여부 등을 추출
- 구간별 평균(moving average), 합계, 기울기 등을 구하기
→ ex) 7일간 평균, 합계, 기울기 추출을 통한 feature trend를 학습데이터에 추가
- Convolution으로 데이터를 원하는 형태로 추출하기
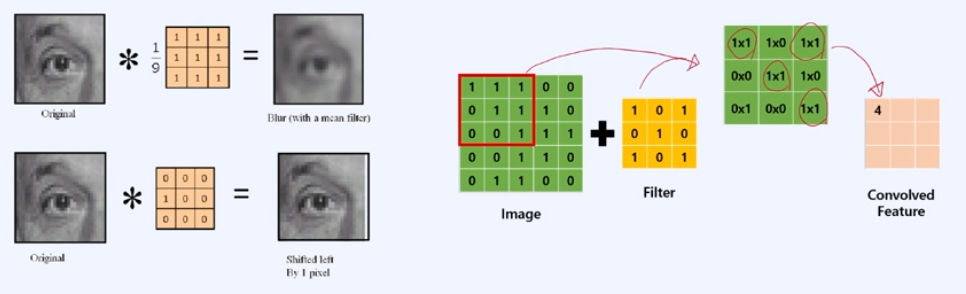
Extracting 작업을 통해서 Feature들의 전반적인 Trend를 확인하고, 필요한 Feature들을 뽑아서 데이터에 정보를 더 만들어서 넣어주는 것이 가능해진다.
→ 데이터의 칼럼들이 많으면, Feature들을 줄이기 위해 'Feature Selection' 작업도 하지만 반대로 Feature가 매우 적을 경우에는 관련된 Feature를 추가해주는 작업도 필요하다.
학습 참고 : 50개 프로제트로 완벽하게 끝내는 머신러닝 SIGNATURE (패스트캠퍼스)
'Machine Learning > 데이터 분석 이론과 기초' 카테고리의 다른 글
| (머신러닝) Supervised vs Unsupervised Learning 간단 정리 (0) | 2024.02.27 |
|---|---|
| (머신러닝) Data Cleaning과 Sampling 샘플링 기법 총정리! (1) | 2024.02.27 |
| (머신러닝) Feature Selection는 무엇이고 왜 꼭 알아야 하는 걸까? (1) | 2024.02.26 |
| 머신러닝(ML)으로 현업에서 해결할 수 있는 문제 유형 총 정리! (1) | 2024.02.25 |
| 현업 데이터 분석의 오해와 진실 - 실패와 성공한 사례 분석 (0) | 2024.02.23 |




댓글